📝 Paper Summary
Multi-agent
Self-evolving Agentic reasoning
MarsRL jointly optimizes a multi-agent reasoning team (Solver, Verifier, Corrector) using reinforcement learning with agent-specific rewards and a pipelined training architecture to overcome reward noise and training latency.
Core Problem
Effective multi-agent reasoning pipelines (like Solver-Verifier-Corrector) developed for closed-source models fail to generalize to open-source models due to weak critique/correction capabilities and the difficulty of training them jointly.
Why it matters:
- Existing single-model scaling is limited by quadratic complexity of context length
- Simply porting successful prompting strategies from frontier models (like Gemini) to smaller open weights (like Qwen) often yields no gain
- Standard RL applies rewards to full trajectories, creating noise in multi-agent settings where an agent might be right for the wrong reasons (e.g., a Verifier flagging a correct solution as wrong, but the Corrector fixing it anyway)
Concrete Example:
A Solver produces a correct solution, but the Verifier wrongly flags it as a bug. The Corrector then outputs a correct final answer. In standard RL, the Verifier would receive a positive reward for the trajectory outcome despite its error, reinforcing bad judgment.
Key Novelty
Agentic RL with Pipeline Parallelism (MarsRL)
- Decouples credit assignment by assigning agent-specific verifiable rewards: Solver/Corrector are rewarded on answer correctness, while Verifiers are rewarded on the accuracy of their critique relative to the actual solution status.
- Implements agent-level pipeline parallelism where agent outputs are immediately added to training queues after execution rather than waiting for full multi-turn trajectory completion, significantly reducing training latency.
Architecture
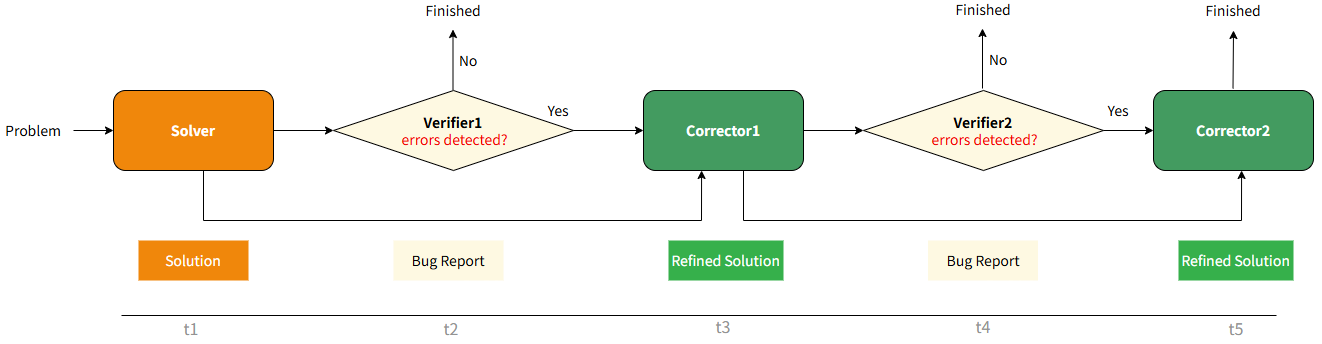
The Agentic Pipeline Parallelism training workflow.
