📝 Paper Summary
Synthetic Data Generation
Agentic AI
Tool Use
TaskCraft is an automated workflow that generates scalable, multi-tool agentic tasks with execution trajectories by reversing tool logic (answer-to-question) and iteratively extending simple tasks into complex hierarchies.
Core Problem
Existing agentic benchmarks (like GAIA and HLE) rely on expensive, non-scalable human annotation, while current synthetic methods (like Self-Instruct) lack the dynamic tool interactions required for agentic tasks.
Why it matters:
- Training advanced agents requires massive amounts of trajectory data that demonstrates tool use and adaptive reasoning
- Static instruction-following data fails to model the dynamic environment interactions central to agentic workflows
- Manual annotation of complex tasks (e.g., HLE required 1,000 experts for 2,500 points) is too costly to scale
Concrete Example:
A standard LLM might generate a static question like 'What is the capital of France?', but fails to create a verifiable task requiring a PDF reader tool to extract a specific financial figure from a report and compare it to a live stock price.
Key Novelty
Reverse-Engineering Agentic Tasks (TaskCraft)
- Constructs 'atomic' tasks by starting with a tool's output (the answer) and prompting an LLM to reverse-engineer the question and required input (the premise)
- Expands difficulty recursively via 'depth-based' extension (finding prerequisites for the current input) and 'width-based' extension (merging independent sub-problems)
- Verifies extended tasks using linguistic analysis rather than full agent execution, significantly reducing computational cost
Architecture
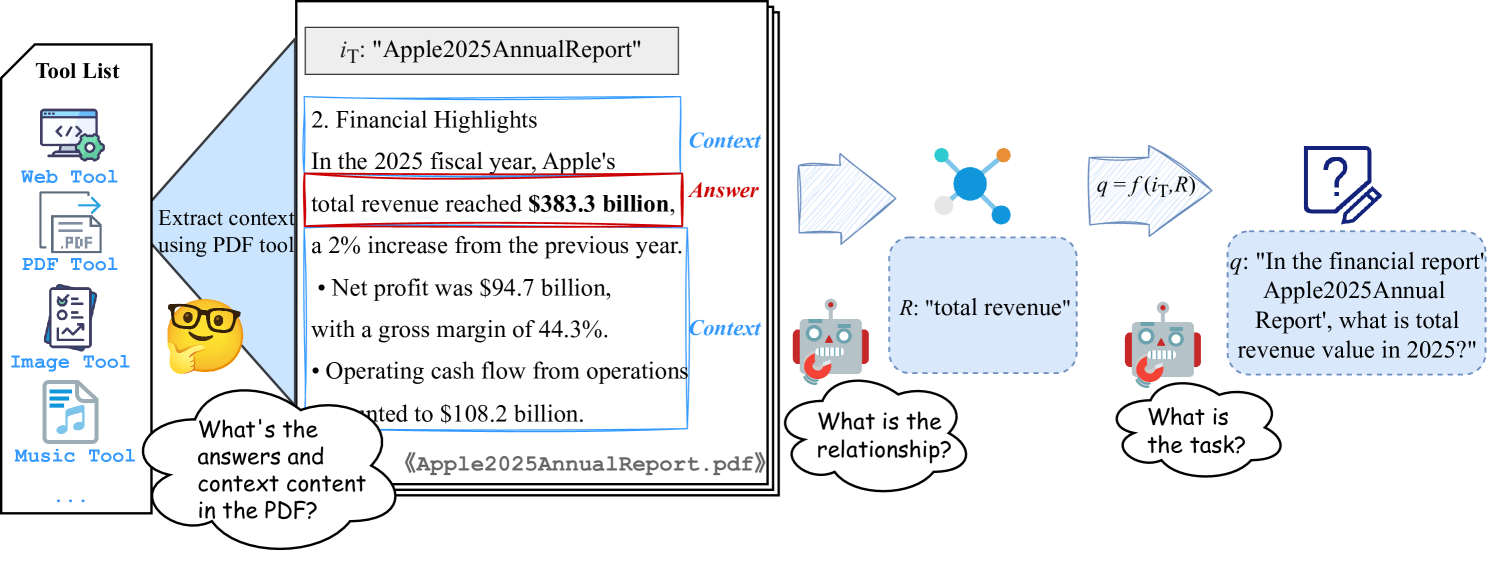
The complete TaskCraft workflow, illustrating the progression from unlabeled data to atomic tasks, and then to extended depth/width tasks with verification loops.
Evaluation Highlights
- +14.0% average performance improvement for Qwen2.5-3B-Base on multi-hop QA benchmarks after SFT with TaskCraft data
- Achieves +19.2% gain on Bamboogle and +6.2% on Musique compared to the Search-R1 baseline using Qwen2.5-3B-Base
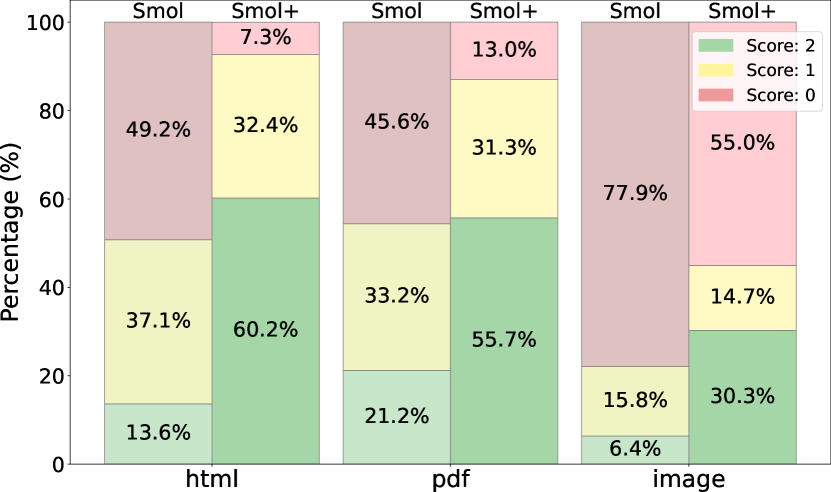
- Prompt optimization reduced atomic task generation time by 19.2% and improved pass rates from 54.9% to 68.1%
Breakthrough Assessment
8/10
Addresses the critical bottleneck of data scarcity for agentic AI. The reverse-generation and efficient verification pipeline enables scalable, high-quality synthetic data creation that demonstrably improves model performance.