📝 Paper Summary
Agentic AI
Observation Management (OM)
Thought Management (TM)
Agent-Omit trains LLM agents to autonomously decide when to skip reasoning steps or discard past observations during multi-turn interactions, balancing efficiency with task success.
Core Problem
Existing LLM agents generate redundant reasoning thoughts for simple actions and accumulate excessive observation contexts over long trajectories, wasting tokens and slowing inference.
Why it matters:
- Thought and observation tokens dominate agent costs (e.g., ~97% of tokens in WebShop), while actual actions account for only ~3%
- Prior methods compress trajectories equally or use static heuristics, failing to recognize that the utility of thoughts and observations varies significantly across different turns
- Long contexts with irrelevant observations act as noise that degrades performance in later turns
Concrete Example:
In a shopping task, an agent might generate detailed reasoning for a simple 'click next' action, or retain outdated search results from Turn 1 that are irrelevant to the final answer in Turn 10. Agent-Omit detects this and outputs an empty thought or an omission command.
Key Novelty
Adaptive Omission via Agentic RL
- Treats 'omission' as a learnable action: agents learn to output empty thoughts or specific command tokens to prune history based on the current context's necessity
- Uses a dual-sampling RL strategy that learns from both full trajectories (for final success) and partial trajectories (to learn omission decisions given the pre-omission context)
Architecture
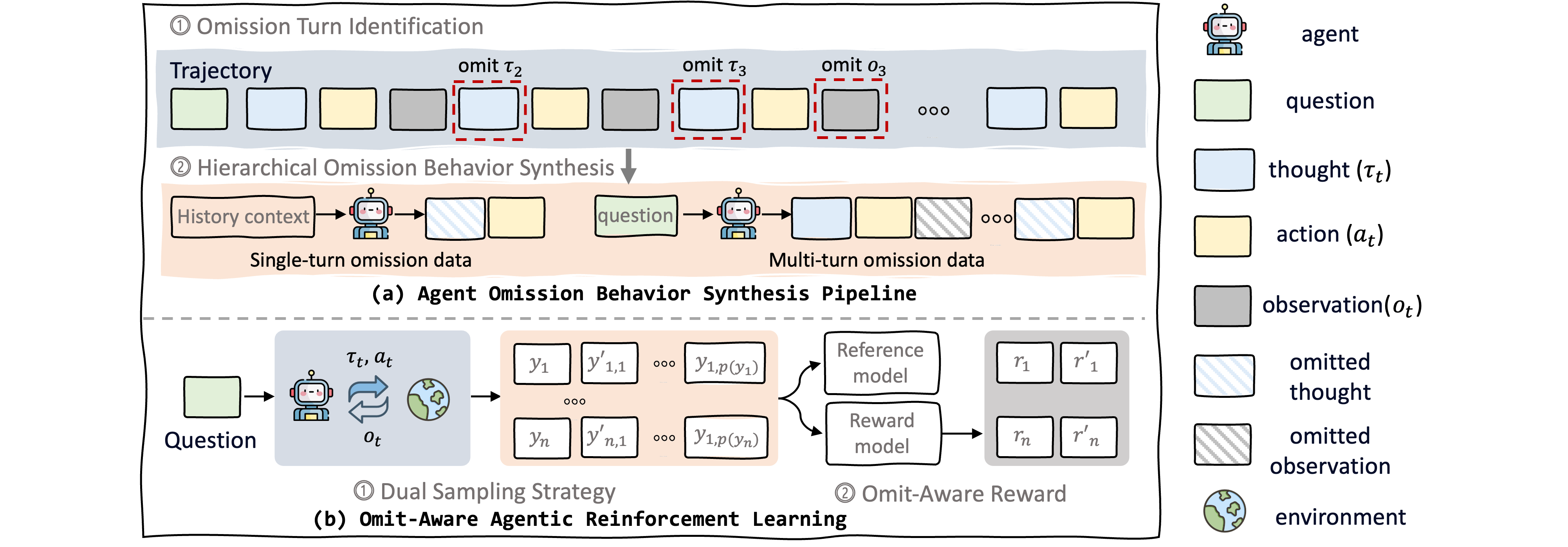
The Agent-Omit framework, showing the two-stage process: (a) synthesizing cold-start data (identifying removable turns via rollouts), and (b) Omit-Aware Agentic RL training with dual sampling.
Evaluation Highlights
- Agent-Omit-8B achieves comparable accuracy to frontier models like DeepSeek-R1 and o3 on 5 benchmarks while substantially reducing token costs
- Outperforms 7 efficient agent baselines (e.g., ToolLight, MEM-Agent) in effectiveness-efficiency trade-offs when applied to Qwen3-8B
- Adaptively omits 3-4 rounds of thoughts/observations per task on average, primarily in intermediate turns where redundancy is highest
Breakthrough Assessment
8/10
Strong methodological contribution by formalizing omission as a policy learned via RL rather than heuristics. Addresses a critical efficiency bottleneck in agentic workflows with solid theoretical backing (KL bounds) and empirical results.

