📝 Paper Summary
Software Engineering Agents
Reinforcement Learning for Agents
Agent-RLVR enables effective reinforcement learning for software engineering agents by incorporating teacher guidance (hints, plans, environment feedback) during training to overcome sparse reward landscapes in complex, multi-step tasks.
Core Problem
Standard RLVR fails in agentic settings because multi-step reasoning tasks have extremely sparse rewards; the probability of an agent independently discovering a correct trajectory is too low to provide a learning signal.
Why it matters:
- Frontier LLMs struggle with high failure rates in complex, multi-turn environments like software engineering
- Interacting with real execution environments is computationally expensive, making inefficient exploration prohibitive
- Existing RLVR success in math/coding (single-turn) does not translate to agentic workflows requiring navigation and sequential decision-making
Concrete Example:
In a software engineering task requiring navigation through a large repo to fix a bug, a standard agent might fail to locate the relevant file 100% of the time, receiving zero reward and learning nothing. Agent-RLVR provides a 'hint' (guidance) pointing to the correct file, allowing the agent to proceed, succeed, and generate a positive trajectory for RL optimization.
Key Novelty
Agent Guidance-Augmented RLVR
- Injects 'guidance' (plans, file pointers, error corrections) during the training phase to actively steer agents toward successful trajectories when they would otherwise fail
- Uses successful guided trajectories to update the policy via Direct Preference Optimization (DPO), allowing the model to learn from successes it couldn't originally achieve on its own
- Curates a dataset of 817 environments complete with problem statements and expert guidance specifically for this training loop
Architecture
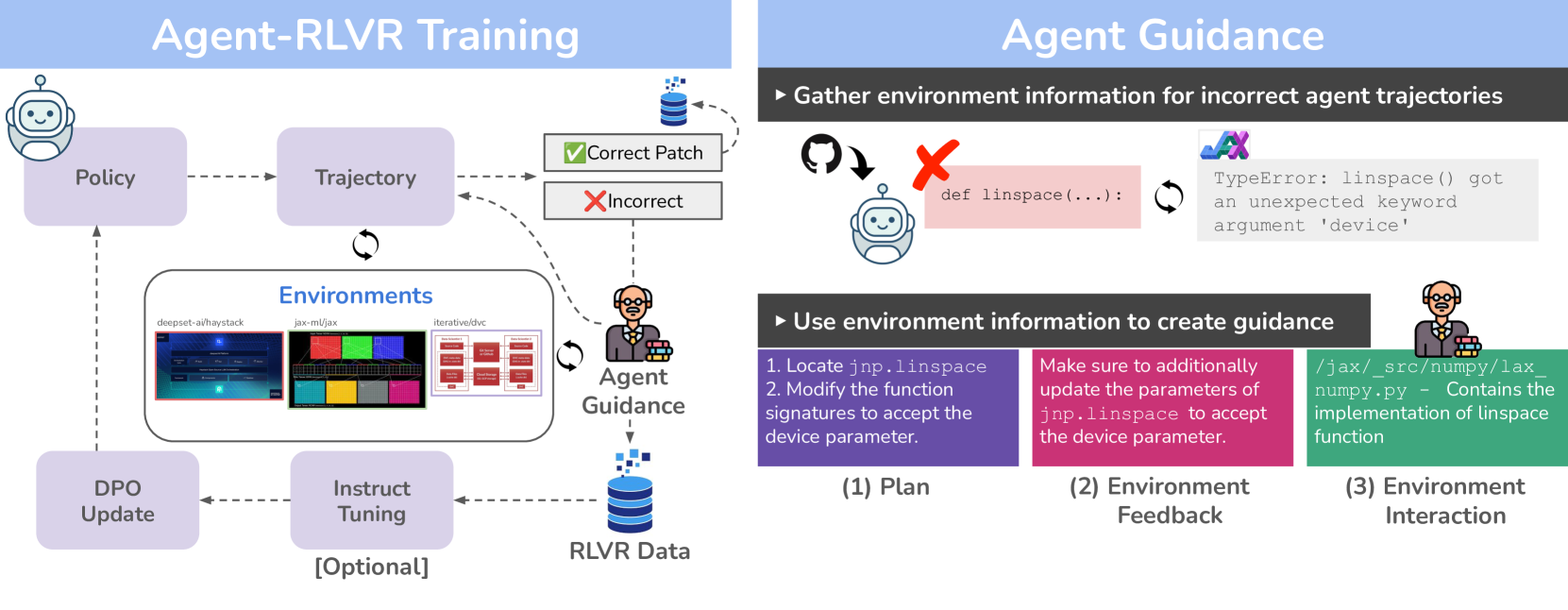
The Agent-RLVR training loop illustrating the interaction between the agent, the environment, and the guidance mechanism.
