📊 Experiments & Results
Evaluation Setup
Two-player guessing game (p=2/3) simulation
Benchmarks:
- Human Guessing Game Dataset (Strategic Reasoning)
Metrics:
- Mean guess value
- Wasserstein distance (between agent and human distributions)
- Frequency of zero guesses (dominant strategy)
- Statistical methodology: Levene’s test for variance homogeneity; Independent samples t-test or Welch’s t-test for means; Mann–Whitney U for skewed data.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Human Dataset | Mean Guess | 29.05 | 11.19 | -17.86 |
| Human Dataset | Wasserstein Distance | 0.00 | 22.34 | +22.34 |
| Human Dataset | Skewness | 0.55 | 1.50 | +0.95 |
Experiment Figures
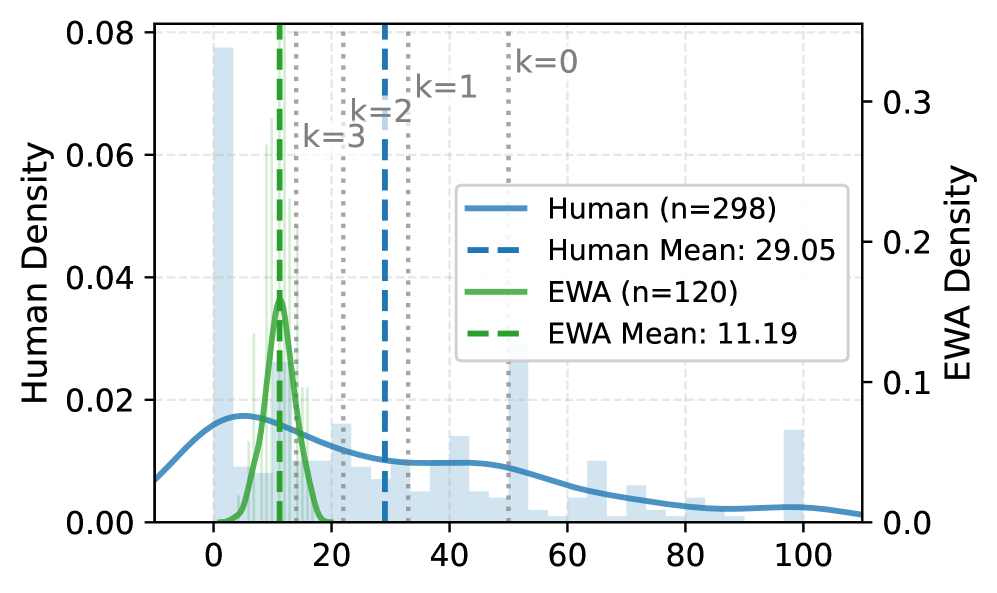
Comparison of guess distributions between the EWA agent and Human participants
Main Takeaways
- Traditional game-theoretic models (EWA) are 'super-human' in rationality (mean 11.19 vs 29.05) but fail to capture the bounded rationality of human players, evidenced by a large Wasserstein distance.
- Human experts are distinct from students, showing significantly lower means and higher skewness (1.50 vs 0.55), providing two distinct targets for agent calibration.
- The paper posits that simply adding agentic complexity (reasoning steps, profiles) does not linearly result in better human approximation, depending heavily on the underlying LLM capabilities.