📝 Paper Summary
Multi-agent systems
Healthcare AI safety
TAO enhances healthcare AI safety by organizing agents into a tiered hierarchy that dynamically escalates complex cases to specialized experts, correcting errors through layered validation rather than relying on single-model capabilities.
Core Problem
Single-agent LLMs in healthcare suffer from critical safety risks like hallucinations and unaligned ethical decisions, while human oversight is not scalable for every query.
Why it matters:
- Single-agent errors (e.g., missed drug interactions) can propagate unchecked in safety-critical clinical environments
- Static guardrails fail to handle the nuance of diverse patient conditions, either over-flagging low risks or missing high-stakes scenarios
- Scalable oversight is difficult when task complexity varies wildly, making consistent human verification impractical
Concrete Example:
In a medical triage scenario, a single agent might confidently recommend a low-priority action for a high-risk patient due to missed symptoms. TAO detects the high risk or inter-agent disagreement at a lower tier and escalates it to a 'specialist' agent or human for correction.
Key Novelty
Tiered Agentic Oversight (TAO)
- Mimics clinical hierarchies (nurse → physician → specialist) by routing tasks to agents based on complexity and risk rather than using a flat multi-agent structure
- Implements a 'Boolean Escalation Flag' mechanism where agents explicitly vote to handle a case or escalate it, converting complex reasoning into a discrete routing signal
- Uses disagreement among lower-tier agents as a primary trigger for automatic escalation to higher-tier experts
Architecture
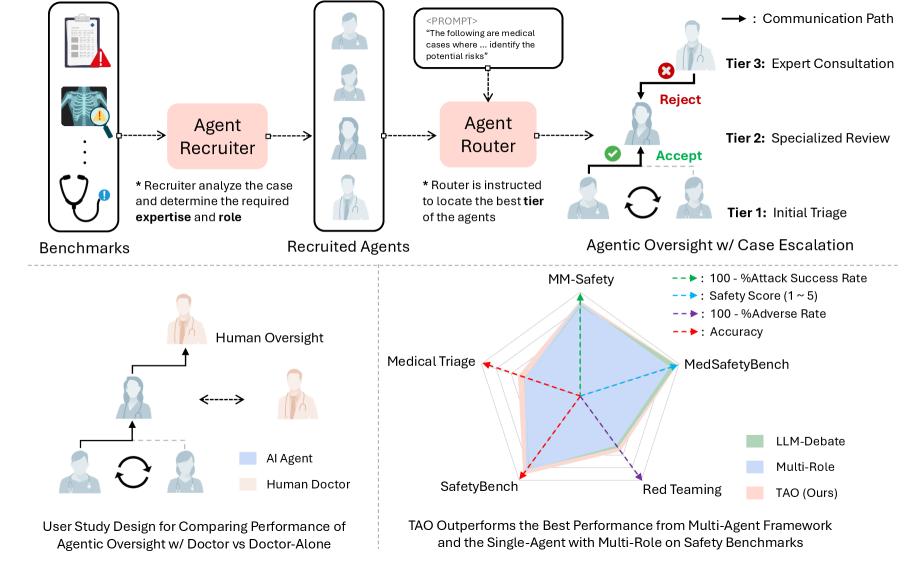
Conceptual overview of the TAO framework comparing it to standard clinical workflow.
