📊 Experiments & Results
Evaluation Setup
Retrospective empirical analysis of GitHub Pull Requests.
Benchmarks:
- AIDev-pop dataset subset (Real-world Pull Request submission)
Metrics:
- Merge Rate (%)
- Rejection Reason prevalence
- Cliff's delta (effect size for code/process metrics)
- Odds Ratios (logistic regression)
- Statistical methodology: Cliff's delta for effect size; Logistic regression for predictive modeling; Cohen's kappa for inter-rater reliability.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Merge rates vary significantly by agent type and task category. | ||||
| Merge Rate | Merge Rate (%) | 43.04 | 82.59 | +39.55 |
| Task Type Analysis | Merge Rate (%) | 55 | 84 | +29 |
| Quantitative differences between merged and not-merged PRs show that failures are associated with larger changes and CI breaks. | ||||
| Comparison of Merged vs Not-Merged | Cliff's delta (LOC Changes) | 0 | 0.17 | 0.17 |
| Comparison of Merged vs Not-Merged | Cliff's delta (CI Failures) | 0 | 0.24 | 0.24 |
| Qualitative analysis of 600 rejected PRs reveals the primary reasons for failure. | ||||
| Rejection Reasons | Prevalence (%) | 0 | 38 | 38 |
Experiment Figures
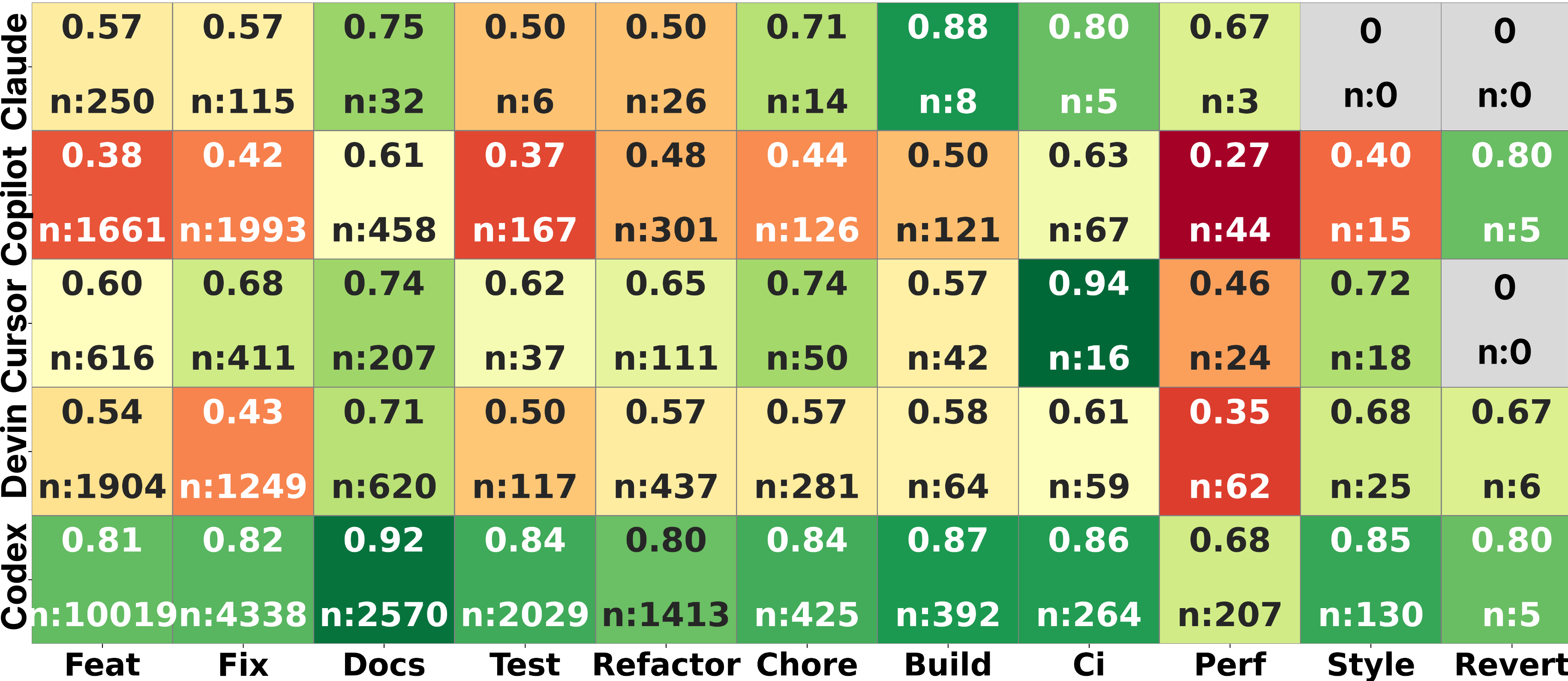
Heatmap of merge rates across 5 agents and 11 task types.
