📊 Experiments & Results
Evaluation Setup
Comprehensive evaluation on standard NLP benchmarks and chatbot arena
Benchmarks:
- LMSYS Chatbot Arena (Human preference evaluation (blind side-by-side))
- GSM8K / MATH / MGSM (Mathematical Reasoning)
- MMLU / MMLU-Pro / CMMLU (General Knowledge)
- HumanEval / MBPP / LiveCodeBench (Code Generation)
Metrics:
- Arena Score (Elo)
- Accuracy (%)
- Pass@1
- Statistical methodology: LMSYS Arena reports 95% Confidence Intervals
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Hunyuan-TurboS demonstrates top-tier performance on the LMSYS Chatbot Arena, surpassing several well-known proprietary models. | ||||
| LMSYS Chatbot Arena | Arena Score | 1352 | 1356 | +4 |
| In mathematical reasoning, the model shows strong performance, outperforming GPT-4.5 on key benchmarks. | ||||
| MATH | Accuracy | 86.2 | 90.0 | +3.8 |
| GSM8K | Accuracy | 91.9 | 94.4 | +2.5 |
| The model is highly efficient, significantly reducing token usage compared to other reasoning models. | ||||
| Inference Token Usage (STEM/General Mix) | Average Output Tokens | 2283.5 | 1207.8 | -1075.7 |
Experiment Figures
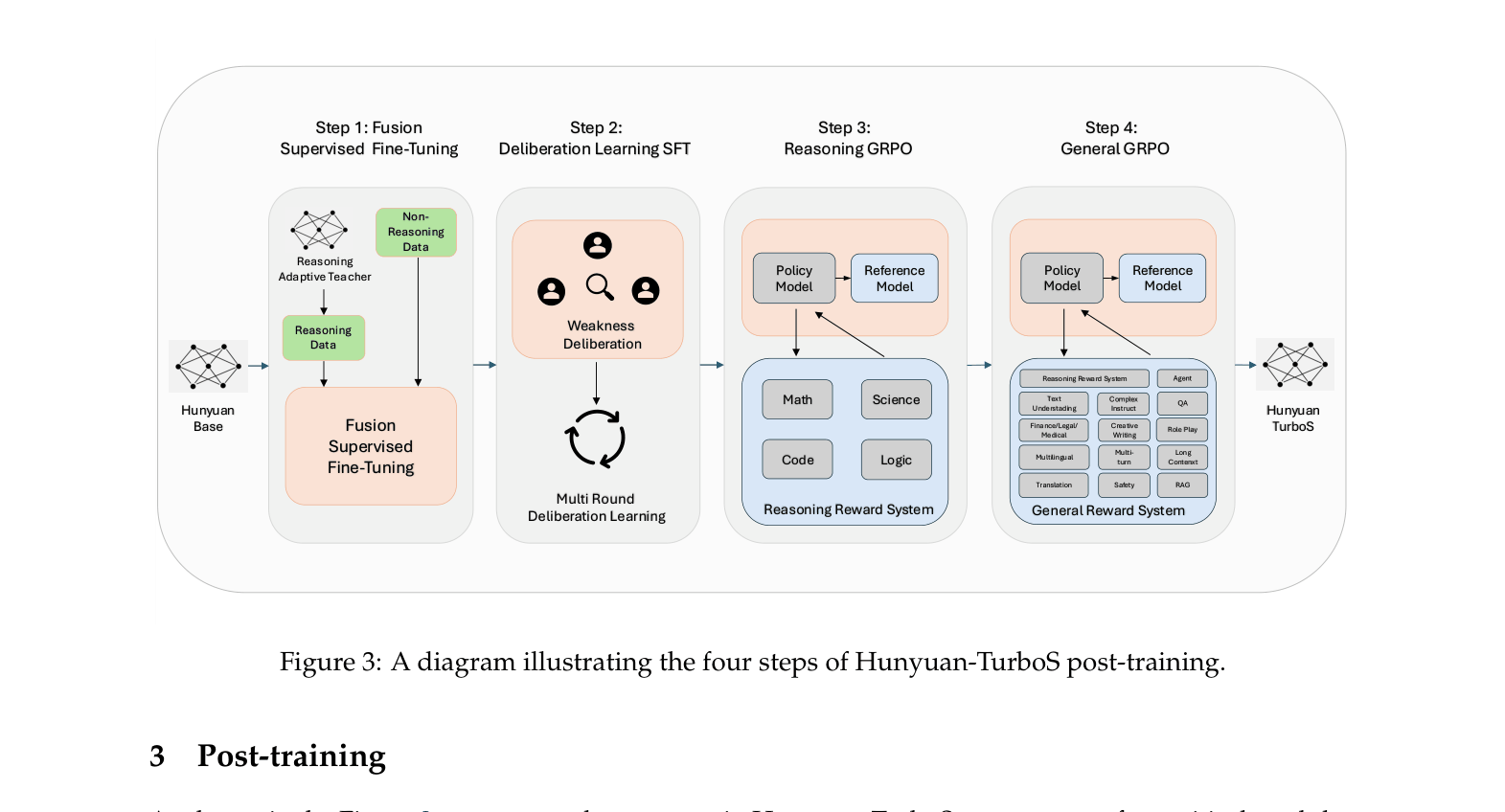
Diagram of the four-step post-training pipeline.
Main Takeaways
- Hybrid Mamba-Transformer architecture successfully scales to 560B parameters without performance loss compared to pure Transformers.
- Adaptive Long-short CoT drastically reduces inference cost (approx 50% token reduction vs reasoning models) by not over-thinking simple queries.
- Two-stage GRPO (Reasoning then General) effectively balances specialized STEM capabilities with general instruction following.
- Achieves SOTA-level performance on Chinese benchmarks (CMMLU, C-Eval) while remaining competitive globally.