📝 Paper Summary
Foundation Models
Agentic AI
Reasoning
GLM-4.5 is an open-source Mixture-of-Experts model that unifies agentic, reasoning, and coding capabilities through a hybrid reasoning approach and multi-stage post-training with verifiable rewards.
Core Problem
Achieving unified mastery of complex reasoning, coding, and agentic interaction in a single open-source model remains elusive, as most open models trail proprietary leaders (like o1/o3 or Claude 3.5 Sonnet) in these specific ARC domains.
Why it matters:
- Proprietary models dominate high-stakes tasks like mathematical reasoning and software engineering, limiting open research access.
- Existing open models often specialize in one area (e.g., just coding or just math) rather than acting as general problem solvers.
- Effective agentic behaviors require tight integration of reasoning with tool use, which is difficult to train without specialized feedback loops.
Concrete Example:
In web browsing tasks involving elusive, interwoven facts, standard models often fail to navigate or filter information effectively. GLM-4.5 uses a specialized data synthesis pipeline for multi-step web search to train the model to persist through difficult retrieval tasks.
Key Novelty
Unified ARC (Agentic, Reasoning, Coding) via Hybrid Reasoning
- Combines 'thinking' mode (deliberative reasoning for complex tasks) and 'direct response' mode within a single model architecture.
- Utilizes a massive post-training pipeline that iteratively distills specialized experts (Reasoning, Agent, General) back into a unified generalist model.
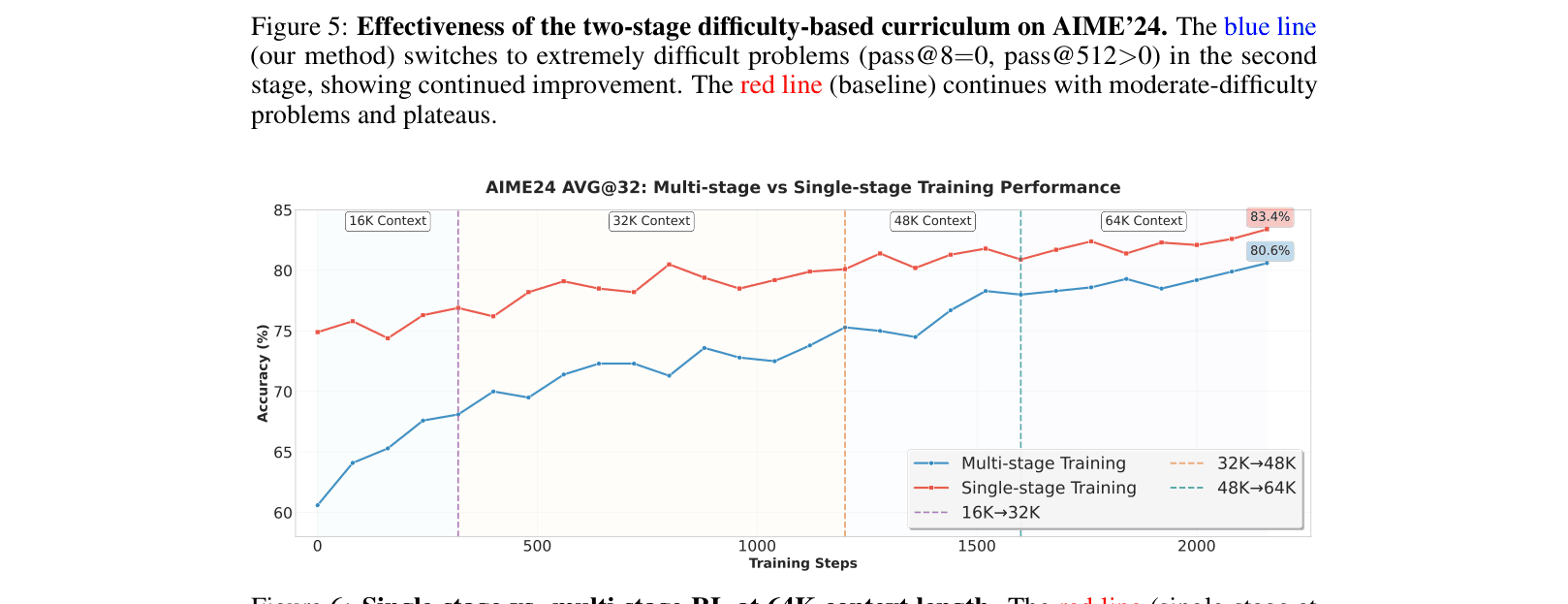
- Implements difficulty-based curriculum learning in RL, dynamically adjusting problem complexity and sampling temperature to prevent training plateaus.
