📊 Experiments & Results
Evaluation Setup
Agentic software engineering tasks where an agent must resolve GitHub issues.
Benchmarks:
- SWE-Bench Verified (Repository-level code generation and debugging)
- HumanEval (Function-level code generation)
- GPQA (Scientific reasoning QA)
Metrics:
- Pass@1 (resolution rate)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Main results on SWE-Bench Verified showing daVinci-Dev outperforms baselines across model sizes. | ||||
| SWE-Bench Verified | Pass@1 | 48.6 | 58.5 | +9.9 |
| SWE-Bench Verified | Pass@1 | 53.0 | 56.1 | +3.1 |
| Generalization capabilities on standard coding and scientific reasoning benchmarks. | ||||
| HumanEval | Pass@1 | 58.16 | 81.42 | +23.26 |
| GPQA-Main | Accuracy | 43.30 | 44.87 | +1.57 |
Experiment Figures
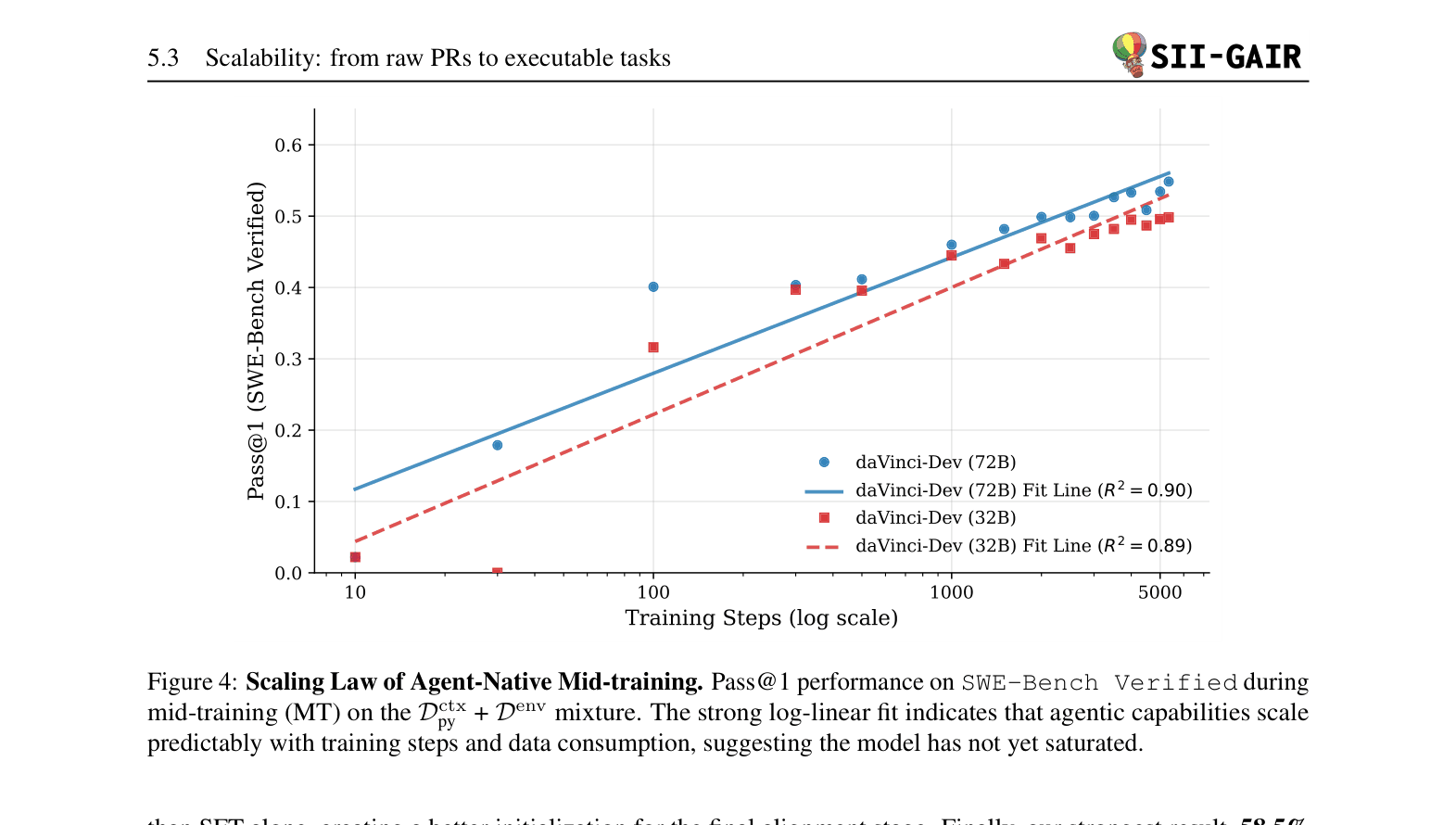
Scaling law of agent-native mid-training: Pass@1 on SWE-Bench Verified vs Training Steps.
Main Takeaways
- Contextually-native PR data (bundling context+edits) is far more token-efficient than factorized approaches, beating Kimi-Dev with half the tokens.
- Environmentally-native trajectories (real execution) provide a crucial boost (~1-3%) even when used in Mid-Training, not just SFT.
- Agentic mid-training generalizes well, significantly boosting performance on standard code generation (HumanEval) and even scientific reasoning (GPQA).
- Scaling laws apply: performance scales log-linearly with the number of training steps on agent-native data.