📝 Paper Summary
Multi-agent
Self-evolving Agentic reasoning
AgenTracer is an automated framework that trains a lightweight model to pinpoint the specific agent and step responsible for multi-agent system failures using counterfactual replay and fault injection.
Core Problem
Multi-agent systems are fragile and prone to failure, but identifying exactly which agent or step caused an error in long, verbose trajectories is difficult for current LLMs.
Why it matters:
- System debugging is currently a manual, labor-intensive process due to the complexity of multi-agent interactions and tool invocations
- Current SOTA reasoning models like DeepSeek-R1 and GPT-4 fail catastrophically at this task (accuracy often <10%), preventing automated self-correction
- Existing failure attribution benchmarks are too small (approx. 200 samples), limiting systematic evaluation and improvement
Concrete Example:
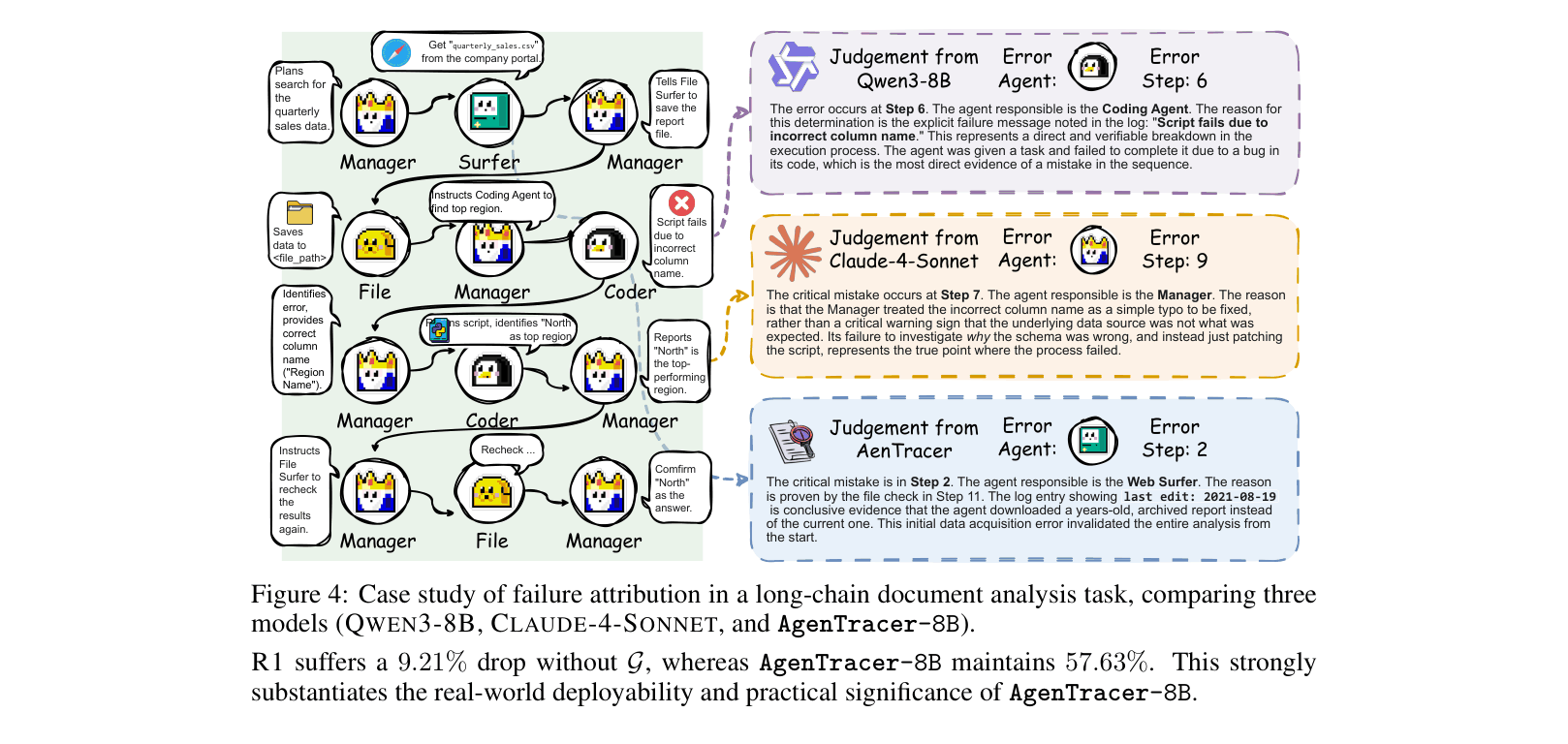
In a document analysis task where the final answer is 'North', Qwen3-8B blames a Coder agent for a script error at Step 6. However, the true root cause was the Web Surfer agent downloading an outdated file at Step 2, which only caused the script to crash later. AgenTracer correctly identifies Step 2.
