📝 Paper Summary
Mobile GUI Agents
Online Reinforcement Learning
Vision Language Models
MobileRL improves mobile GUI agents by scaling online reinforcement learning with difficulty-adaptive strategies that prioritize solvable tasks and reward shorter successful trajectories.
Core Problem
Training mobile GUI agents via online RL is inefficient due to sparse rewards, heavy-tailed task difficulty (many tasks are unsolvable or trivial), and the high latency of mobile emulators.
Why it matters:
- Supervised fine-tuning on static data limits behavior coverage and error recovery capabilities
- Naive sampling in expensive mobile simulators wastes computational budget on persistently unsolvable tasks or redundant successes
- Base vision-language models struggle to produce correct action commands for complex GUI instructions without dense feedback
Concrete Example:
In a task like 'add an event for tomorrow at 3pm', a standard RL agent might fail repeatedly without feedback until the horizon is reached, or randomly succeed via a very long, inefficient path, reinforcing verbose behavior.
Key Novelty
Difficulty-Adaptive Group Relative Policy Optimization (AdaGRPO)
- Optimizes policy using a group-relative baseline that adapts to task difficulty by filtering out persistently failing tasks (Failure Curriculum Filtering)
- Reshapes sparse binary success rewards to favor shorter, more efficient trajectories (Shortest-Path Reward Adjustment)
- Maintains a buffer of rare, challenging successful trajectories to replay positive signals alongside on-policy data (Difficulty-Adaptive Positive Replay)
Architecture
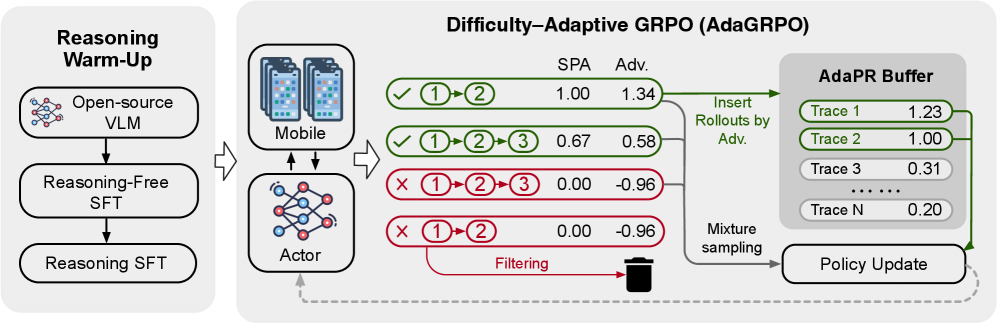
The MobileRL framework pipeline, illustrating the three stages: Reasoning-free SFT, Reasoning SFT, and Agentic RL with AdaGRPO.
Evaluation Highlights
- MobileRL-9B achieves 80.2% success rate on AndroidWorld, surpassing the previous state-of-the-art (64.2%)
- MobileRL-9B achieves 53.6% success rate on AndroidLab, outperforming the previous best (41.2%)
- MobileRL-7B (+16% on AndroidWorld) outperforms significantly larger 72B-parameter models like UI-Tars-1.5 and UI-Genie-Agent
Breakthrough Assessment
9/10
Significant jump in SOTA performance on major benchmarks (AndroidWorld/AndroidLab) with a scalable framework that addresses the core bottleneck of efficiency in agentic RL.