📝 Paper Summary
Agentic RAG pipeline
Self-evolving Agentic reasoning
The paper defines Agentic Deep Research as a new paradigm where LLMs use reinforcement learning and test-time scaling to autonomously plan, execute, and refine complex multi-step information searches.
Core Problem
Traditional keyword search and naive RAG systems fail to handle complex, multi-faceted queries because they cannot autonomously plan research paths or iteratively refine their understanding based on intermediate findings.
Why it matters:
- Standard search engines overwhelm users with links for complex topics, requiring heavy manual synthesis
- Naive RAG systems (single retrieval step) often retrieve irrelevant context or hallucinate when reasoning requires multiple hops
- Current LLMs lack the strategic ability to recognize when initial search results are insufficient and automatically correct course
Concrete Example:
For a question like 'What was the conference of the Vermont Catamounts men's soccer team formerly known as from 1988 to 1996?', a naive RAG might search for the team generally and miss the specific historical timeframe. An Agentic Deep Research system would reason that it needs historical conference data, perform a search, realize the name changed, and iteratively search for that specific era's records.
Key Novelty
Agentic Deep Research Paradigm & Test-Time Scaling (TTS) Law for Search
- Proposes a paradigm shift where reasoning is not just post-processing but the driver of the search process, deciding when and what to query via a dynamic feedback loop
- Formalizes a 'Test-Time Scaling Law for Deep Research', hypothesizing that increasing inference-time computation (reasoning depth) leads to better search outcomes and synthesis
- advocates for Reinforcement Learning (RL) over simple prompting to incentivize agents to explore and optimize search strategies autonomously
Architecture
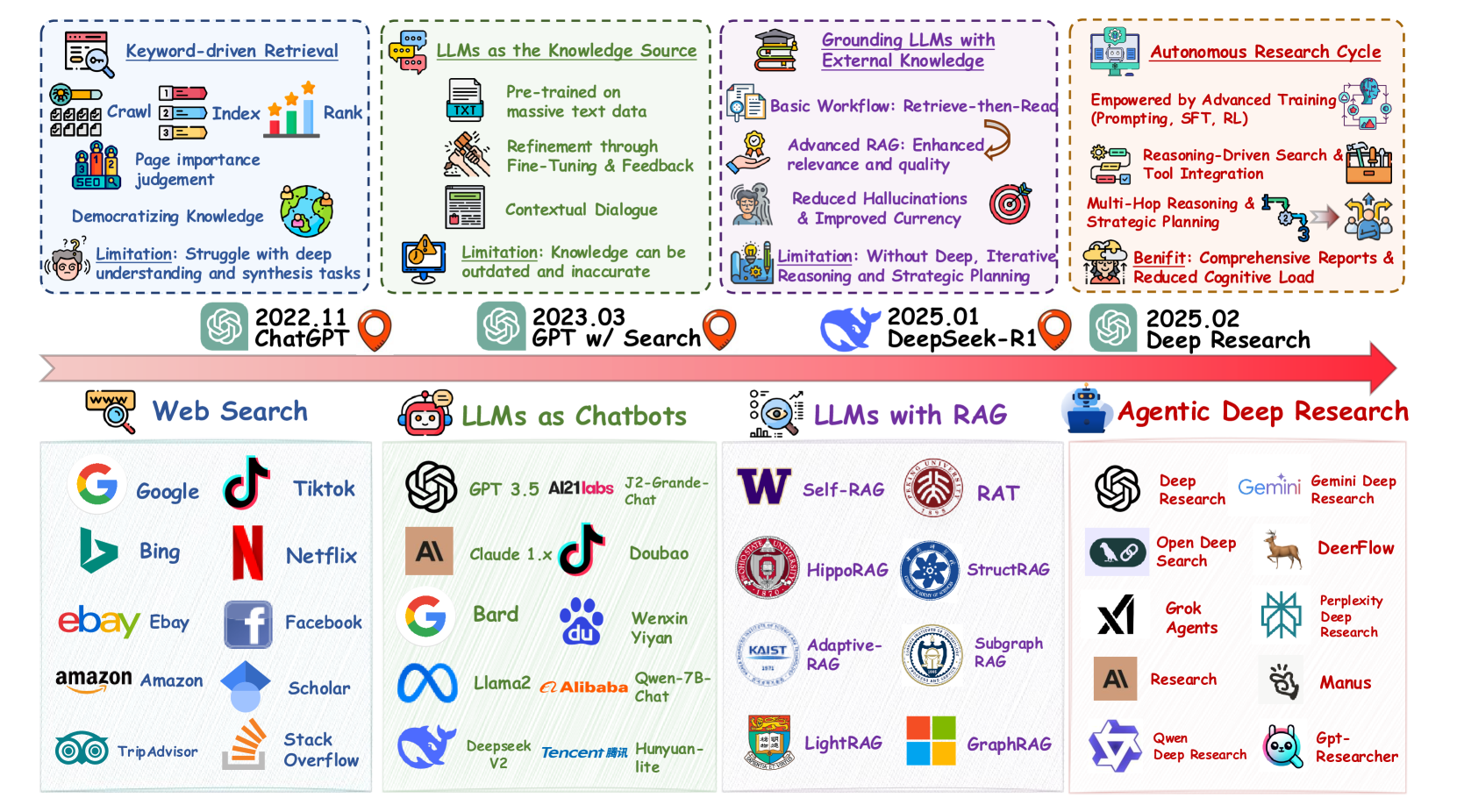
Evolution of search paradigms from Web Search to LLMs as Chatbots, to LLMs with RAG, and finally to Agentic Deep Research.
