📝 Paper Summary
Autonomous Agents
Reinforcement Learning (RL)
Tool Use
DeepTravel is an end-to-end reinforcement learning framework that trains autonomous travel planning agents using a robust sandbox environment, hierarchical reward modeling, and experience replay to outperform larger reasoning models.
Core Problem
Existing travel planning agents rely on rigid, hand-crafted prompts or fixed workflows, making them brittle in dynamic environments and unable to recover from tool failures or adapt to open-ended user queries.
Why it matters:
- Dynamic Environment: Real-world travel data (prices, availability) fluctuates constantly, causing inconsistent outputs that hinder stable training.
- Open-Ended Tasks: Travel planning lacks explicit ground truth (unlike math or code), making it difficult to verify outcomes and construct reliable reward signals.
- Labor Intensive: Manual prompt engineering and fixed pipelines fail to scale or adapt to new query types effectively.
Concrete Example:
A user asks for a 'three-day trip from Shanghai to Beijing.' A standard prompt-based agent might fail if a specific flight is unavailable and cannot autonomously re-plan. DeepTravel agents, trained in a sandbox, learn to catch the error, adjust dates or transport modes, and verify the new plan against the user's constraints.
Key Novelty
DeepTravel Framework
- Robust Sandbox: Caches real-world API data (flights, hotels) to simulate dynamic environments while overcoming rate limits, enabling stable trial-and-error learning.
- Hierarchical Reward Modeling: Splits verification into a coarse 'trajectory-level' check for feasibility and a fine-grained 'turn-level' check for consistency with tool outputs.
- Reply-Augmented RL: Uses a failure experience buffer to periodically replay hard cases, allowing the agent to refine reasoning on previously failed queries.
Architecture
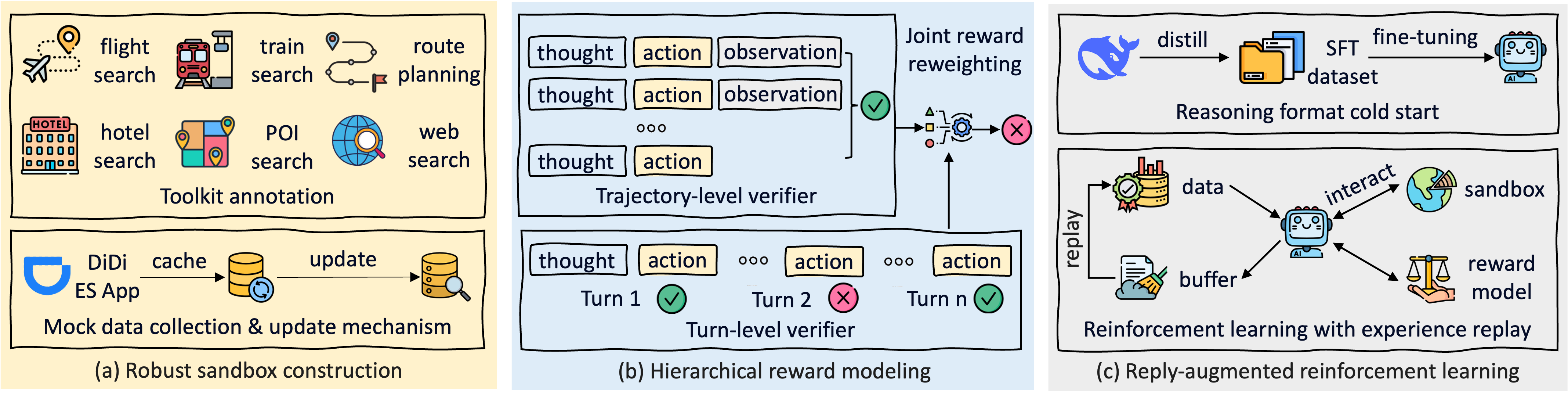
The overall DeepTravel pipeline, including Sandbox Construction, Hierarchical Reward Modeling, and Reply-Augmented RL.
Evaluation Highlights
- DeepTravel enables a small Qwen2.5-32B model to significantly outperform frontier models like OpenAI-o1 and DeepSeek-R1 in travel planning tasks.
- Achieves higher pass rates on both online real-world user data and offline synthetic data compared to GRPO and DAPO baselines.
- Demonstrates successful deployment in the DiDi Enterprise Solutions App.
Breakthrough Assessment
8/10
Significant for applying agentic RL to an open-ended, dynamic domain (travel) with a complete framework including sandbox, reward modeling, and deployment, outperforming larger closed-source models.