📝 Paper Summary
Agentic Evaluation
General-purpose Agents
Benchmark Integration
Exgentic introduces a Unified Protocol and framework to evaluate general-purpose agents across diverse environments without domain-specific engineering, revealing that underlying LLM quality drives performance more than agent architecture.
Core Problem
Current agent benchmarks impose bespoke communication protocols and implicit domain assumptions, preventing the fair evaluation of general-purpose agents that lack pre-engineered integration.
Why it matters:
- Real-world settings require agents to deploy scalably across heterogeneous environments without manual customization for each new domain
- Existing benchmarks (like SWE-Bench) rely on specific integration hacks (e.g., pre-cloned repos) that obscure true agent capabilities
- Current consolidation efforts (BrowserGym, Harbor) enforce single modalities (web or CLI), testing only a diminished version of the agent
Concrete Example:
In SWE-Bench, a standard benchmark assumes a human integrator clones the repo and handles submission. A general agent trying to solve this blindly fails because it doesn't know it needs to output a patch file in a specific format or that the repo is already present in a specific path.
Key Novelty
Unified Protocol and Exgentic Framework
- Introduces a mediation layer that standardizes communication between any agent and any benchmark using a canonical (Task, Context, Actions) representation
- Decouples evaluation from domain-specific protocols by translating benchmark-specific signals (like specialized tool calls) into a generic format agents can ingest
- Establishment of the first Open General Agent Leaderboard evaluating 5 agents across 6 diverse environments without environment-specific tuning
Architecture
Conceptual diagram comparing pairwise integration (A), single-protocol consolidation (B), and the Unified Protocol (C).
Evaluation Highlights
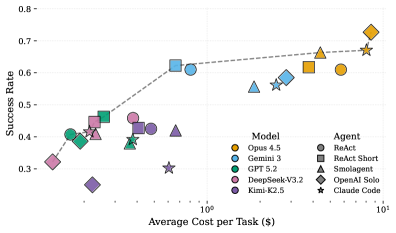
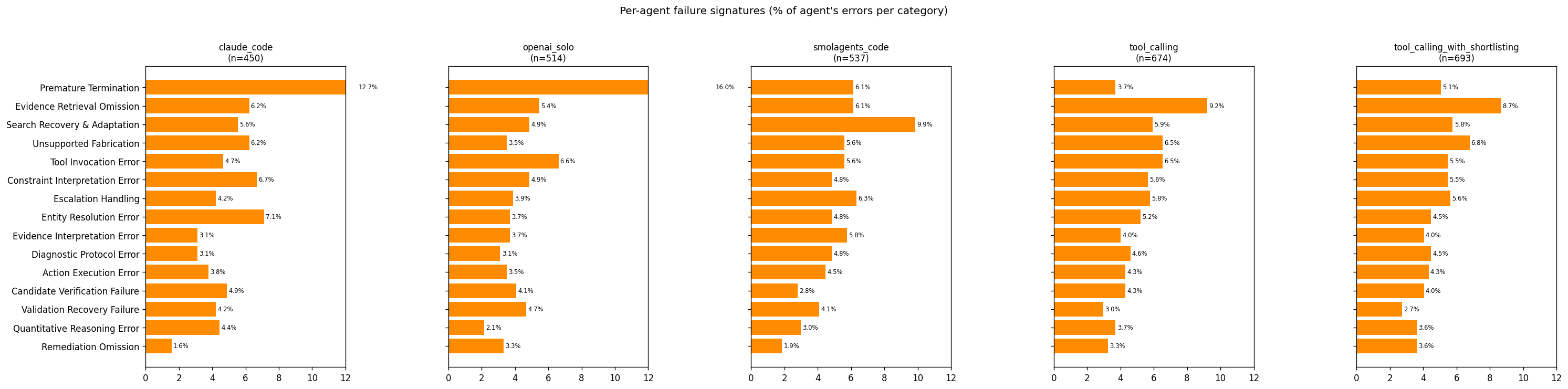
- General-purpose agents demonstrate cross-domain generalization comparable to domain-specific baselines without tuning
- Agent performance is primarily dictated by the underlying Language Model (e.g., GPT-4 vs. Claude 3.5) rather than the agentic scaffold (ReAct vs. Solo)
- Evaluation of 5 agent architectures across 6 benchmarks (SWE-Bench, τ-Bench, AppWorld, etc.) totaled $22K in API costs
Breakthrough Assessment
8/10
Significant infrastructure contribution. Solves the fragmentation problem in agent evaluation by providing a unified protocol, enabling the first true 'general agent' comparison across radically different domains.