📝 Paper Summary
Conversational Recommender Systems (CRS)
LLM-based Agents
Music Recommendation
WeMusic-Agent combines massive music knowledge internalization with an efficient mechanism to decide when to answer directly versus when to call external tools, improving recommendation accuracy and efficiency.
Core Problem
Existing conversational music recommenders struggle to balance internal domain knowledge with external tool usage: relying solely on tools is slow and ignores nuance, while relying solely on internal weights leads to hallucinations.
Why it matters:
- Current LLMs lack specific, long-tail music knowledge (e.g., obscure genres, release years) necessary for high-quality recommendations.
- Excessive tool calling increases latency and computational cost, degrading the user experience in real-time conversational settings.
- There is no standard benchmark for evaluating conversational music recommendation that covers relevance, personalization, and diversity.
Concrete Example:
If a user asks 'recommend some 90s rock', a pure tool-use agent might make multiple slow API calls for a simple query. Conversely, a standard LLM might hallucinate non-existent songs or mix up genres without verifying against a database.
Key Novelty
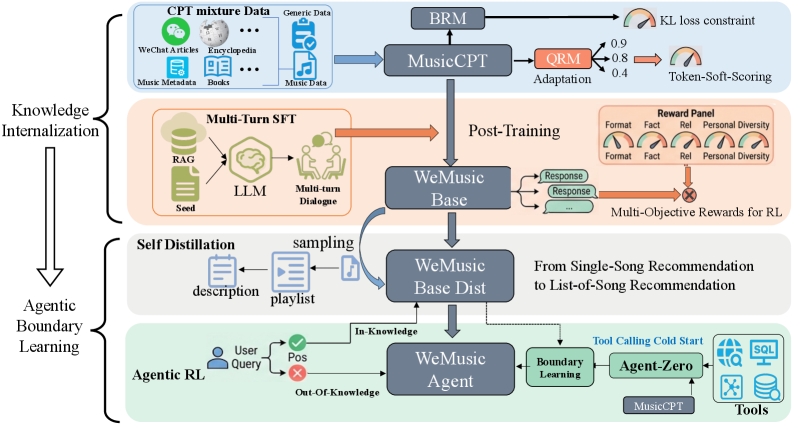
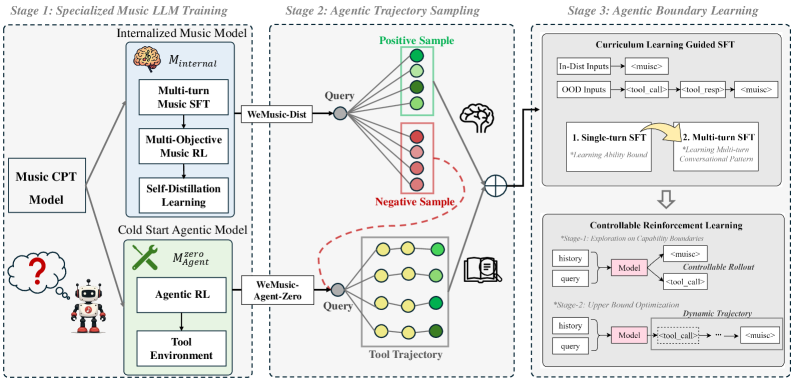
Knowledge Internalization + Agentic Boundary Learning
- Internalizes vast music knowledge (50B tokens) into the LLM's weights so it can handle general queries directly without tools.
- Teaches the model a 'boundary'—learning to distinguish between questions it can answer from memory vs. those requiring external verification—using trajectory sampling.
- Introduces WeMusic-Bench, a comprehensive benchmark for evaluating conversational music recommendation on relevance, personalization, and diversity.
Architecture

The WeMusic-Agent framework pipeline, illustrating the two main training phases: Knowledge Internalization (Phase 1) and Agentic Boundary Learning (Phase 2).
Evaluation Highlights
- +28.16% improvement in Success Rate (SR@10) over GPT-4o on the WeMusic-Bench leaderboard.
- Reduces tool invocation frequency by avoiding unnecessary calls, achieving 5x faster inference speeds compared to pure tool-use agents.
- Outperforms Llama-3-70B-Instruct by +30.56% in SR@10 despite being a much smaller (8B) model.
Breakthrough Assessment
7/10
Strong practical contribution for domain-specific agents. The combination of massive domain pre-training and learning *when* to use tools is valuable, though the architectural innovation is evolutionary rather than revolutionary.