📝 Paper Summary
LLM Reasoning Frameworks
Graph-based Prompting
Neuro-symbolic Reasoning
L2T models LLM reasoning as an annotatable graph where a Graph Neural Network dynamically selects reasoning strategies and prompt parameters step-by-step without task-specific engineering.
Core Problem
Existing reasoning frameworks (CoT, ToT, GoT) rely on static, task-specific prompts and predefined structures, preventing models from adapting their strategy in real-time or generalizing across diverse tasks without manual design.
Why it matters:
- High reliance on task-specific prompts limits generalization; complex reasoning requires precise, handcrafted prompts that fail when tasks change
- Current methods (like Tree of Thoughts) cannot adjust model parameters (e.g., temperature) or branching factors dynamically during the reasoning process
- Fine-tuning for specific reasoning tasks is computationally expensive and infeasible for API-only models
Concrete Example:
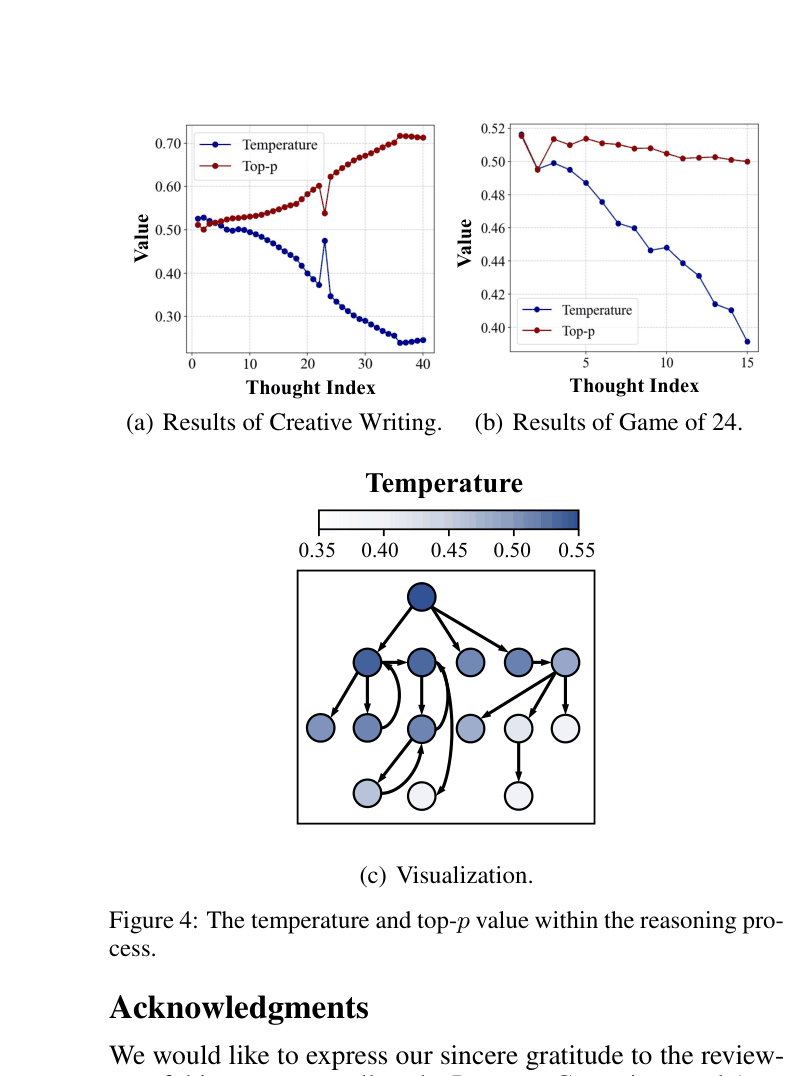
In a Game of 24 puzzle, a static Chain-of-Thought prompt might force the model to linearly compute numbers even when a dead end is reached. L2T detects the dead end (Reasoning Stop label), backtracks, and adjusts the temperature/branching factor to explore new arithmetic combinations automatically.
