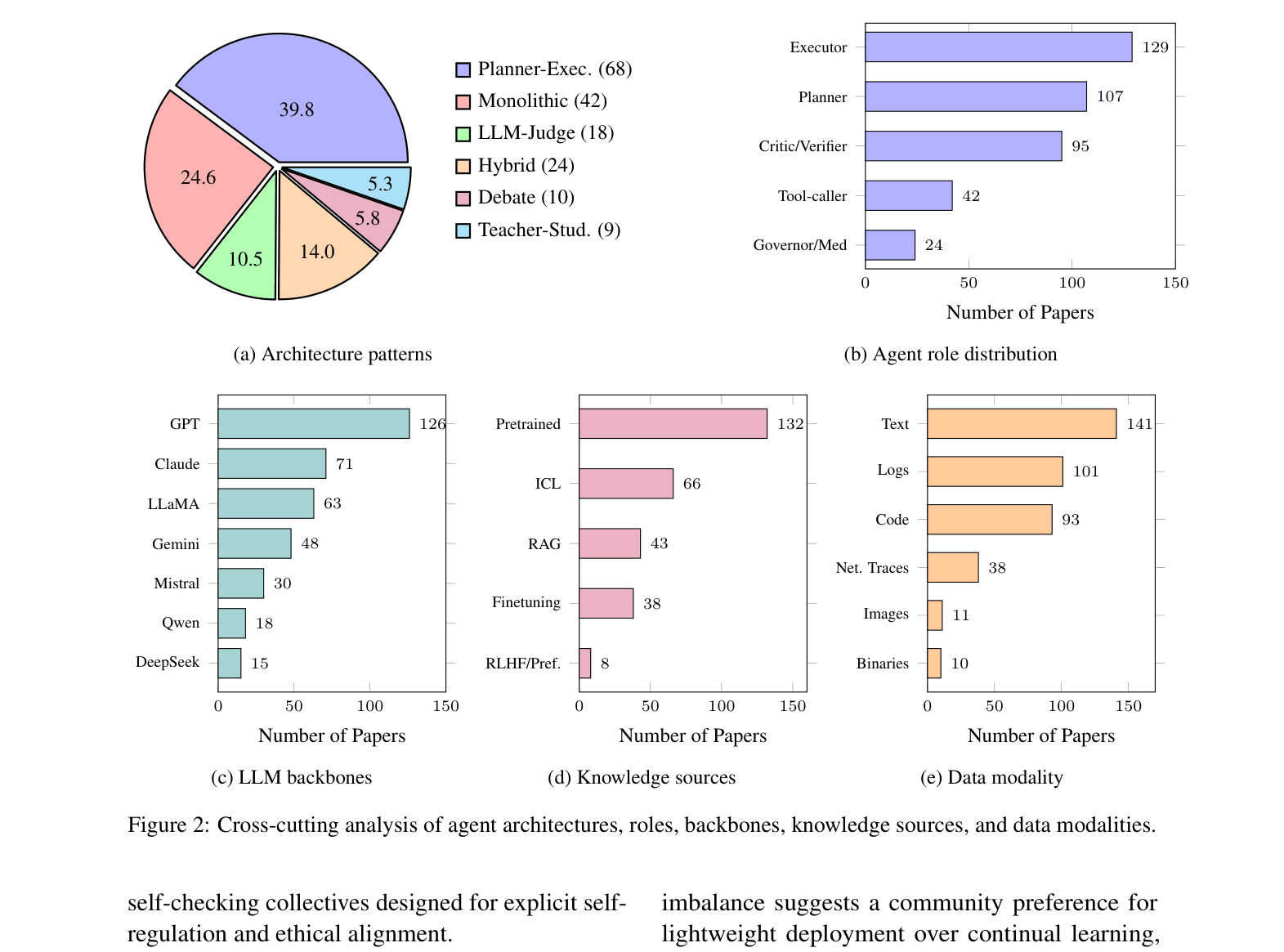📝 Paper Summary
Agentic AI Security
Adversarial Attacks on Agents
Agent Defense Mechanisms
This survey structures the fragmented landscape of over 160 agentic security papers into three pillars—applications, threats, and defenses—revealing critical gaps like the monopoly of GPT backbones and underexplored modalities.
Core Problem
The rapid transition from passive LLMs to autonomous agents has introduced severe new vulnerabilities (e.g., indirect injection, goal hijacking) that existing safety measures for standalone models cannot address.
Why it matters:
- Agents now execute actions in external environments, meaning attacks can cause tangible damage (e.g., executing malware, leaking private data) rather than just generating bad text
- Current research is fragmented into isolated clusters (red teaming, governance, jailbreaking) without a unified framework connecting capabilities to their specific vulnerabilities and defenses
- Standard LLM safety alignment (refusal training) does not reliably transfer to agentic contexts, leaving critical infrastructure vulnerable to simple jailbreaks
Concrete Example:
A 'split-payload injection' attack can compromise an agent simply by embedding malicious instructions across different parts of a website. When the agent processes the site, it combines these parts and executes the payload, a vulnerability specific to the agent's information aggregation process that standalone LLMs don't face.
