📝 Paper Summary
Self-evolving Agentic reasoning
Multi-call tool use with flexible plan
AgentFounder introduces Agentic Continual Pre-training as an intermediate scaling layer to inject tool-use and reasoning capabilities into foundation models before post-training, resolving optimization conflicts in deep research agents.
Core Problem
General-purpose foundation models lack inherent agentic inductive biases, forcing post-training (SFT/RL) to simultaneously learn capabilities and alignment, which creates optimization tensions and leads to underperformance in complex agentic tasks.
Why it matters:
- Existing open-source agents (e.g., WebSailor, DeepSeek-V3.1) significantly lag behind OpenAI's Deep Research (e.g., 30.0 vs 51.5 on BrowseComp) because they rely on general-purpose base models.
- SFT relies on high-quality complete trajectories which are scarce and hard to define for long-horizon tasks.
- Current post-training locks models into imitating specific patterns rather than developing flexible decision-making capabilities needed for unpredictable environments.
Concrete Example:
When training a deep research agent, standard SFT might force a model to memorize a specific search query sequence for a complex question. However, if a search tool fails or returns unexpected results during inference, the model lacks the fundamental decision-making capability to adapt its strategy because it only learned to mimic a fixed path, not the underlying reasoning process.
Key Novelty
Agentic Continual Pre-training (Agentic CPT)
- Inserts a massive pre-training stage (300B+ tokens) between general pre-training and post-training, focused exclusively on agentic data (reasoning, tool use, planning).
- Generates synthetic training data without expensive API calls by restructuring static knowledge into 'Question-Planning-Action' tuples (First-order Action Synthesis).
- Transforms existing trajectories into multi-step decision-making data by expanding options at each step and explicitly modeling the choice process (Higher-order Action Synthesis).
Architecture
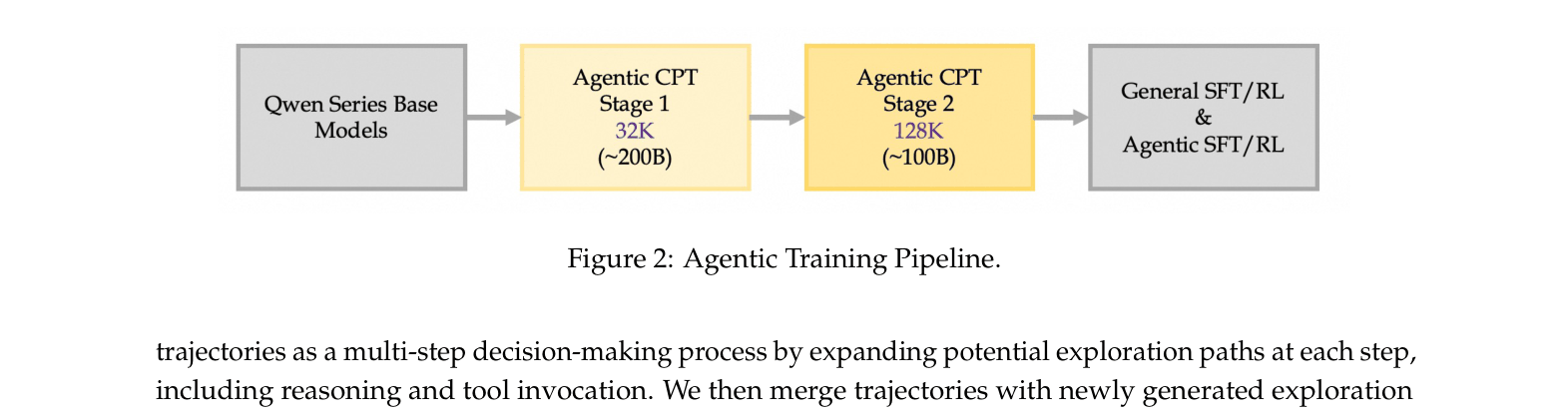
The complete Agentic Training Pipeline, showing the progression from base model through two stages of Agentic CPT to Post-training.
Evaluation Highlights
- +10.0% improvement on BrowseComp-en over DeepSeek-V3.1 (39.9 vs 30.0), approaching closed-source OpenAI Deep Research performance.
- Achieves 31.5% Pass@1 on the expert-level HLE benchmark, surpassing all reported closed-source models including OpenAI Deep Research (26.6) and Kimi-Researcher (26.9).
- Demonstrates strong scaling laws for agentic capabilities, with performance steadily increasing across data volume (up to 315B tokens) and model size (1B to 30B).
Breakthrough Assessment
9/10
Proposes a fundamental shift in the training pipeline for agents (Continual Pre-training instead of just SFT/RL). Achieves SOTA results on difficult benchmarks like HLE and BrowseComp, significantly closing the gap with proprietary models.