Key Novelty
L2T (Learn to Think)
- Models the reasoning process as a dynamic graph where an LLM classifies nodes (thoughts) to decide whether to continue, stop, or backtrack
- Uses a trainable GNN 'Actor' to observe the reasoning graph's state and output actions that adjust prompt parameters (e.g., branching factor) and LLM hyperparameters (e.g., temperature) in real-time
- Bootstraps itself by automatically generating task formats and evaluation criteria from the task description, removing the need for human-designed prompts
Architecture
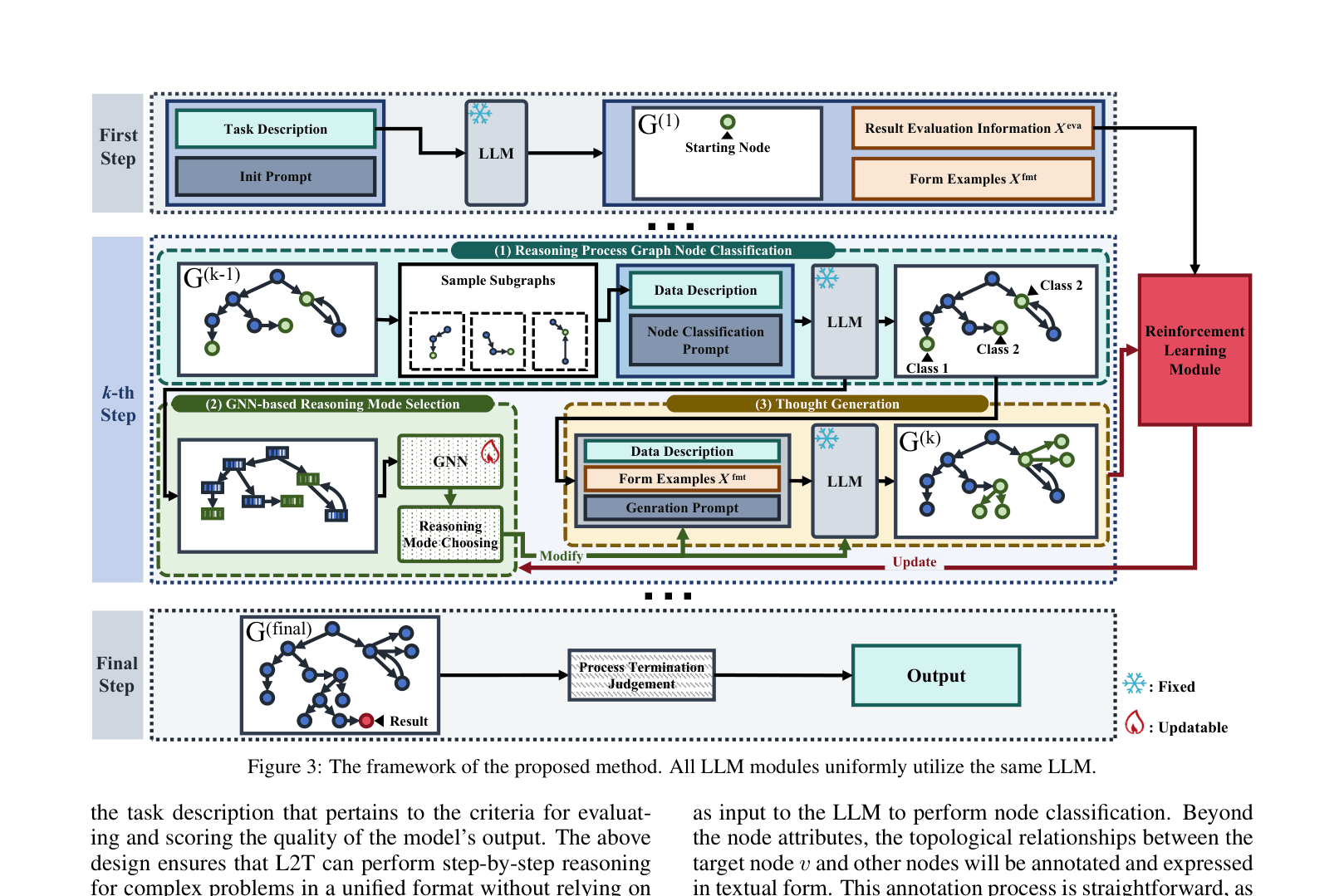
The L2T framework pipeline showing the interaction between the LLM, the Reasoning Process Graph, and the GNN-based Reinforcement Learning module.
Evaluation Highlights
- Achieved 100% success rate on 3x3 Sudoku and 98.46% on 4x4 Sudoku, outperforming Tree of Thoughts (92.31% / 72.31%)
- Surpassed Chain-of-Thought (few-shot) by +50.08 points on Game of 24 (80.42% vs 30.34%)
- Maintained high performance (98.46% on 4x4 Sudoku) even when task-specific prompts were removed, whereas ToT dropped to 34.62%
Breakthrough Assessment
8/10
Strong conceptual novelty in using GNNs to control LLM inference parameters dynamically. Significant performance gains on logic puzzles, especially in zero-shot/generalization settings.