📝 Paper Summary
Robotic Manipulation
Agentic AI
ALRM couples an LLM-based planner with a modular executor that supports both code generation and iterative tool use, enabling robots to adaptively solve linguistically diverse multistep tasks.
Core Problem
Existing LLM-robotics integrations typically lack closed-loop feedback mechanisms (making them brittle during execution) and rely on benchmarks with limited linguistic variation and reasoning depth.
Why it matters:
- Rigid, open-loop pipelines (like early Code-as-Policy) cannot reflect on outcomes or correct errors during execution
- Current benchmarks focus on low-level control or simple instruction phrasing, failing to test if agents can handle abstract reasoning or diverse user commands
- Robotic systems need to handle multistep dependencies (e.g., 'move X before Y') which requires dynamic planning rather than static script generation
Concrete Example:
In a standard setup, if a user asks to 'pick the two fruits with the lowest calories,' a standard pipeline might fail to identify the objects or stop if a grasp fails. ALRM's agentic loop allows the system to first query object properties, reason about which to pick, and retry if a specific tool call fails.
Key Novelty
Dual-Mode Agentic Execution (CaP & TaP) within a ReAct Loop
- Integrates a high-level Task Planner (ReAct-based) with a specialized Task Executor that can switch between generating full Python scripts (Code-as-Policy) or iterative function calls (Tool-as-Policy)
- Introduces a linguistically diverse benchmark where every canonical task is paraphrased into distinct categories (Lexical, Syntactical, Semantic, High-level reasoning) to stress-test understanding
Architecture
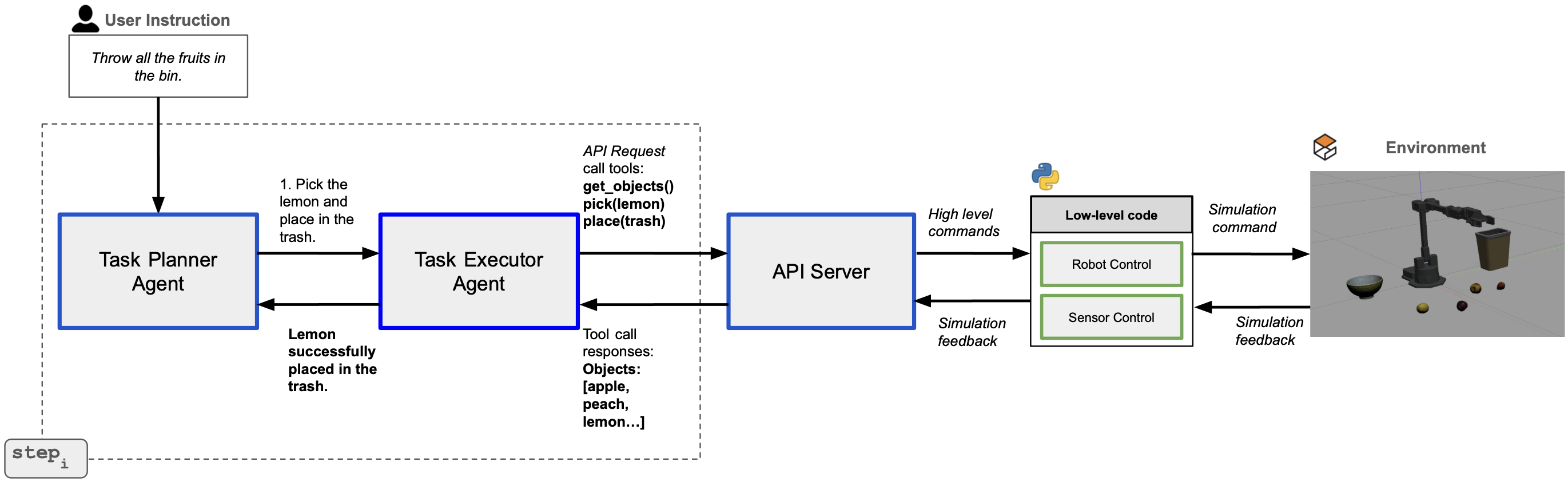
The ALRM architecture, illustrating the flow between the Task Planner Agent, Task Executor Agent, and the API Server/Robot.
Evaluation Highlights
- Claude-4.1-Opus achieves the highest success rates among closed-source models: 93.5% in Tool-as-Policy mode and 92.6% in Code-as-Policy mode
- Falcon-H1-7B achieves 84.3% success in Code-as-Policy mode, matching DeepSeek-V3.1 while requiring less than half the execution latency
- The framework validates that Code-as-Policy is generally faster (single generation) while Tool-as-Policy offers finer-grained error correction via the agentic loop
Breakthrough Assessment
7/10
Solid integration of agentic reasoning into robotics with a useful dual-mode execution strategy. The new linguistically diverse benchmark addresses a significant gap in evaluating robotic reasoning robustness.
