📝 Paper Summary
Sub-agents-as-tools paradigm
Agentic Orchestration
AOrchestra employs a central orchestrator that dynamically creates specialized sub-agents on the fly using a unified 4-tuple abstraction (Instruction, Context, Tools, Model) to solve complex long-horizon tasks.
Core Problem
Existing agentic systems rely on static sub-agent roles or rigid context-isolation threads, which lack the flexibility to handle the dynamic variety of subtasks in open-ended environments.
Why it matters:
- Fixed roles require heavy human engineering and cannot cover emergent subtasks in open environments
- Simple context isolation fails to specialize agent capabilities (tools and models) for specific subtasks
- Lack of control over context routing leads to noisy over-sharing or harmful omission of critical information
Concrete Example:
In a coding task requiring both file navigation and code editing, a static 'Coder' role might be overwhelmed with a huge codebase context. AOrchestra instead spawns a specific 'Navigator' sub-agent with only file-system tools and relevant context, then subsequently spawns an 'Editor' sub-agent with only the necessary file content and editing tools.
Key Novelty
On-demand Sub-Agent Specialization via 4-Tuple Abstraction
- Models any agent as a dynamically instantiable tuple of <Instruction, Context, Tools, Model>, treating agents as compositional recipes rather than fixed roles
- Decouples orchestration from execution: the Orchestrator does not execute tasks but focuses solely on synthesizing this 4-tuple to spawn disposable, specialized executors
Architecture
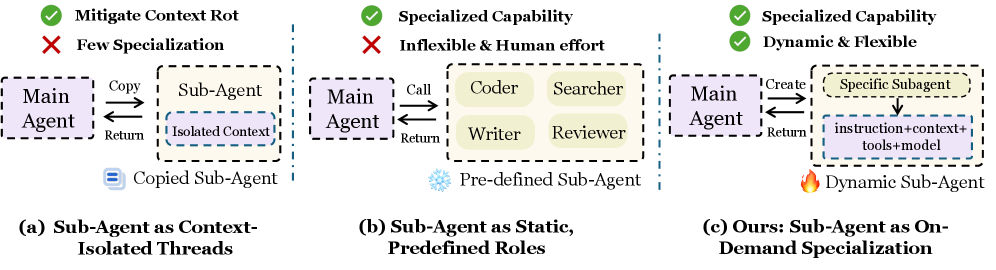
Comparison of AOrchestra's on-demand specialization vs. static roles/context isolation, and the detailed workflow of the Orchestrator delegating to Executors.
Evaluation Highlights
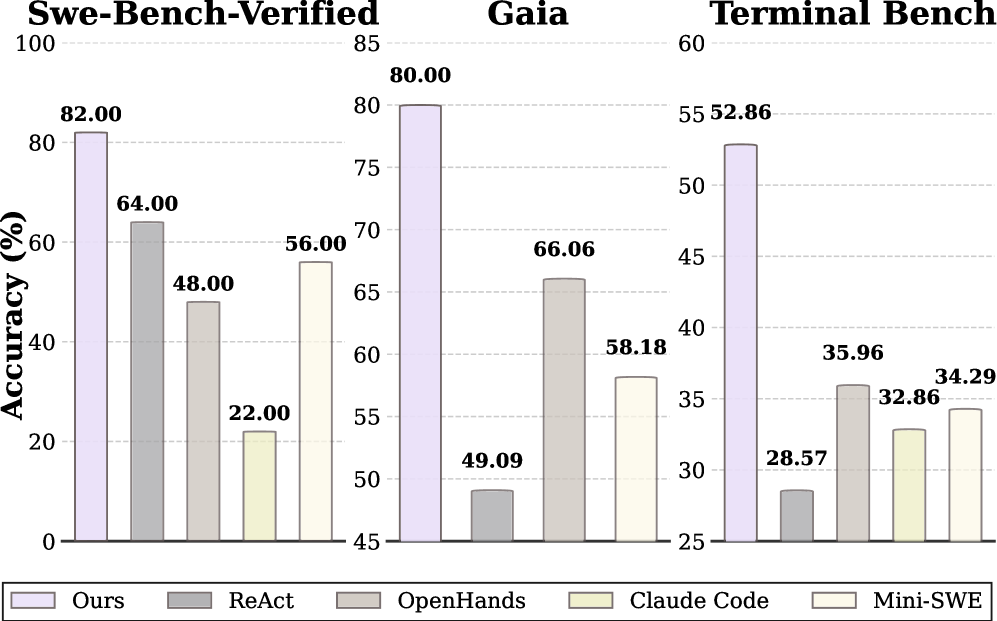
- +16.28% relative improvement against the strongest baseline (OpenHands) on GAIA, SWE-Bench-Verified, and Terminal-Bench 2.0 when paired with Gemini-3-Flash
- Supervised Fine-Tuning (SFT) of the Orchestrator improves pass@1 on GAIA by +11.51% over the base model
- Cost-aware routing optimization reduces average cost by 18.5% on GAIA while improving pass@1 by +3.03% via in-context learning
Breakthrough Assessment
8/10
Strong conceptual shift from static roles to dynamic agent instantiation. Significant performance gains on top-tier benchmarks (GAIA, SWE-Bench) and demonstrates learnable orchestration for cost-efficiency.