📝 Paper Summary
RL-based
Web agents
AEPO stabilizes agentic reinforcement learning by dynamically allocating rollout budgets based on entropy and preserving high-entropy token gradients during updates to prevent collapse and sustain exploration.
Core Problem
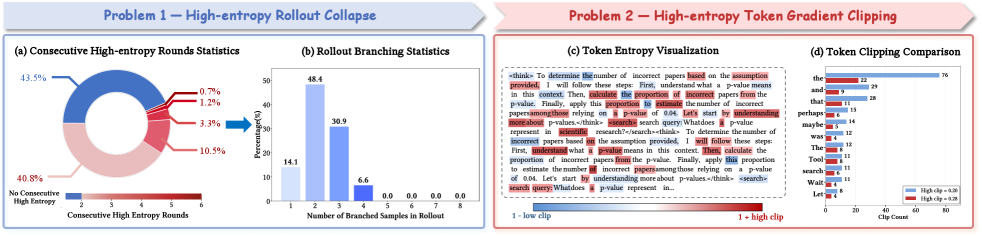
Entropy-guided agentic RL suffers from 'High-Entropy Rollout Collapse' (over-branching on single trajectories) and 'High-Entropy Token Gradient Clipping' (prematurely suppressing exploration due to aggressive gradient clipping).
Why it matters:
- Current methods rely on entropy for exploration but fail to manage it, causing models to deplete sampling budgets on narrow high-entropy paths rather than exploring diverse strategies.
- Vanilla RL algorithms aggressively clip gradients for high-entropy tokens (which often signal valuable tool-use uncertainty), causing the model to stop exploring and collapse into fixed reasoning patterns early in training.
Concrete Example:
In a web search task, an agent might encounter 6 consecutive high-entropy steps. Existing methods like ARPO would burn the entire branching budget on this single chain, starving other potential paths (93.4% of branches concentrated on 1-3 trajectories), while subsequent policy updates would clip these high-entropy gradients, effectively ignoring the exploration signal.
Key Novelty
Agentic Entropy-Balanced Policy Optimization (AEPO)
- Dynamic Entropy-Balanced Rollout: Adaptively allocates global vs. branch sampling budgets by pre-monitoring entropy gaps, and penalizes consecutive high-entropy branches to force wider rather than deeper exploration.
- Entropy-Balanced Policy Optimization: Modifies the PPO clipping mechanism with a 'stop-gradient' term that allows high-entropy tokens to retain their gradients (rescaled) rather than being zeroed out, ensuring the model learns from uncertainty.
Architecture
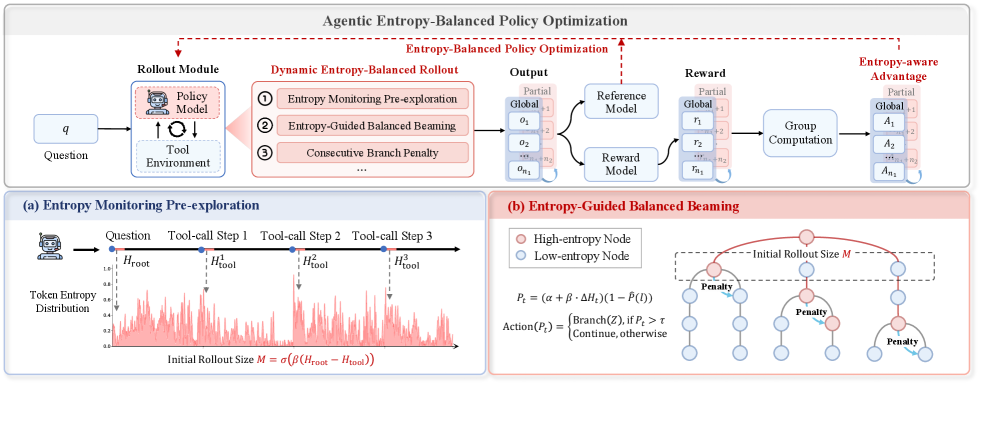
The complete AEPO framework illustrating the two main phases: Dynamic Entropy-Balanced Rollout and Entropy-Balanced Policy Optimization.
Evaluation Highlights
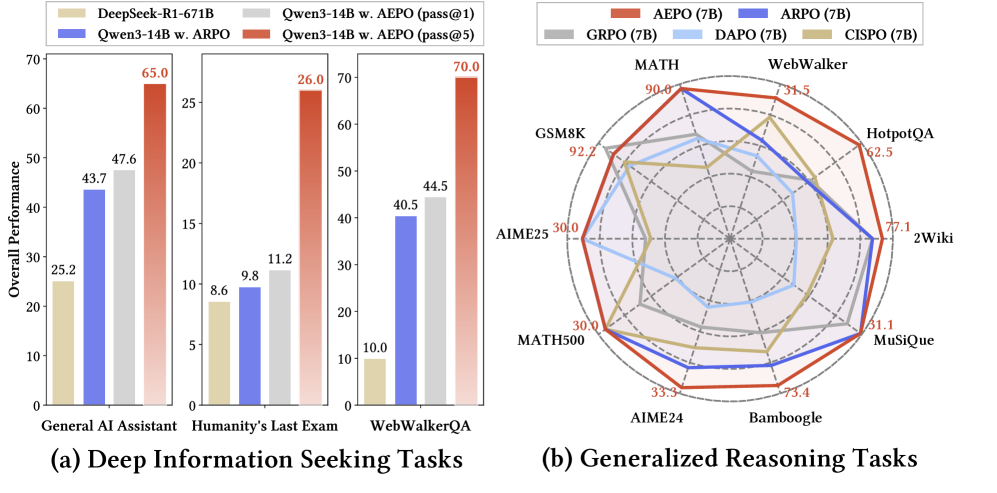
- +3.4% Pass@1 on GAIA benchmark (47.6% vs 44.2% for ARPO) using Qwen3-14B with only 1k samples.
- +4.0% Pass@1 on WebWalkerQA (43.0% vs 39.0% for ARPO), demonstrating improved generalization in web navigation tasks.
- Achieves 26.0% Pass@5 on Humanity's Last Exam, significantly outperforming PPO (13.6%) and ARPO (22.2%).
Breakthrough Assessment
8/10
Strong methodological contribution addressing specific failure modes of entropy-based RL (collapse and clipping). Consistent improvements across 14 diverse benchmarks reinforce its efficacy for generalist web agents.