📝 Paper Summary
Multi-agent collaboration
Tabular anomaly detection
Debate-based reasoning
MAD treats anomaly detection as a debate where heterogeneous agents (models) must justify disagreements with confidence and evidence, resolving conflicts via a mathematically grounded coordinator rather than simple averaging.
Core Problem
In tabular anomaly detection, heterogeneous models (trees, deep nets) frequently disagree on rare or shifted data, and standard averaging hides these conflicts without resolving them.
Why it matters:
- High-stakes fields like finance and healthcare require resolving ambiguity rather than smoothing it over, especially when models disagree strongly
- Standard ensembles offer no explanation for why one model's score was preferred over another in contentious cases
- Single model families rarely dominate across all tabular datasets, making robust aggregation essential for reliability
Concrete Example:
Agent A (Tree) confidently flags a transaction as fraud based on feature X, while Agent B (Neural Net) flags it as normal citing feature Y. Standard averaging yields a middle score with no insight. MAD forces agents to provide evidence; if Agent A's evidence is inconsistent with the consensus, the coordinator down-weights it, producing a justified final decision.
Key Novelty
Multi-Agent Debate (MAD) with Exponentiated Gradient Coordination
- Agents emit not just scores, but messages containing confidence and structured evidence (e.g., feature attributions)
- A coordinator synthesizes 'debate losses' based on whether high-confidence disagreement is supported by consistent evidence
- Updates agent influence dynamically using an exponentiated gradient rule, ensuring theoretical regret guarantees while producing an auditable trace
Architecture
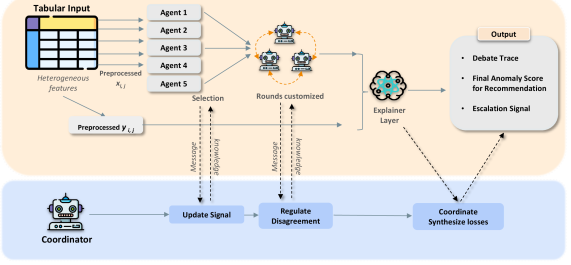
Conceptual framework of MAD showing agents, message passing, and the coordinator.
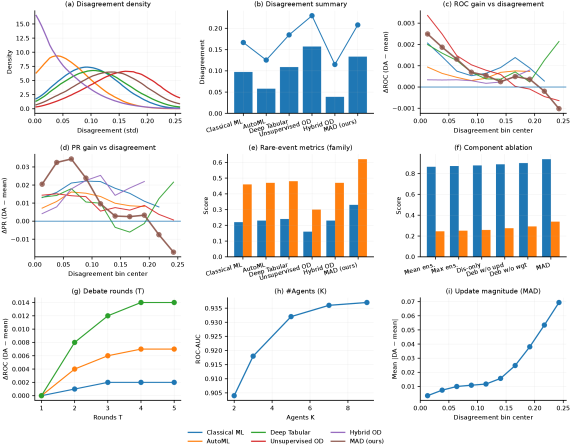
Evaluation Highlights
- Achieves highest rare-event detection (Recall@1%FPR) across diverse benchmarks, outperforming strong baselines like AutoGluon and TabPFN
- Reduces calibration error (ECE) and fairness gaps compared to single models, showing that debate improves reliability without sacrificing accuracy
- Performance gains are concentrated in high-disagreement regimes, confirming the method intervenes primarily when models conflict
Breakthrough Assessment
8/10
Novel application of multi-agent debate to tabular data with strong theoretical grounding (regret bounds) and clear empirical gains in robustness and interpretability.