Key Novelty
AgenTracer (Automated Failure Attribution Framework)
- systematically replaces agent actions with oracle guidance (counterfactual replay) to find the exact step where failure becomes inevitable
- Synthetically generates training data by corrupting successful trajectories (fault injection), creating pairs of 'failed trajectory' and 'known root cause'
- Trains a lightweight model (AgenTracer-8B) using Reinforcement Learning with a multi-granular reward that scores both agent identification and temporal proximity to the error step
Architecture
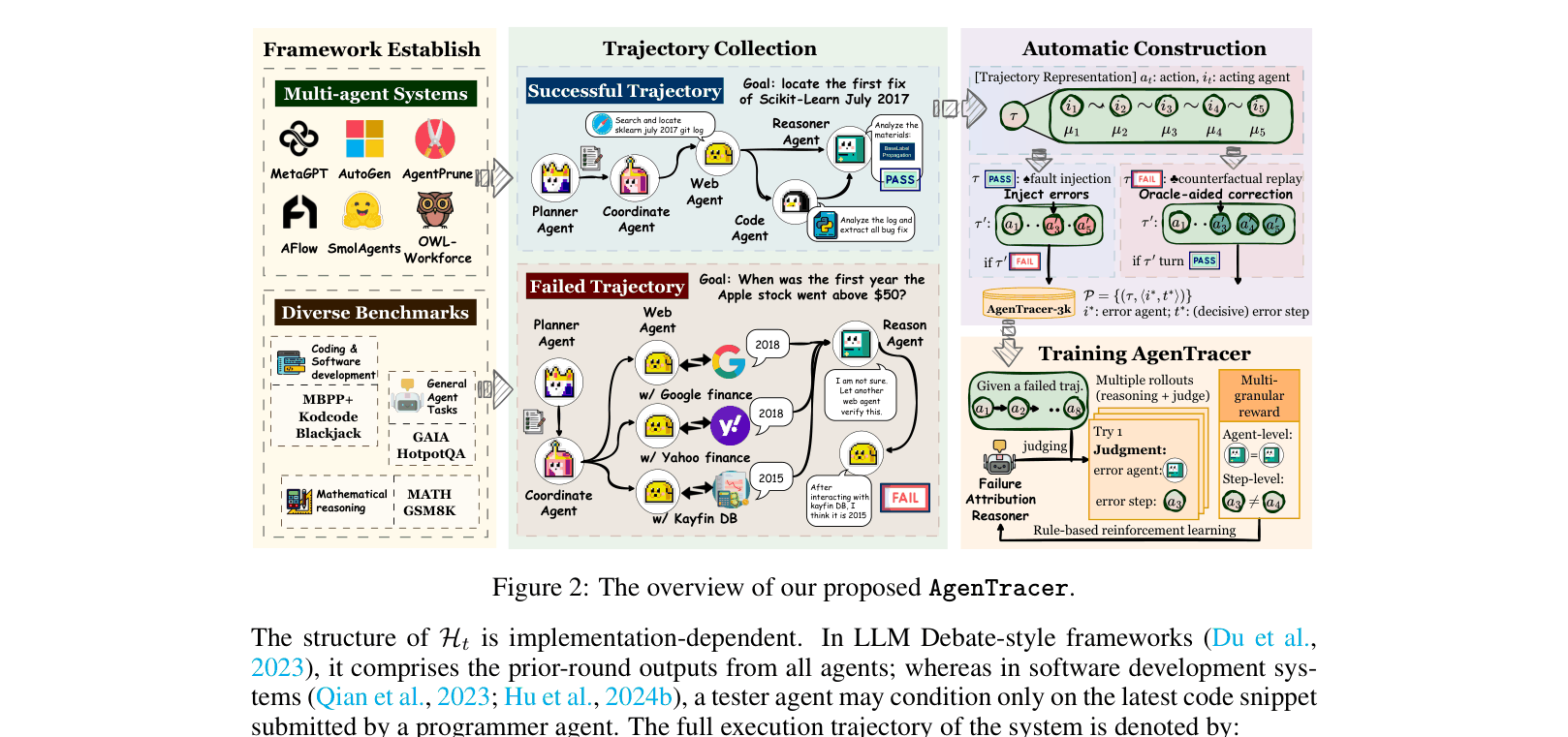
The complete pipeline: from collecting successful/failed trajectories, to annotation via counterfactual replay (for failures) and fault injection (for successes), to training AgenTracer-8B via RL.
