📝 Paper Summary
Memory recall
Agentic AI
Agentic Plan Caching reduces serving costs by extracting high-level plan templates from past executions and adapting them for new, semantically similar requests using lightweight models.
Core Problem
Existing LLM caching methods (context/semantic caching) fail for agents because agent outputs depend on dynamic external data, meaning identical queries require different specific actions despite sharing high-level plans.
Why it matters:
- Plan-Act agents incur substantial latency and cost due to complex reasoning and repeated planning steps (often using expensive models like reasoning LLMs).
- Standard caching misses reuse opportunities because it cannot separate a query's core intent from its data-dependent context (e.g., specific file names or GUI coordinates).
- Current memory approaches focus on capability (accuracy/hallucination) rather than the critical need for efficient, low-cost serving.
Concrete Example:
For a data analysis request 'summarize key statistics,' standard caching fails because the specific actions depend on the dataset (different columns/values). APC recognizes the shared intent 'summary,' retrieves a general plan template, and fills in the specific dataset details.
Key Novelty
Agentic Plan Caching (APC)
- Shifts from query-level caching (exact text match) to task-level caching by extracting reusable 'plan templates' that strip away specific context (e.g., entity names).
- Uses keyword extraction rather than semantic embeddings for cache lookups, avoiding false positives caused by irrelevant details in complex agent queries.
- Employs a lightweight 'adapter' model to fill in a retrieved template with current context, bypassing the expensive 'planner' model used on cache misses.
Architecture
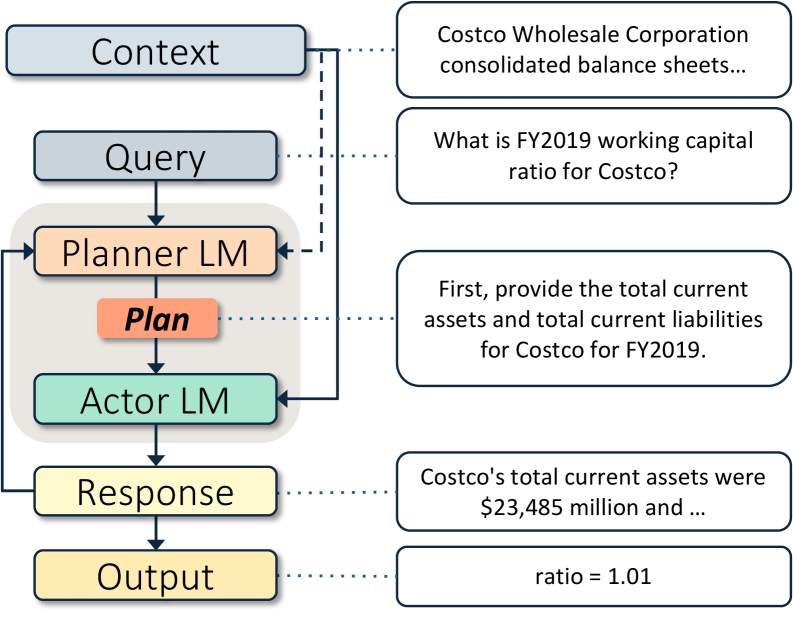
The end-to-end inference flow of Agentic Plan Caching, showing the Hit/Miss paths and the template extraction process.
Evaluation Highlights
- Reduces average cost by 50.31% and latency by 27.28% across five agent workloads compared to baselines.
- Maintains 96.61% of optimal application performance relative to using the expensive planner for every request.
- Compatible with existing LLM serving frameworks and can function alongside standard caching techniques.
Breakthrough Assessment
8/10
Significant practical contribution for deploying agents at scale. Addresses a specific failure mode of standard caching (data-dependency) with a cost-effective architectural solution.