📝 Paper Summary
Multi-Agent Systems
Automated Code Generation
SEW is a framework that automatically generates and optimizes multi-agent code generation workflows by evolving both the workflow topology and individual agent prompts using LLM-based mutation operators.
Core Problem
Current multi-agent systems for code generation rely on manually hand-crafted workflows and prompts, which are inefficient to design and fail to adapt to the specific complexity of different coding tasks.
Why it matters:
- Manual workflow design is labor-intensive and requires domain expertise, limiting scalability
- Static workflows cannot leverage the full potential of LLMs to autonomously adapt strategies for complex problems
- A workflow optimized for one domain (e.g., machine learning) often fails in another (e.g., software development), necessitating automated adaptation
Concrete Example:
When asked to implement `sum_squares(n)`, a single agent might write a loop `range(1, n)` that misses the last integer. SEW evolves a workflow where a 'Code Reviewing Agent' detects this off-by-one error and instructs a 'Code Rewriting Agent' to correct the range to `range(1, n+1)`.
Key Novelty
Self-Evolving Workflow (SEW) with Dual Evolution
- Jointly optimizes the team structure (workflow topology) and the specific instructions (prompts) for each agent using LLMs as mutation operators
- Introduces Direct Evolution (modifying prompts directly) and Hyper Evolution (modifying the mutation prompts themselves) to escape local optima
- Identifies CoRE (Code Representation and Execution) as the optimal textual representation for LLMs to generate and modify executable agentic workflows
Architecture
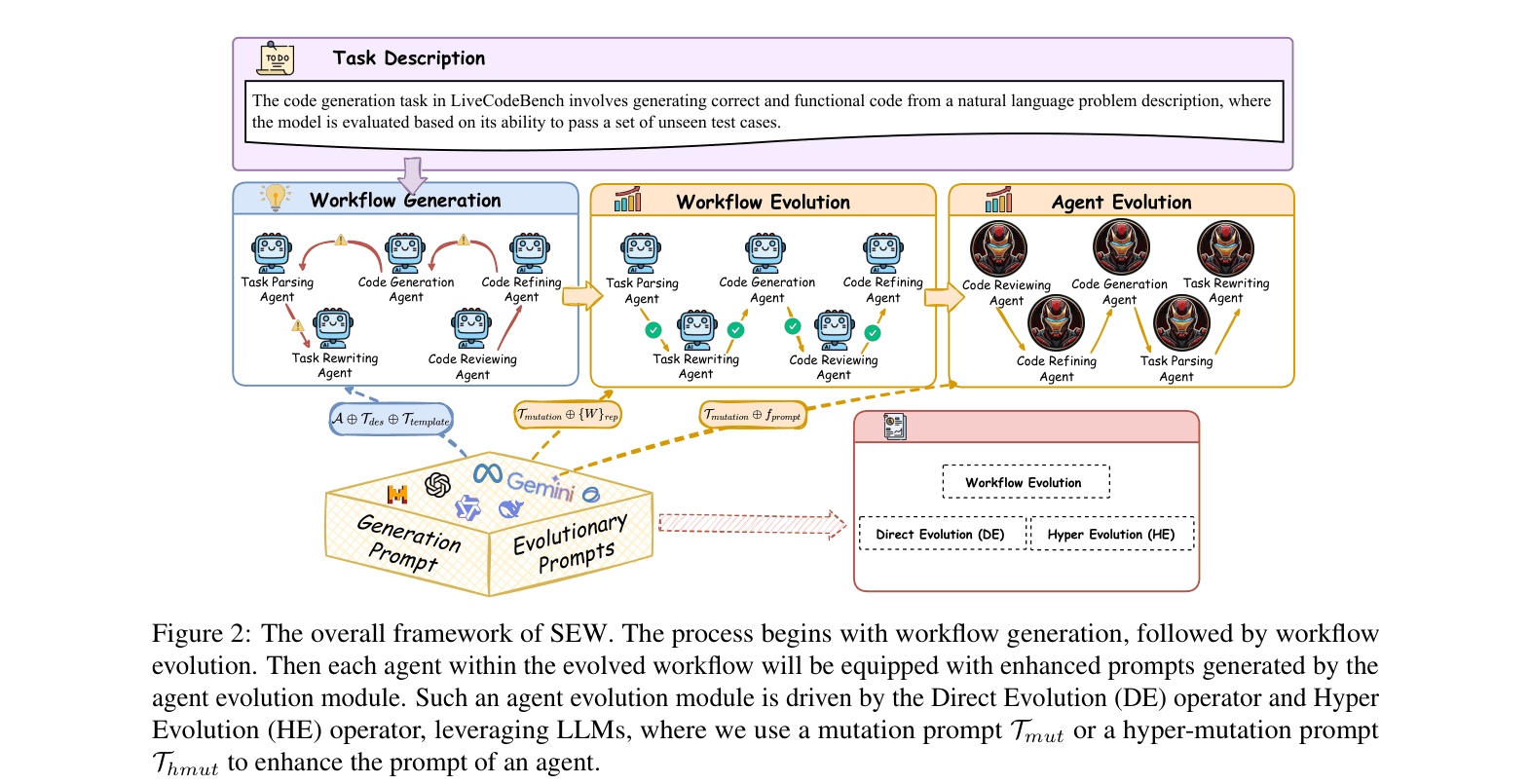
The overall SEW framework pipeline, showing the progression from Workflow Generation to Workflow Evolution, and finally Agent Evolution.
