📊 Experiments & Results
Evaluation Setup
Multi-trial execution of agents on standard benchmarks to measure variance
Benchmarks:
- GAIA (Agentic capabilities (reasoning, tool use, multi-step))
- FRAMES (Retrieval and factuality (RAG scenarios))
Metrics:
- Intraclass Correlation Coefficient (ICC)
- Accuracy (with 95% Confidence Intervals)
- Within-query variance
- Between-query variance
- Statistical methodology: ICC(1,1) one-way random effects model; Standard Error of the Mean for accuracy; McNemar's test for paired comparisons
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| ICC analysis reveals that agentic tasks (GAIA) generally exhibit lower and more variable reliability than retrieval/reasoning tasks (FRAMES), reflecting the higher stochasticity in multi-step agent actions. | ||||
| FRAMES | ICC Range | N/A | 0.4955–0.7118 | N/A |
| GAIA | ICC Range | N/A | 0.304–0.774 | N/A |
| Variance reduction analysis demonstrates that spreading compute budget across more items is more efficient than running many trials on fewer items. | ||||
| Theoretical Simulation | Standard Error Reduction | 1.0 | 0.32 | -0.68 |
Experiment Figures
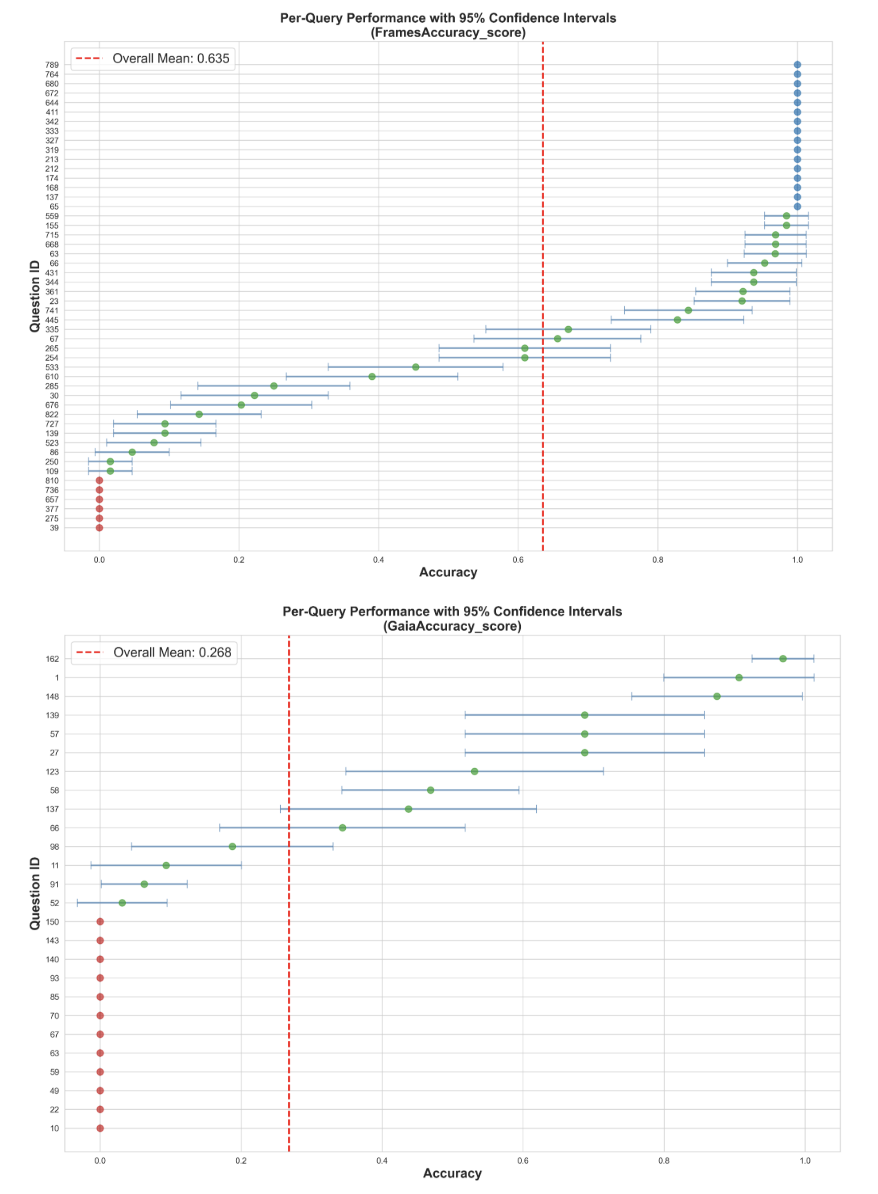
Per-question accuracy estimates with 95% confidence intervals sorted by difficulty
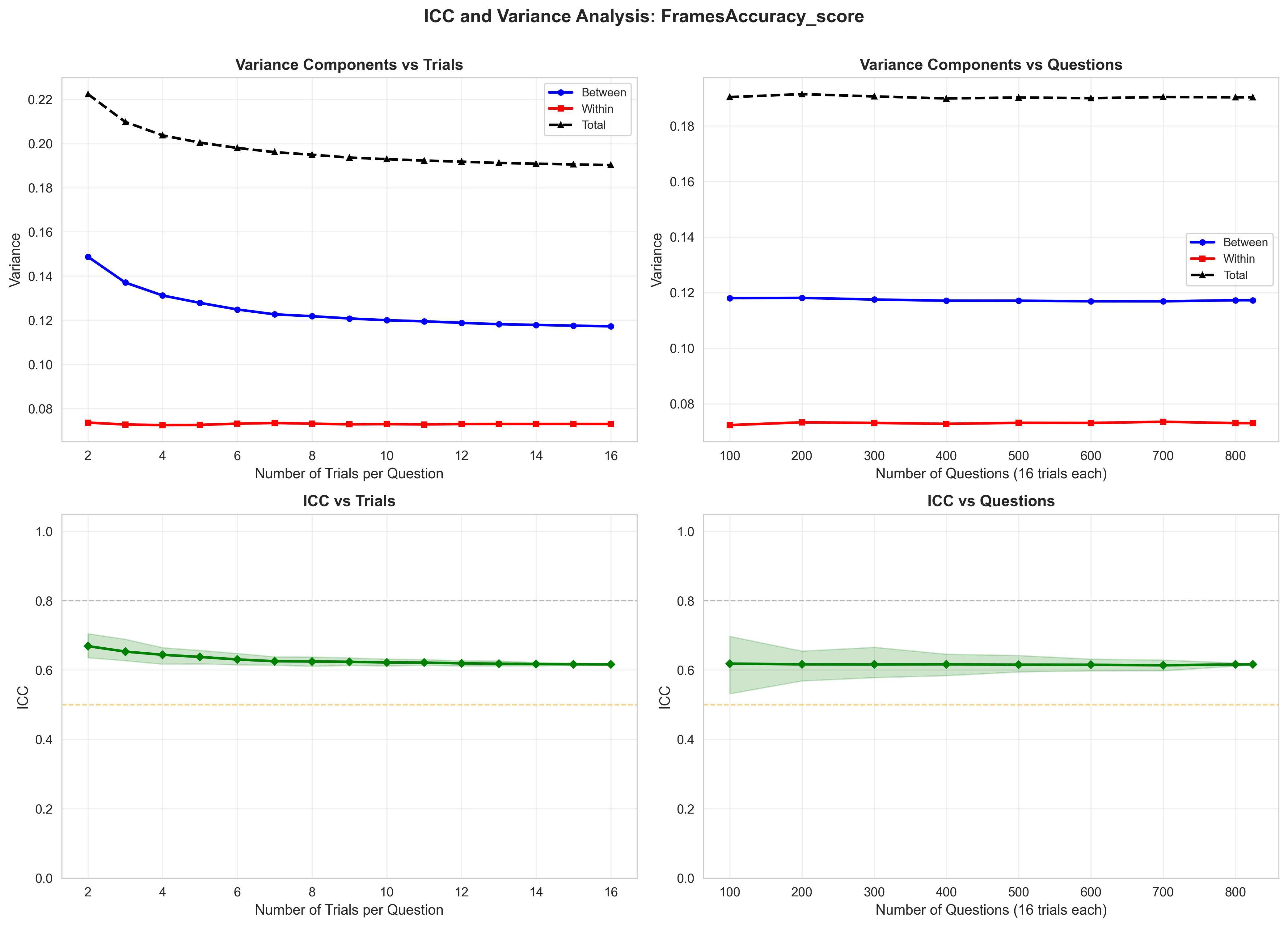
Standard Error of accuracy estimate as a function of trials (T) vs items (n) for a fixed budget
Main Takeaways
- Evaluation stability varies significantly with task complexity: GAIA (agentic) is less stable than FRAMES (RAG).
- Single-run accuracy is an unreliable metric for agentic systems; trustworthy improvements require improvements in ICC (consistency) as well.
- Optimal evaluation strategy prioritizes maximizing the number of tasks (n) over the number of trials (T) until tasks are exhausted, to minimize standard error.
- ICC convergence analysis suggests n=8–16 trials are needed for structured tasks, while n≥32 is needed for complex reasoning to get stable estimates.