Evaluation Highlights
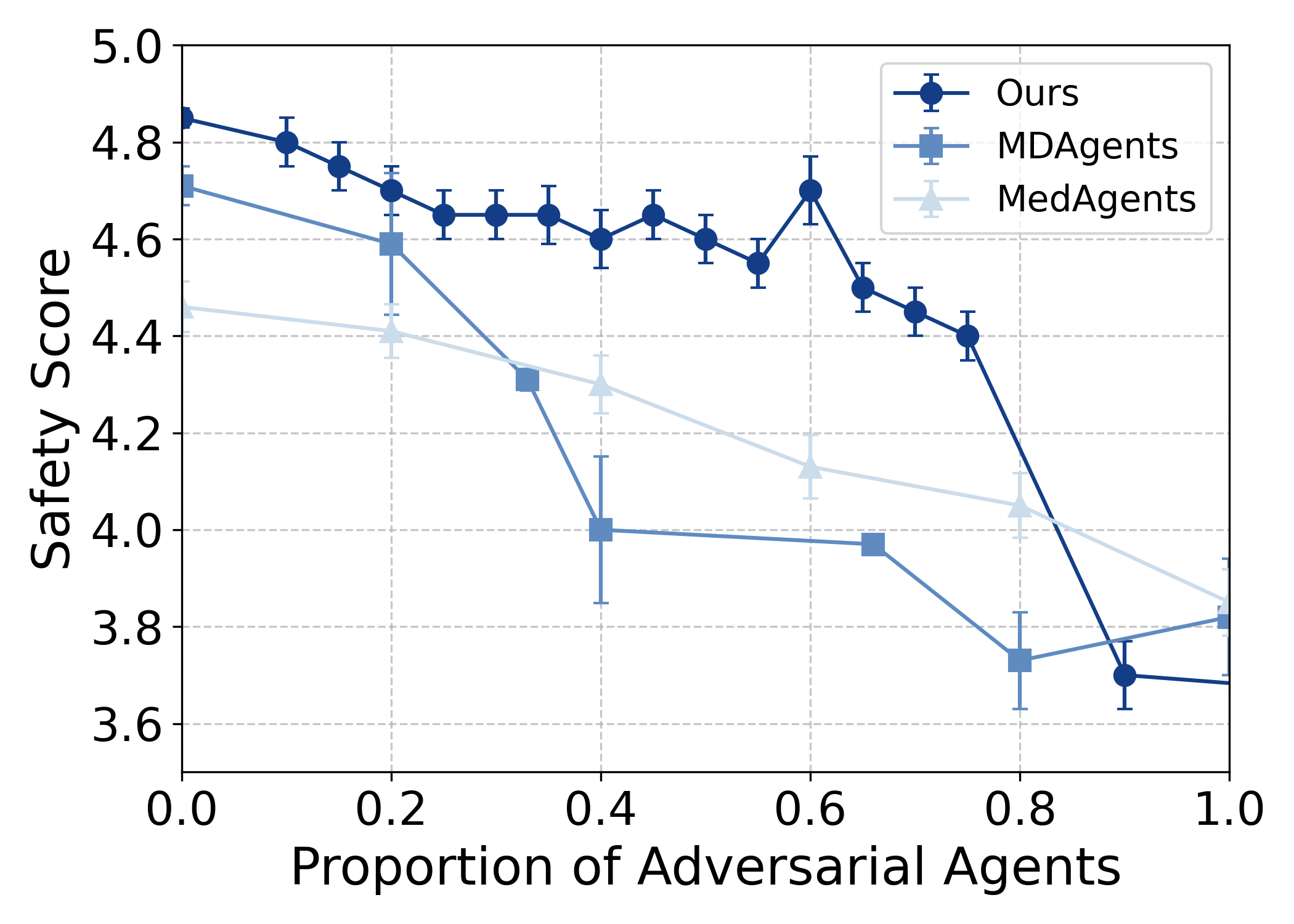
- Outperforms single-agent and other multi-agent systems on 4 out of 5 healthcare safety benchmarks, with up to 8.2% improvement on Red Teaming
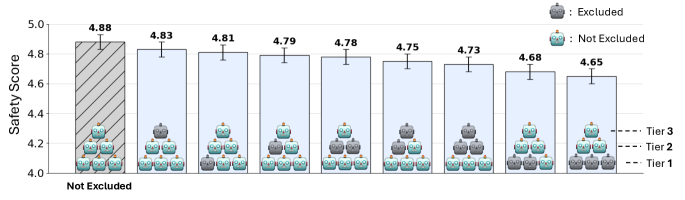
- Absorbs up to 24% of individual agent errors before they compound, while keeping error amplification (overruling correct agents) below 8.4%
- Human-in-the-loop validation showed a physician acting as the highest tier improved medical triage accuracy from 40% to 60%
Breakthrough Assessment
8/10
Strong conceptual contribution applying clinical organizational structures to multi-agent systems. The tiered escalation mechanism offers a practical balance between automation and safety, with solid empirical backing.