Evaluation Highlights
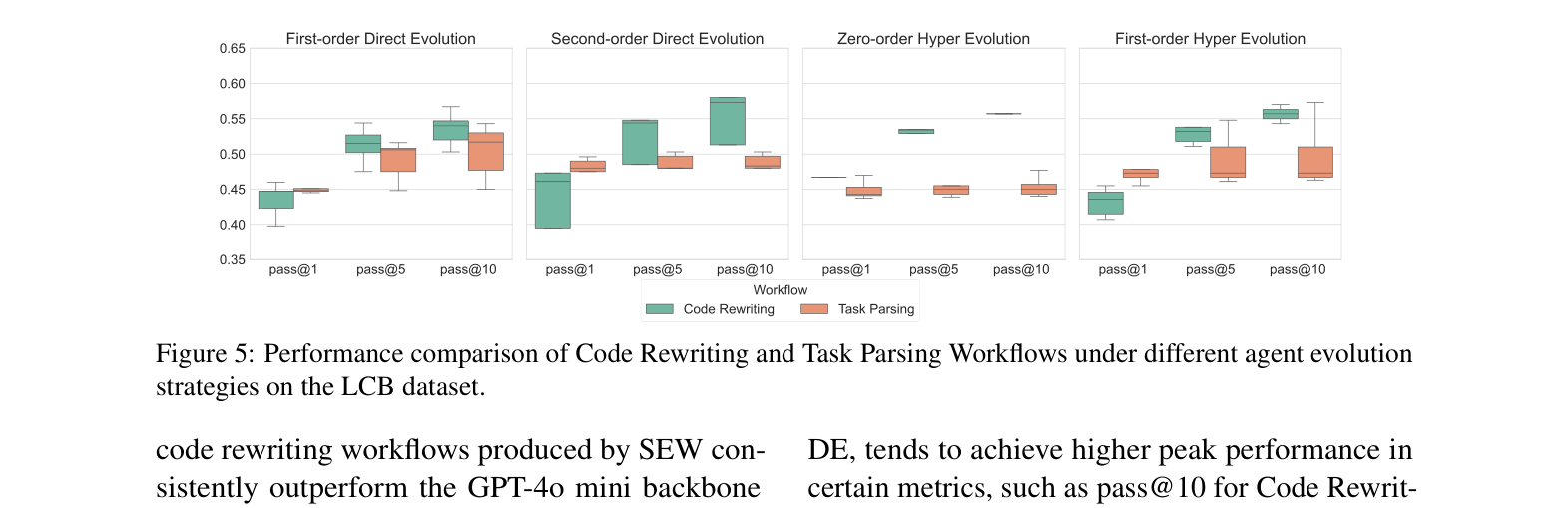
- Achieves 50.9% pass@1 on LiveCodeBench using GPT-4o mini, outperforming the backbone model (38.0%) and PromptBreeder (45.9%)
- Agent evolution module improves the performance of the Task Parsing Workflow by 20.3% on LiveCodeBench compared to using only workflow evolution
- Demonstrates that CoRE representation yields the highest Generation Successful Rate (72.7%) compared to Python (29.1%) and BPMN (47.3%)
Breakthrough Assessment
8/10
Significant step in automating agent design. The rigorous comparison of workflow representations (CoRE vs BPMN) and the dual-layer evolution (workflow + agent) provide a robust framework for self-improving systems.