📝 Paper Summary
LLM-based Recommendation
User Simulation
AFL establishes an iterative communication loop where a recommendation agent and a user agent exchange feedback and rationales to simultaneously improve item suggestions and user behavior simulation.
Core Problem
Existing research optimizes recommendation agents or user agents in isolation, ignoring the reciprocal feedback loop (conversational adjustments and preference discovery) that characterizes real-world user-recommender interactions.
Why it matters:
- Isolating agents misses the opportunity for the recommender to refine its understanding through user feedback
- Single-turn user agents fail to simulate the dynamic process of users discovering their interests through interaction
- Real-world feedback loops often amplify popularity and position biases, requiring robust modeling solutions
Concrete Example:
In a standard setup, a user agent might simply reject an item. In AFL, the user agent explains *why* (e.g., 'I dislike horror'), stored in memory. The recommender agent then uses this history to adjust its next suggestion, while the user agent refines its own preference model based on the recommender's rationales.
Key Novelty
Agentic Feedback Loop (AFL)
- Simulates a dialogue where the Recommender Agent provides items with reasons, and the User Agent provides feedback with reasons
- Uses shared memory to store this interaction history, allowing both agents to iteratively update their reasoning and decisions within a single prediction session
- Integrates a traditional recommendation model (as a tool for the Rec Agent) and a reward model (as a scorer for the User Agent) within an LLM-driven framework
Architecture
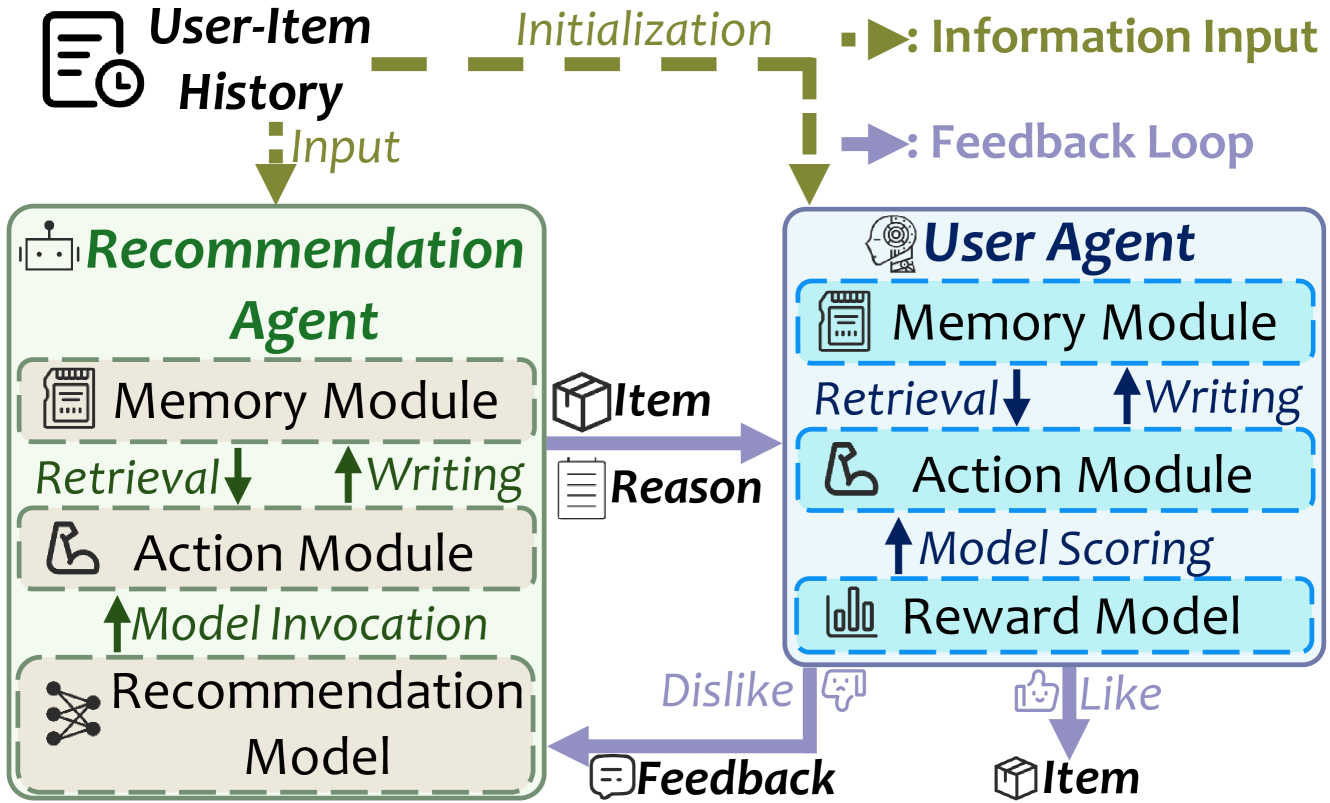
The framework of Agentic Feedback Loop (AFL) showing the interaction between the Recommendation Agent and User Agent.
Evaluation Highlights
- +11.52% average improvement in recommendation performance compared to single recommendation agents
- +21.12% average improvement in user simulation accuracy compared to single user agents
- Demonstrates robustness by not exacerbating popularity or position bias, unlike real-world feedback loops
Breakthrough Assessment
7/10
Significantly improves performance by unifying two distinct tasks (recommendation and simulation) into a collaborative loop, addressing a logical gap in prior isolated agent approaches.