Evaluation Highlights
- Improves Qwen-2.5-72B-Instruct Pass@1 from 9.4% to 22.4% on SWE-Bench Verified (main result)
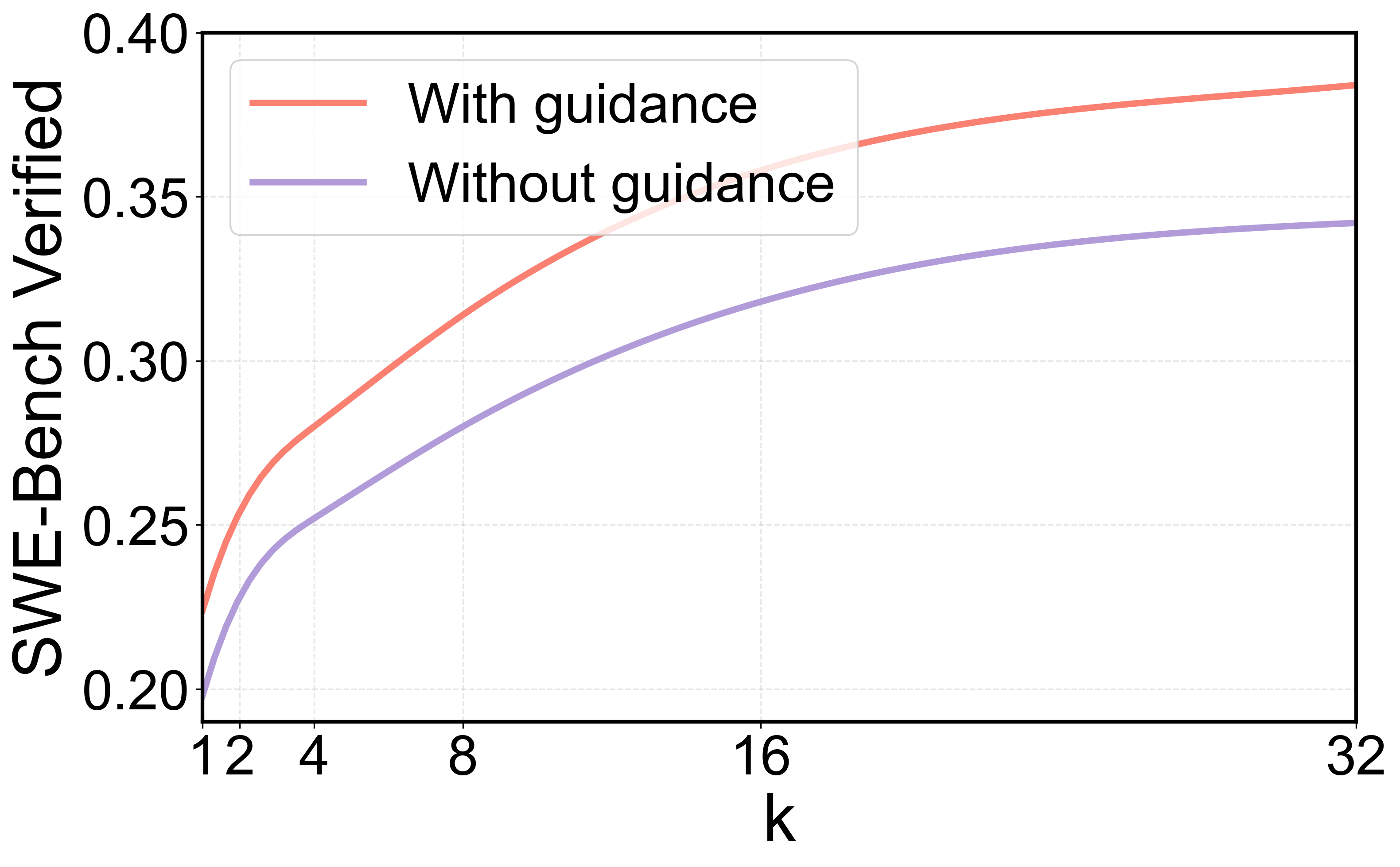
- Guidance model improves Pass@32 from 34.2% to 38.4%, showing that guidance helps exploration
- Training a reward model on the RLVR data further boosts Pass@1 to 27.8% (using Best-of-32 ranking)
Breakthrough Assessment
8/10
Significantly adapts RLVR (usually for math) to complex agentic tasks. The jump from 9.4% to 22.4% with a relatively small dataset (817 tasks) is substantial and demonstrates high data efficiency.