Evaluation Highlights
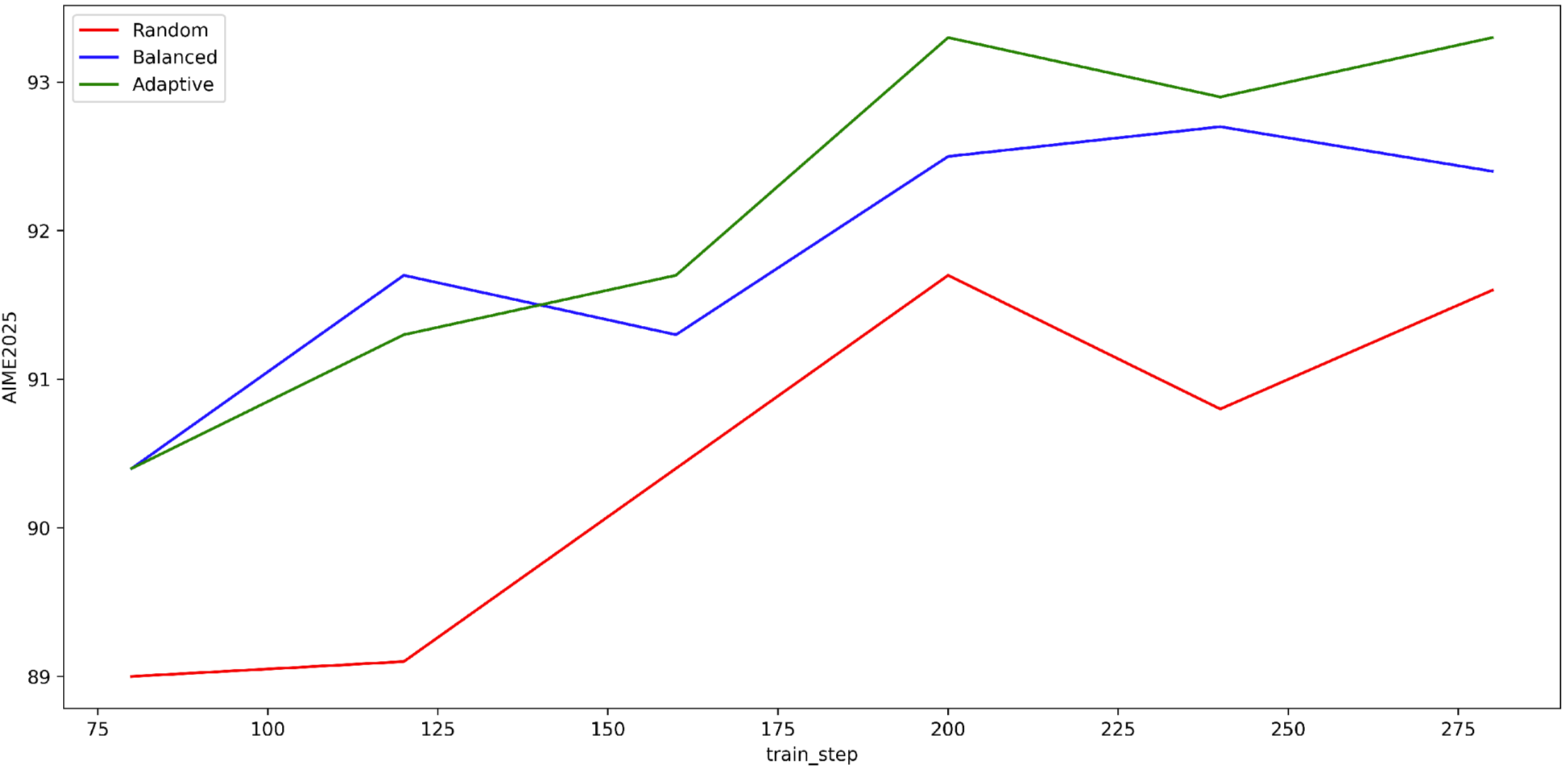
- +6.8% accuracy improvement on AIME2025 (86.5% to 93.3%) applying MarsRL to Qwen3-30B-A3B-Thinking-2507.
- +8.9% accuracy improvement on BeyondAIME (64.9% to 73.8%) using the same base model.
- Outperforms the much larger Qwen3-235B-A22B-Thinking-2507 model (92.3% on AIME2025) while using only a 30B parameter base.
Breakthrough Assessment
8/10
Significant performance gains on hard math benchmarks (AIME) by successfully training a multi-agent loop, solving the key problem of reward assignment in cooperative reasoning systems.