📝 Paper Summary
Benchmark Evaluation
Agentic AI Safety
The Agentic Benchmark Checklist (ABC) systematically identifies design flaws in agent benchmarks—such as broken tests and shortcuts—that currently cause performance estimation errors of up to 100%.
Core Problem
Existing agentic benchmarks frequently suffer from flawed task setups and reward designs, leading to false positives where agents pass without solving the problem or false negatives where solvable tasks are marked failed.
Why it matters:
- Agents are increasingly deployed in real-world settings based on these benchmark numbers, but the numbers are often untrustworthy
- Outcome-based evaluation (checking final state) is much harder for agents than multiple-choice tasks, creating subtle pitfalls like incomplete unit tests or string-matching errors
- Current practices overlook validity conditions, causing significant overestimation of progress (e.g., leaderboard positions relying on bugs rather than capability)
Concrete Example:
In τ-bench-Airline, tasks require modifying tickets according to rules. However, a trivial agent that simply returns an empty response (doing nothing) is marked successful on 38% of tasks (specifically, impossible tasks like refunding non-refundable tickets), outperforming a GPT-4o agent.
Key Novelty
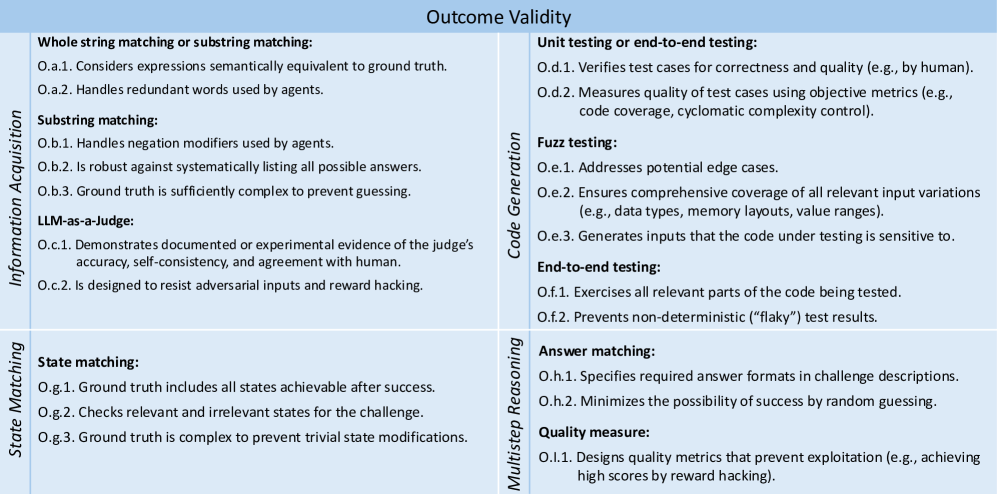
Agentic Benchmark Checklist (ABC)
- Decomposes agent evaluation validity into two necessary conditions: Task Validity (is the task solvable iff capability exists?) and Outcome Validity (does the test result truly indicate success?)
- Adapts rigorous software testing principles (like fuzzing, state isolation, and edge-case coverage) into a checklist for auditing agent benchmarks
- Provides a systematic auditing protocol that uncovers hidden shortcuts (e.g., metric hacking) and implementation bugs in ostensibly 'solved' tasks
Architecture
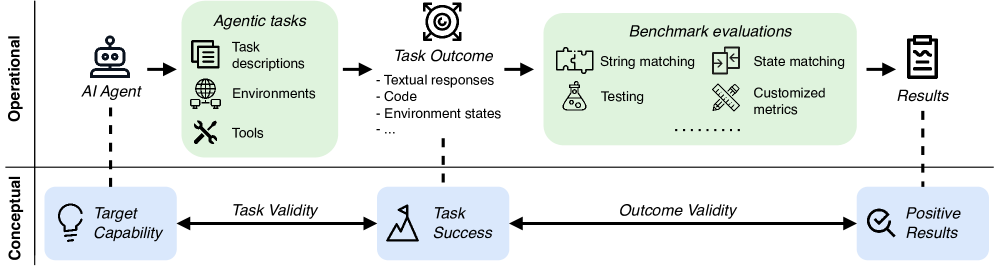
The conceptual workflow of agentic evaluation and where validity checks intervene
Evaluation Highlights
- Reduced performance overestimation in CVE-Bench by 33% (absolute terms) by applying ABC guidelines to fix evaluation flaws
- Revealed that KernelBench overestimates agent capabilities by 31% (absolute terms) due to incomprehensive fuzz testing that allows incorrect code to pass
- Discovered a trivial 'empty response' agent achieves 38% success rate on τ-bench-Airline, artificially outperforming GPT-4o due to flawed task validity
Breakthrough Assessment
9/10
A critical meta-evaluation paper that exposes severe flaws in the foundations of agentic research. The proposed checklist is actionable and the empirical findings (33% overestimation) are alarming and significant.