Architecture

The training pipeline (Pre-training -> Mid-training) and implicitly the model structure via parameter tables.
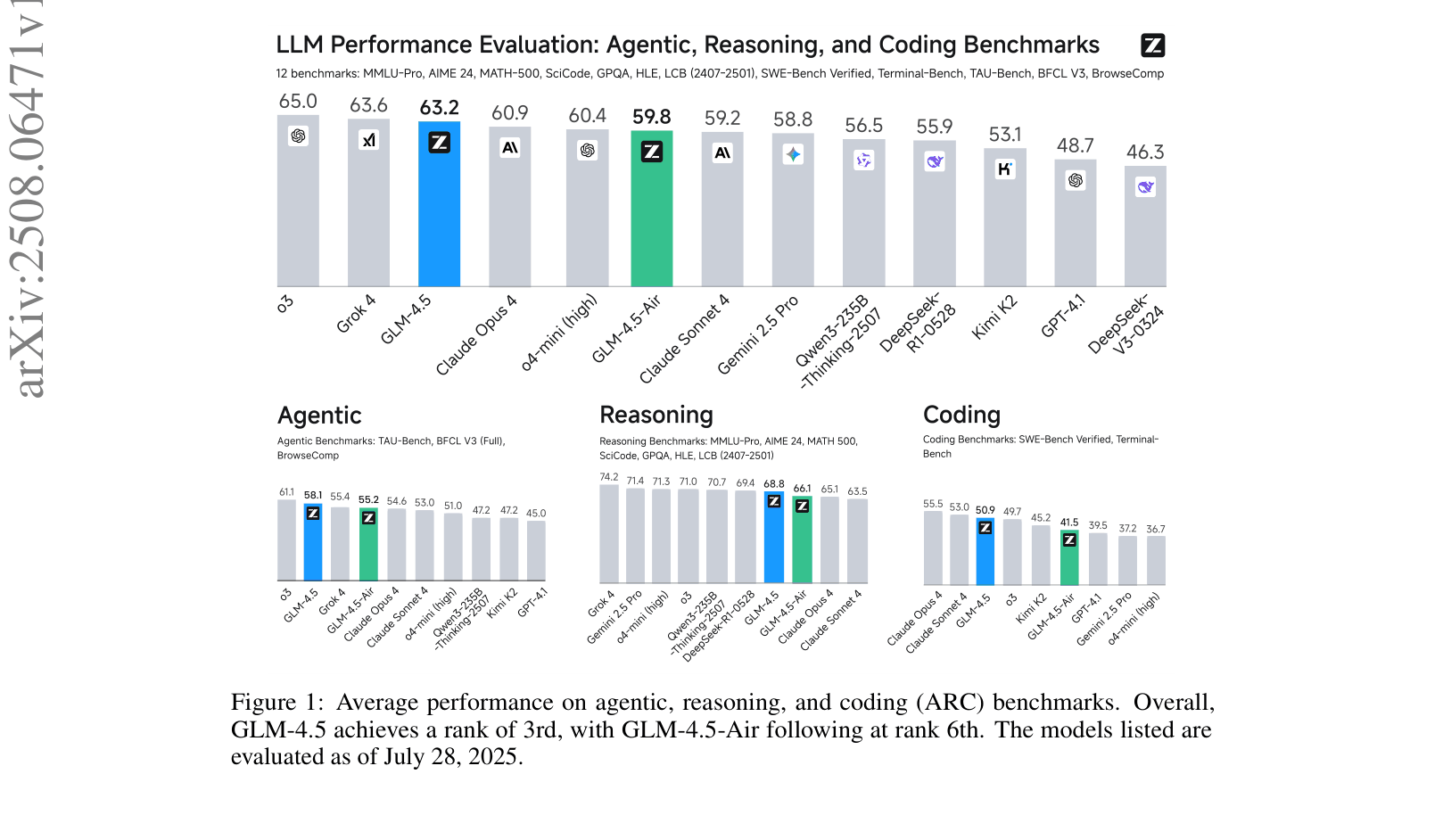
Evaluation Highlights
- Achieves 70.1% on TAU-Bench (Agentic), matching Claude Sonnet 4 performance.
