📝 Paper Summary
Self-evolving Agentic reasoning
Agentic feedback mechanisms
Knowledge-augmented planning
KnowSelf trains agents to autonomously recognize when to act fast, when to reflect, and when to query external knowledge, optimizing performance while minimizing unnecessary computation.
Core Problem
Current agent planning methods use a 'flood irrigation' approach, indiscriminately injecting knowledge or feedback regardless of necessity, which is inefficient and leads to pattern collapse.
Why it matters:
- Blindly invoking external knowledge or reflection for every step significantly increases inference latency and computational cost
- Agents trained via direct imitation often memorize patterns rather than reasoning, becoming fragile to unexpected environmental signals
- Humans dynamically assess whether they need help or extra thought; lack of this metacognition makes agents inefficient compared to human decision-making
Concrete Example:
In a task like 'put a clean egg in microwave', a standard agent might repeatedly try to pick up an egg without realizing it needs cleaning first. An agent relying solely on knowledge might retrieve irrelevant cooking instructions. KnowSelf, however, first tries to act; if it fails, it reflects ('I need to clean it'), or if reflection fails, it queries knowledge ('To obtain a cleaned object, find it then clean it').
Key Novelty
KnowSelf: Data-Centric Situational Self-Awareness
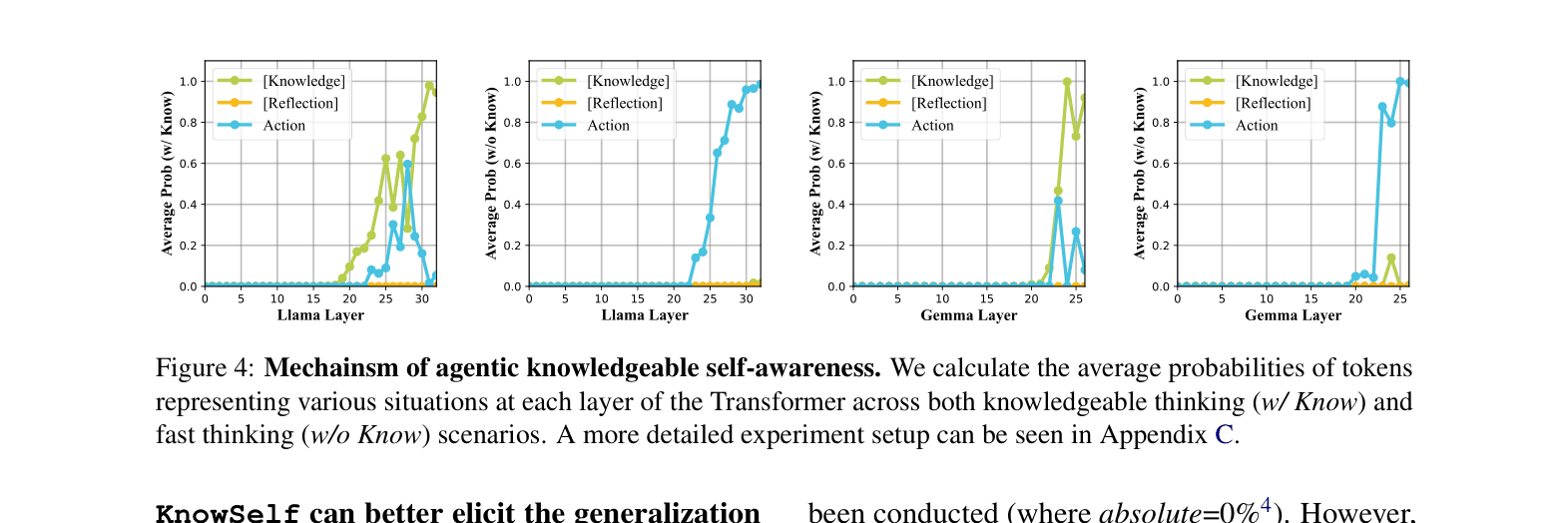
- Classifies decision states into three tiers based on agent capability: Fast Thinking (confident action), Slow Thinking (needs reflection), and Knowledgeable Thinking (needs external help)
- Constructs training data by marking self-explored trajectories with special tokens (<r> for reflection, <k> for knowledge) based on whether the agent's initial or reflected prediction was correct
- Uses a two-stage training process (SFT + RPO) to teach the agent to self-generate these tokens, effectively deciding its own inference path dynamically
Architecture
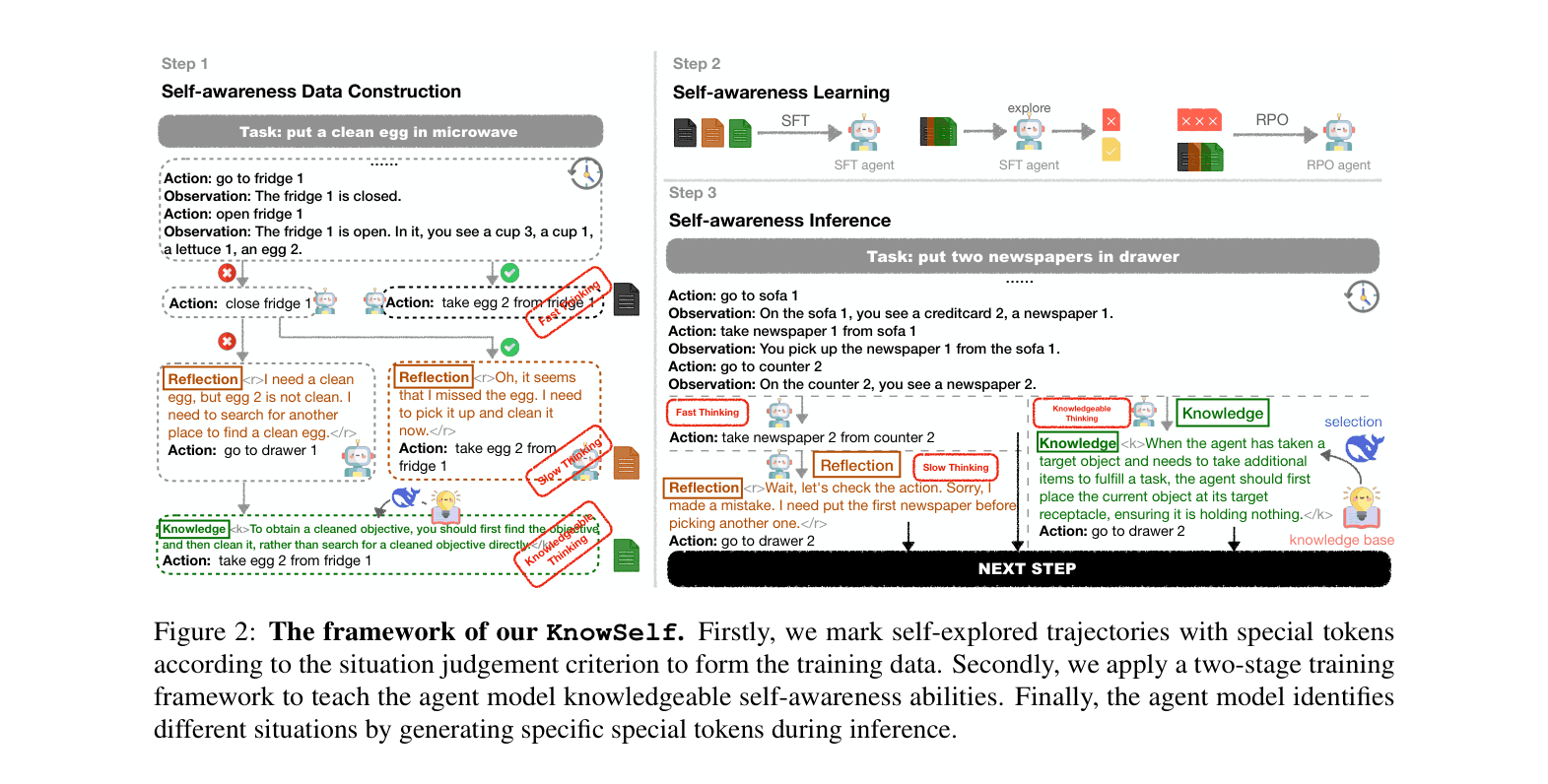
The KnowSelf framework covering Data Construction, Learning, and Inference. It illustrates how trajectories are marked with <r> (Reflection) and <k> (Knowledge) tokens and how the model switches between Fast, Slow, and Knowledgeable thinking during inference.
