📝 Paper Summary
Agentic system evaluation
Observability for LLM agents
The paper proposes replacing outcome-based black-box evaluation with Agentic System Behavioral Benchmarking, utilizing a new observability taxonomy to analyze non-deterministic execution flows, decision-making processes, and variability in agentic systems.
Core Problem
Traditional black-box benchmarking evaluates only final outputs, failing to capture the non-deterministic execution flows, stochastic decision-making, and intermediate reasoning errors inherent in complex multi-agent systems.
Why it matters:
- Minor input phrasing changes can radically alter execution paths (flow variability) even if the final output is correct, hiding potential fragility.
- Practitioners struggle with root cause diagnosis; 77% of surveyed users report difficulties, and 80% identify non-deterministic execution as a major challenge.
- Existing tools focus on LLM-level metrics (tokens, latency) rather than agentic behaviors like tool selection, workflow adherence, and multi-agent coordination.
Concrete Example:
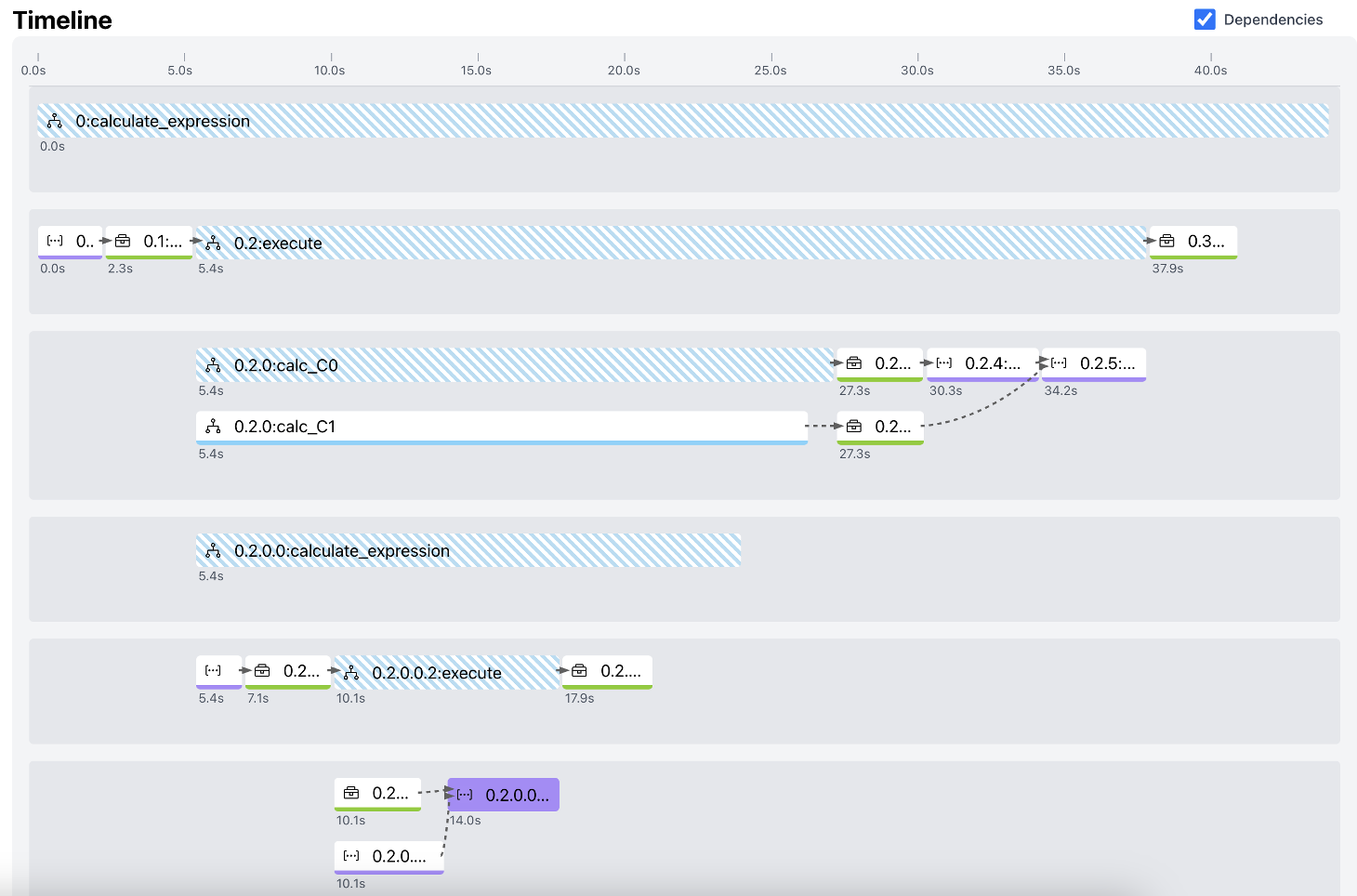
A calculator agent processing '((6+2)×[8−3×2])' might execute correctly one time but fail or take a convoluted path another time due to stochastic LLM planning. Simple accuracy metrics (MSE) miss this internal chaos, where the graph-edit distance between execution traces of the same input shows 63% variability.
Key Novelty
Agentic System Behavioral Benchmarking & ABBench
- Introduces a standardized taxonomy for agent observability that extends OpenTelemetry to track agent-specific entities (Workflows, Tools, Agents, Organizations) rather than just LLM calls.
- Proposes a 'White-Box' analytics approach that evaluates the *process* (execution graph structure, tool usage patterns) alongside the *outcome*.
- Defines specific metrics for variability, such as Graph Edit Distance (GED) between execution traces of identical inputs, to quantify non-determinism.
Architecture
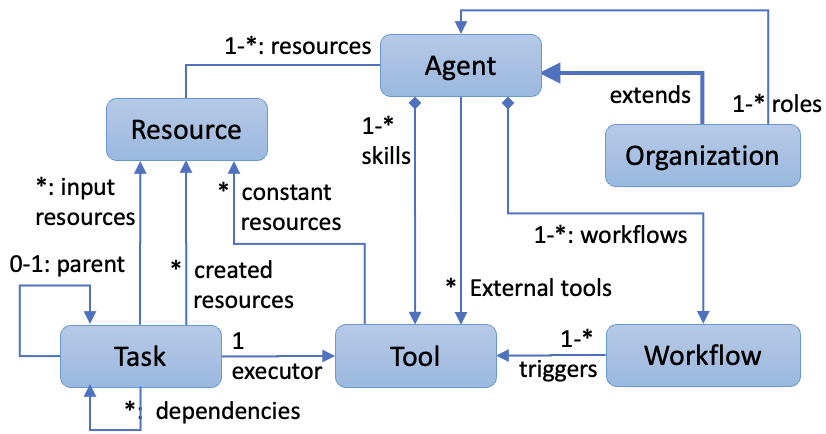
Entity Relationship Diagram of the proposed Agentic System Observability model.
Evaluation Highlights
- User study (n=38) confirms 80% of practitioners view non-deterministic flows as a major challenge, validating the problem definition.
- Experiments on a calculator agent reveal 63% coefficient of variation in execution flow structure (Graph Edit Distance) for identical mathematical inputs across 5 runs.
- Natural language variability causes significant instability: 19% coefficient of variation in accuracy (MSE) when processing identical math problems phrased in natural language.
Breakthrough Assessment
7/10
Strong methodological contribution proposing a necessary shift from outcome-based to behavioral evaluation. The taxonomy and dataset (ABBench) are valuable, though the specific algorithmic innovations are less emphasized than the framework itself.