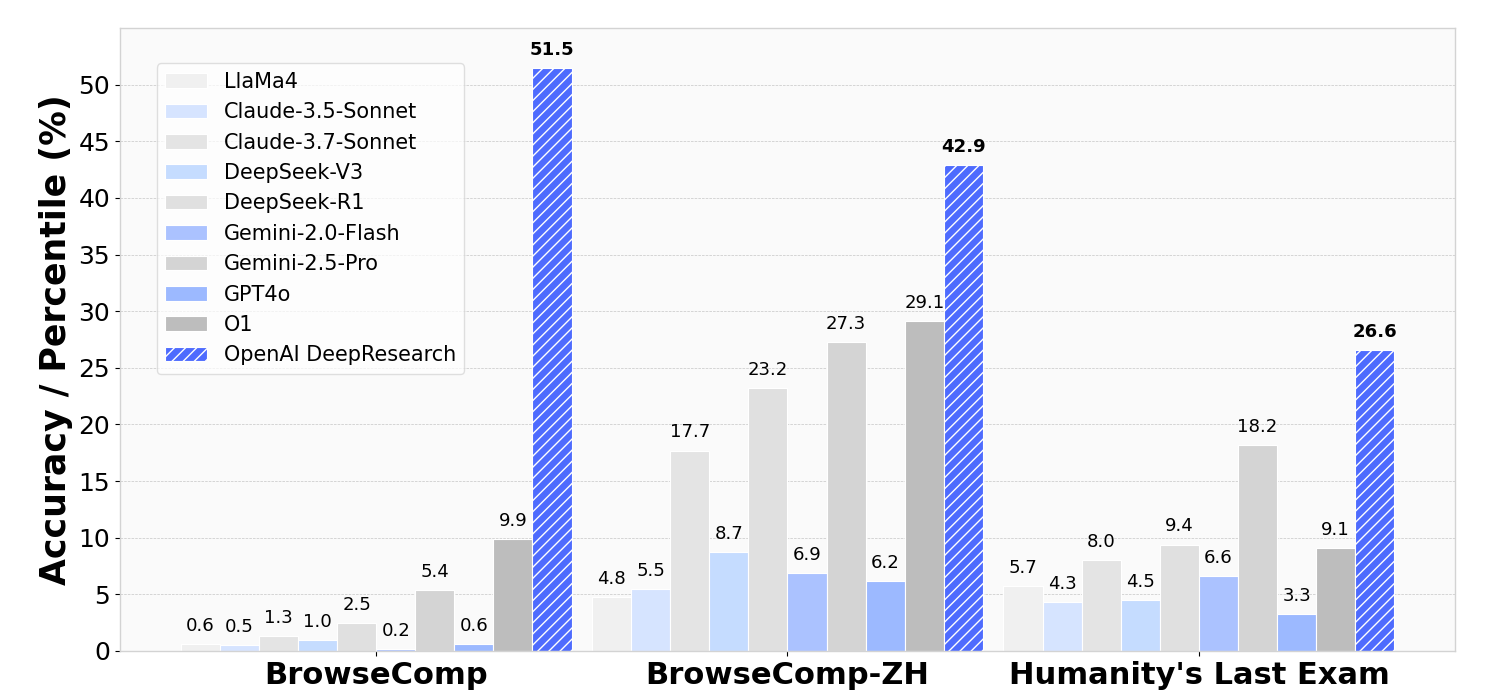
Evaluation Highlights
- OpenAI Deep Research agent achieves 51.5% on BrowseComp, significantly outperforming standard LLMs (typically <10%)
- On the Humanity's Last Exam (HLE) benchmark, OpenAI Deep Research scores 26.6% compared to standard LLMs scoring under 20%
- Achieves 42.9% on BrowseComp-ZH (Chinese web search), demonstrating cross-lingual deep research capabilities
Breakthrough Assessment
9/10
This is a position paper that defines a major paradigm shift. While it relies on existing models (like OpenAI's) for results, its formalization of 'Agentic Deep Research' and the TTS law for search unifies fragmented efforts into a coherent field.