Key Novelty
Three-Pillar Taxonomy of Agentic Security
- Structures the field into Applications (Red/Blue Teaming), Threats (Injection, Poisoning, Manipulation), and Defenses (Secure-by-Design, Runtime Protection)
- Provides a cross-cutting analysis identifying structural trends, such as the shift from monolithic to planner-executor architectures and the risky monopoly of closed-source backbones (GPT-4)
Architecture
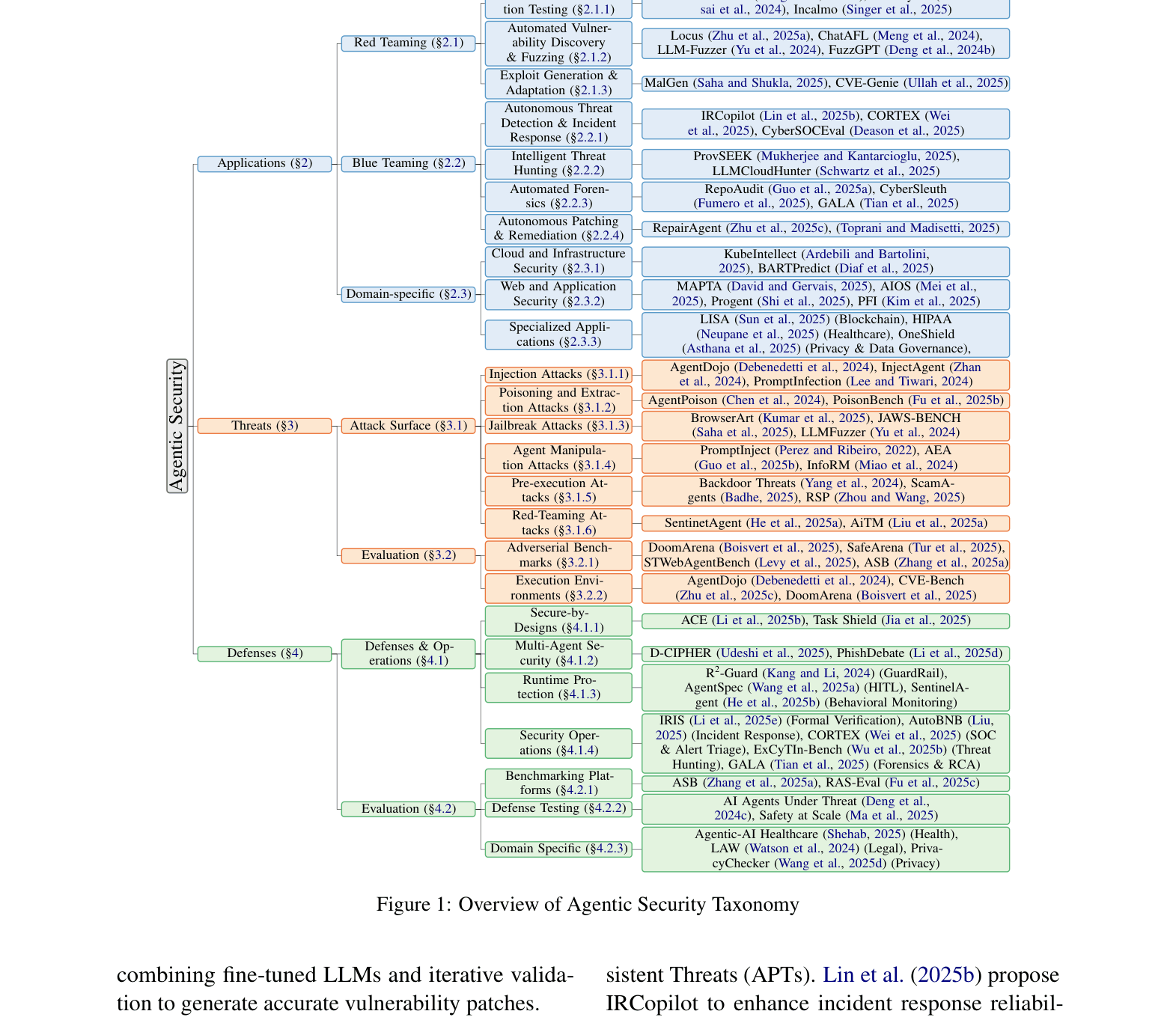
A comprehensive taxonomy tree of Agentic Security, organized into three main branches: Applications, Threats, and Defenses
Evaluation Highlights
- Identifies that 83% of surveyed studies rely on GPT-family models, creating a dangerous single-point-of-failure risk for the ecosystem
- reveals that planner-executor architectures (39.8%) and hybrid models (14%) are displacing monolithic agents, introducing new modular attack surfaces
- Highlights that defense mechanisms are currently fragile; adversarial training often degrades task utility, and simple jailbreaks remain effective against complex agents
Breakthrough Assessment
9/10
The first holistic survey covering the entire agentic security lifecycle. It unifies scattered literature into a coherent framework, crucial for defining future research directions in this rapidly emerging field.