- Scored 91.0% on AIME 24 (Math Reasoning), surpassing GPT-4.1 and Qwen3-235B-Thinking.
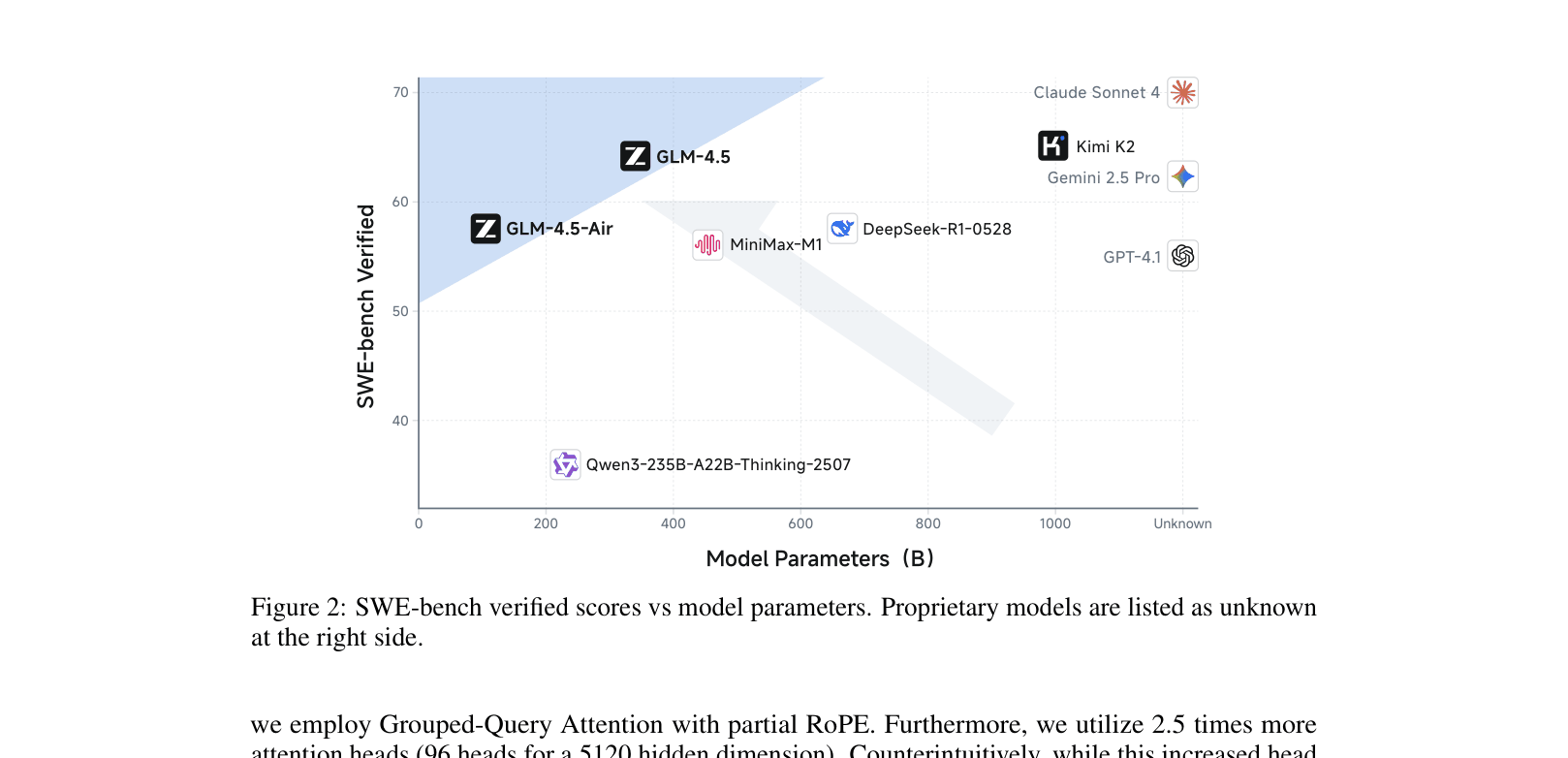
- Attains 64.2% on SWE-bench Verified (Coding), outperforming GPT-4.1 and Gemini-2.5-pro.
Breakthrough Assessment
9/10
Significant leap for open weights. Matches or beats top proprietary models (Claude Sonnet 4, GPT-4o) on key hard benchmarks (AIME, SWE-bench) with fewer parameters than competitors like Llama 405B or DeepSeek V3.