📝 Paper Summary
Small Language Models (SLMs)
Agentic AI for Science
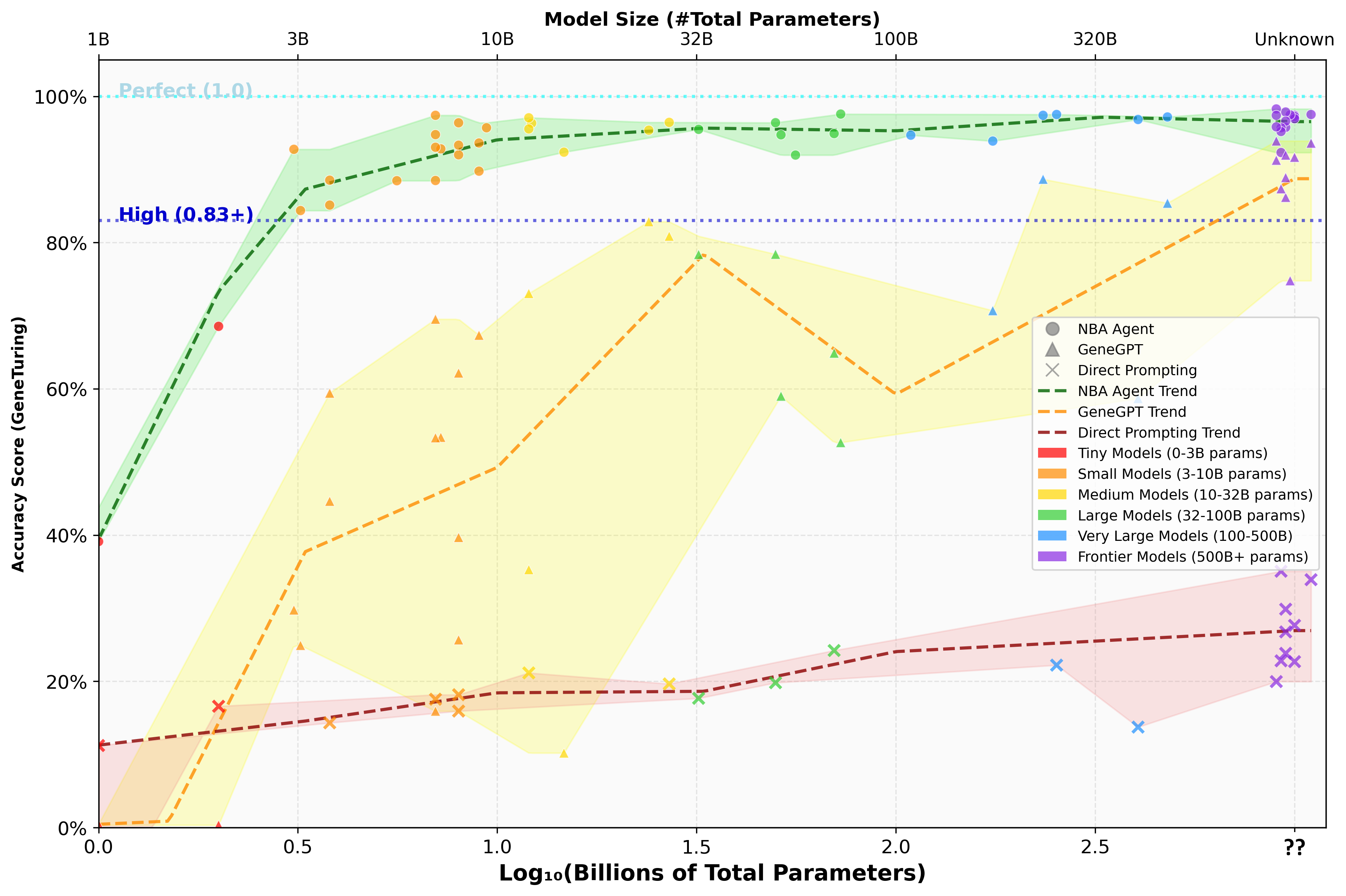
An agentic framework (NBA) that decomposes complex genomics queries enables Small Language Models (<10B parameters) to match or outperform larger models in accuracy while significantly reducing computational costs.
Core Problem
Large Language Models (LLMs) hallucinate on domain-specific genomics queries and are computationally expensive, while standard tool-augmented approaches degrade significantly when applied to smaller, more efficient models.
Why it matters:
- In genomics, precision is paramount; hallucinations compromise clinical decision-making and research outcomes
- The high cost of 100B+ parameter models limits the democratization of AI tools for resource-constrained academic and clinical environments
- Small models typically fail at complex API orchestration, executing incorrect URL constructions or failing to parse documents
Concrete Example:
When using GeneGPT's prompt with a small model (e.g., Codex/GPT-3 scale works, but smaller ones fail), the model often generates irregular behavior such as incorrect URL construction or failure to parse the returned NCBI document, leading to severe accuracy degradation.
Key Novelty
Nano Bio-Agent (NBA) Framework
- Replaces monolithic 'super-prompting' with a modular 'Divide and Conquer' agentic pipeline
- Decomposes queries into distinct sub-tasks (Classification, Plan Retrieval, Tool Execution, Parsing) to reduce the cognitive load on the SLM
- Integrates optimized programmatic functions (pure code) alongside LLM-based reasoning for robust handling of specific genomics tasks
Architecture
The sequential pipeline of the NBA framework
Evaluation Highlights
- Best model-agent combination achieves 98% accuracy on the GeneTuring benchmark, surpassing the 83% reported by GeneGPT
- Small 3-10B parameter models consistently achieve 85-97% accuracy using this framework
- Realizes 10-30× efficiency gains (FLOPs/latency) compared to conventional large model approaches
Breakthrough Assessment
8/10
Demonstrates that architectural intelligence can replace parameter scale in specialized domains, enabling local, private, and cheap deployment of high-performance genomics AI.