📝 Paper Summary
RL-based Agentic Reasoning
Tool-use post-training
Self-evolving Agentic reasoning
ARTIST unifies agentic reasoning and tool integration by training LLMs with Group Relative Policy Optimization (GRPO) to autonomously interleave thoughts, tool calls, and environment interactions without step-level supervision.
Core Problem
LLMs rely on static internal knowledge, leading to hallucinations in knowledge-intensive tasks and failures in complex computations, while existing tool-use methods (prompting/SFT) are brittle and labor-intensive.
Why it matters:
- Purely text-based reasoning struggles with domain-specific problems requiring precise calculation or up-to-date facts
- Hand-crafted prompts and heuristics for tool use do not generalize to unseen scenarios or recover from tool failures
- Existing RL methods for reasoning often neglect the dynamic integration of external resources like code execution or web search
Concrete Example:
In a Math Olympiad problem requiring a complex integral, a standard RL-trained model relies on text-based reasoning and compounds symbolic errors. In contrast, ARTIST generates Python code, invokes a SymPy library via an interpreter, and seamlessly integrates the precise computation into its reasoning chain.
Key Novelty
ARTIST (Agentic Reasoning and Tool Integration in Self-Improving Transformers)
- Treats tool usage and environment interaction as first-class operations interleaved directly within the reasoning chain (alternating <think>, <tool_name>, and <output> tags)
- Uses Group Relative Policy Optimization (GRPO) to learn tool-use strategies from outcome-based rewards alone, avoiding the need for dense step-level supervision
- employs a loss masking strategy where tool outputs are masked during training, ensuring the model optimizes its reasoning and queries rather than imitating deterministic tool responses
Architecture
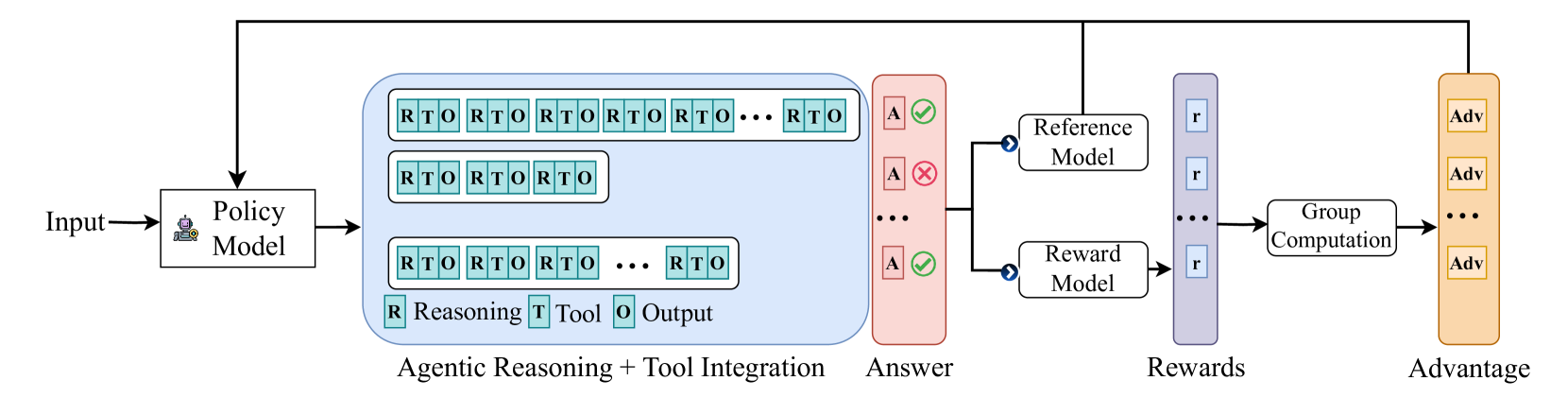
The ARTIST methodology illustrating the iterative rollout process used during training and inference.
Evaluation Highlights
- Achieves up to 22% absolute improvement over base models on mathematical reasoning benchmarks
- More than doubles the accuracy of base and prompt-based models on the Tau-bench multi-turn function calling benchmark
- Surpasses GPT-4o and DeepSeek-R1 on challenging math benchmarks including AMC, AIME, and Olympiad Bench
Breakthrough Assessment
9/10
Significantly advances agentic AI by successfully applying efficient RL (GRPO) to multi-step tool use, demonstrating that models can self-learn *when* and *how* to use tools without expensive human annotations.