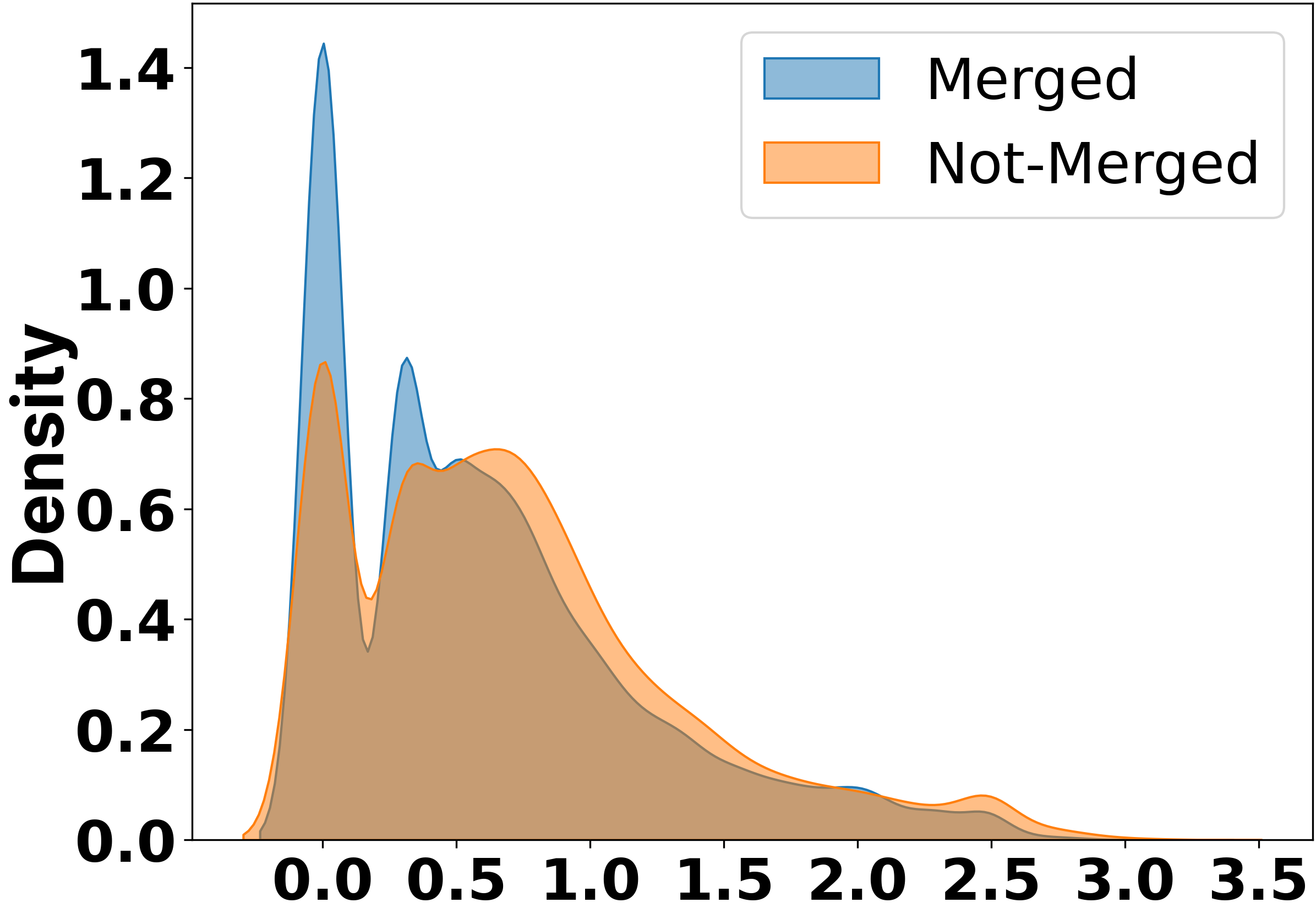
Kernel density plots comparing Merged vs. Not-Merged PRs for #LOC, #Files, and #CI Failures.
Main Takeaways
- Agents struggle with complex logic: 'Performance' and 'Bug-fix' tasks have the lowest merge rates, while rote tasks like 'Documentation' and 'CI' updates succeed most often.
- Socio-technical misalignment is a major blocker: 38% of failures are due to reviewer abandonment (no engagement), suggesting agents fail to signal value or trustworthiness.
- Coordination failure: 23% of rejections are duplicates, indicating agents lack awareness of existing PRs or ongoing work.
- Logistic regression confirms that larger code changes and CI failures strongly predict rejection; each failed CI check reduces merge odds by ~15%.