Evaluation Highlights
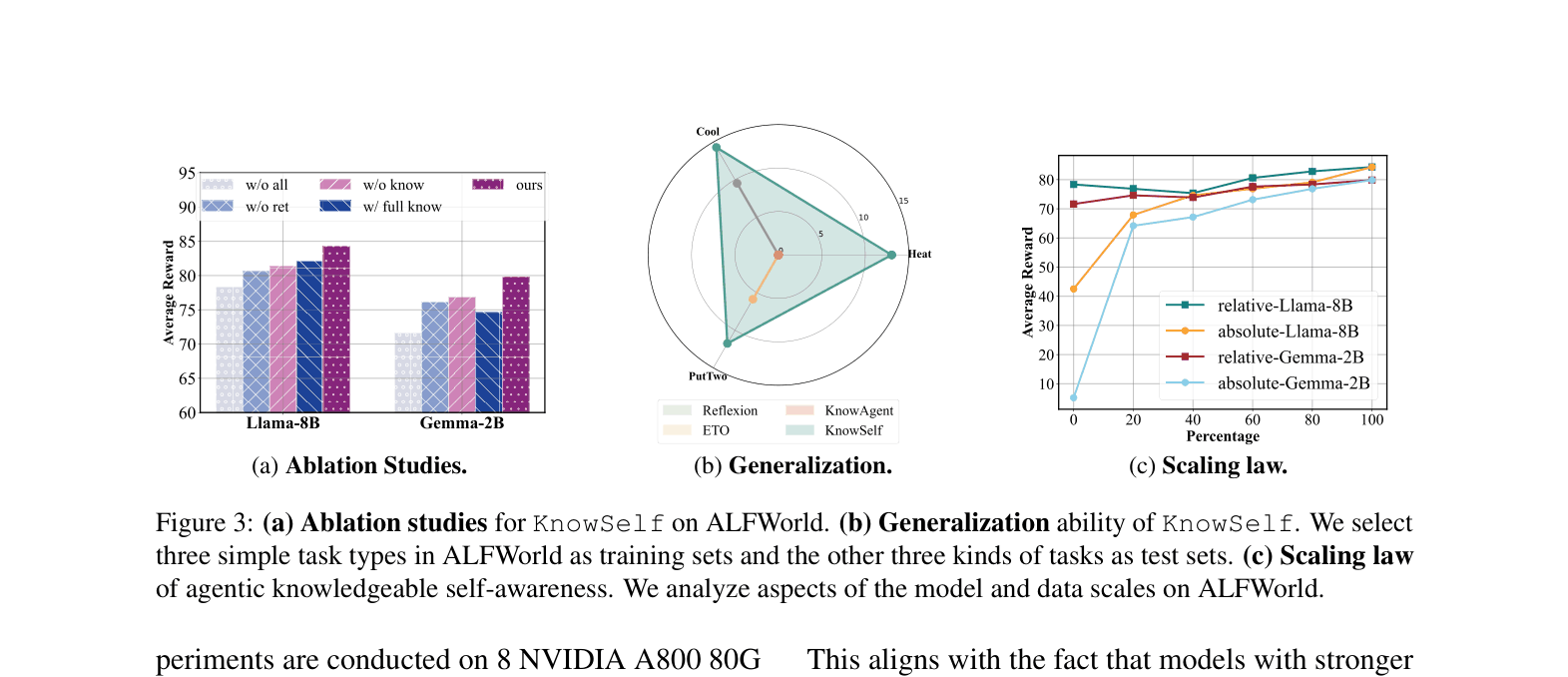
- Outperforms GPT-4o-based ExpeL on ALFWorld using Llama-8B with only 15.01% of actions requiring external knowledge (vs 100% for ExpeL)
- Achieves 91.67% success on 'Put' tasks in ALFWorld with Gemma-2B, surpassing the 0% success rate of the standard ReAct baseline
- Demonstrates strong generalization: models trained only on simple tasks (Put, Clean, Examine) achieve >70% success on unseen complex tasks (Heat, Cool, PutTwo), whereas baselines like KnowAgent fail completely (0%)
Breakthrough Assessment
8/10
Significant efficiency gain by making knowledge retrieval dynamic rather than static. Effectively addresses the trade-off between performance and inference cost in agentic systems.