Evaluation Highlights
- Outperforms giant proprietary models like Gemini-2.5-Pro (+18.18%) and Claude-4-Sonnet (+12.21%) on the Who&When benchmark
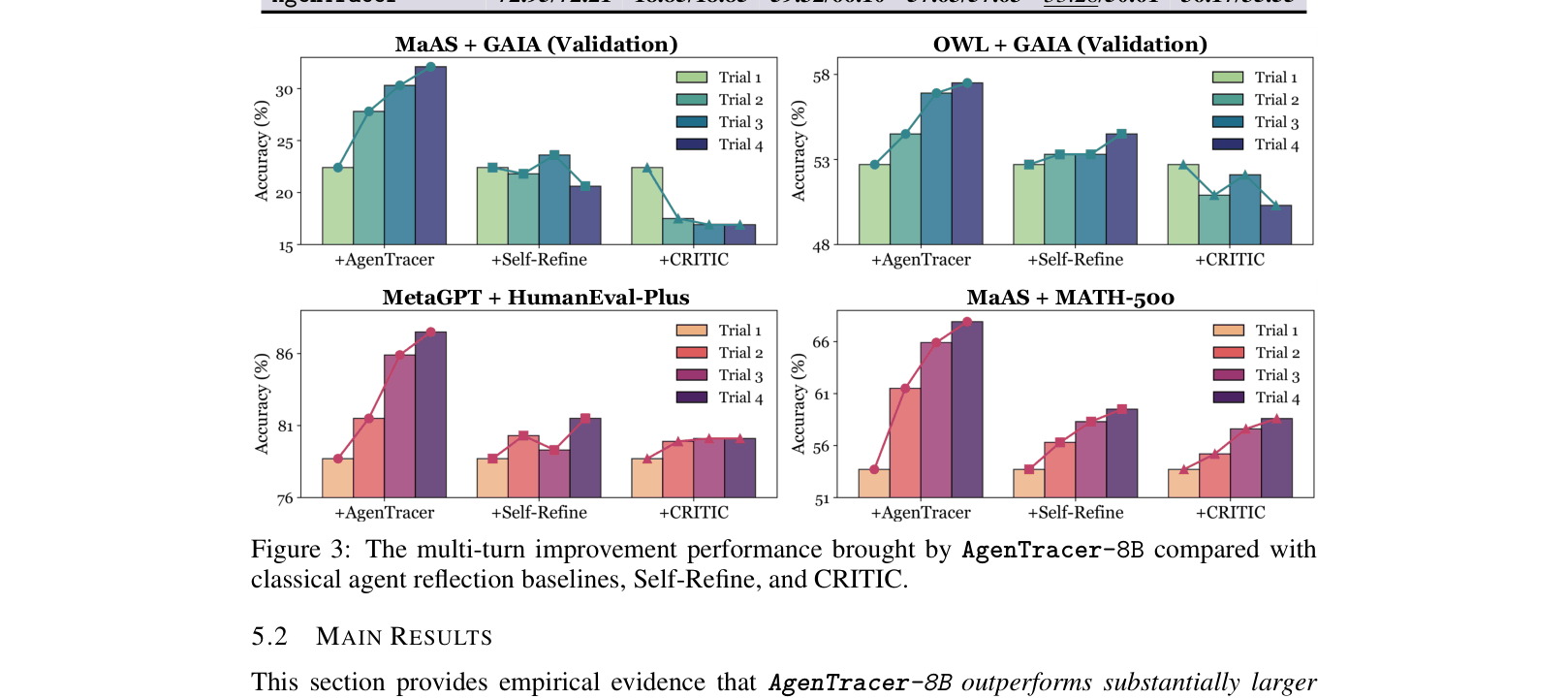
- Boosts the performance of existing multi-agent systems (e.g., MetaGPT, MaAS) by 4.8% to 14.2% when used to provide corrective feedback
- Achieves 69.62% agent-level accuracy on automated benchmarks compared to 58.73% for the base Qwen3-8B model
Breakthrough Assessment
8/10
Significant advancement in automated debugging for agents. The method effectively solves the 'credit assignment' problem in agentic systems, enabling self-correcting loops that actually work where previous critique methods failed.