📝 Paper Summary
Agentic AI
Web Agents
ASearcher unlocks expert-level search intelligence by enabling extremely long-horizon tool use (100+ turns) via fully asynchronous RL and high-quality synthetic data generation.
Core Problem
Existing online RL for search agents is limited by small turn limits (≤10), preventing complex strategy learning, and suffers from a lack of high-quality, challenging training data.
Why it matters:
- Complex real-world queries often require resolving conflicting information and deep exploration beyond just a few search steps
- Batch generation RL systems are inefficient with long trajectories due to blocking, causing GPU idle time
- Open-source agents lag behind proprietary models in 'Search Intelligence'—the ability to resolve ambiguity and verify conclusions
Concrete Example:
For a GAIA question about medals won by China in the 2012 Olympics, standard agents fail due to conflicting online reports (38 vs 39 gold medals). They cannot perform the deep verification needed to identify doping disqualifications as the root cause of the conflict.
Key Novelty
ASearcher: Fully Asynchronous Agentic RL
- Decouples trajectory execution from model updates, allowing extremely long horizons (e.g., 128 turns) without the 'straggler problem' where one long trajectory blocks the whole batch
- Uses a self-evolving data synthesis agent that iteratively 'fuzzes' queries (adds ambiguity) and 'injects' facts to create challenging, grounded training data from seed questions
Architecture
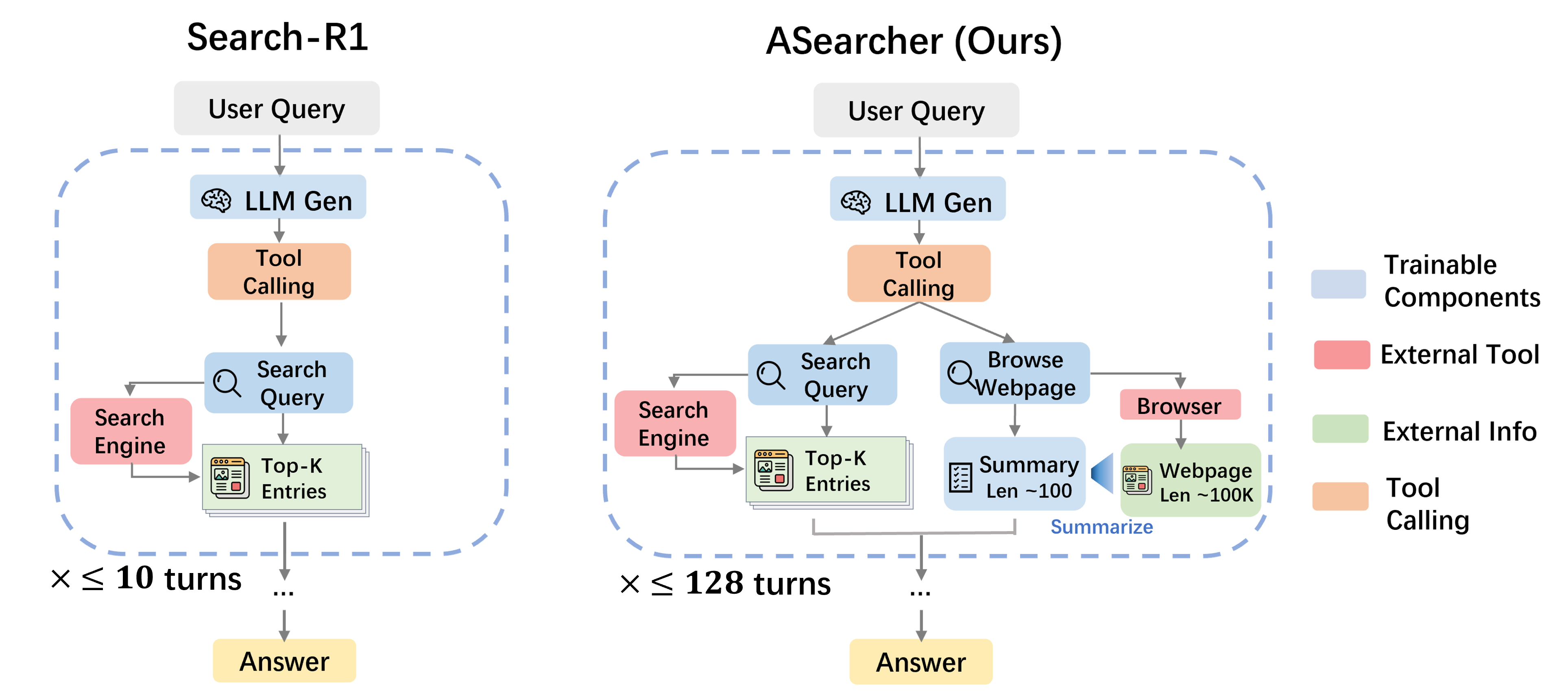
Figure 2 shows the agent loop (Search/Browser tools); Figure 7 shows the Fully Asynchronous RL System vs. One-step-off RL
Evaluation Highlights
- +78.0% improvement on xBench-DeepSearch and +34.3% on GAIA for the QwQ-32B based agent after RL training
- Achieves Avg@4 score of 58.7 on GAIA and 51.1 on xBench-DeepSearch, surpassing existing open-source 32B agents
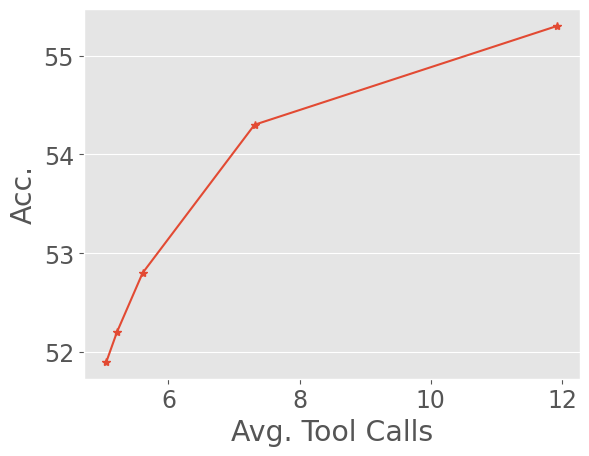
- Demonstrates extreme long-horizon capabilities with tool calls exceeding 100 turns and output tokens exceeding 400k during training
Breakthrough Assessment
9/10
Significantly pushes the boundary of open-source agentic search by successfully training effective 100+ turn trajectories, addressing both the system efficiency bottleneck and the data scarcity problem.