📝 Paper Summary
Synthetic Data Generation for Agents
Environment Simulation
Agent Fine-tuning
AgentScaler automates the creation of diverse, verifiable agent training environments by modeling APIs as database operations, enabling a two-stage fine-tuning process that scales agent capabilities.
Core Problem
Training capable agents requires massive amounts of high-quality interaction data (trajectories), but current methods rely on unscalable manual environment construction or produce unrealistic, unverifiable synthetic data.
Why it matters:
- Real-world agent deployment is bottlenecked by the scarcity of diverse 'agentic data' (actual trajectories of tool use, not just text)
- Existing synthetic data methods often hallucinate tool outputs or lack a responsive environment, preventing agents from learning true cause-and-effect relationships
- Manual environment creation is too slow to cover the millions of real-world APIs agents need to master
Concrete Example:
In a 'reverse paradigm' approach, a model generates a user query to match a tool call, often resulting in unnatural phrasing. In a 'forward paradigm' without a real environment, an agent might 'send an email' but the system never validates if the email was actually sent, leading to hallucinated success.
Key Novelty
Environment-as-Database Abstraction & Automated Scaling
- Models every API tool as a read or write operation on a simulated database schema, allowing tool executions to be programmatically verified against state changes
- Uses community detection on API dependency graphs to automatically partition thousands of tools into coherent 'domains' (simulated environments), removing the need for manual task design
- employs a two-phase 'Agent Experience Learning' strategy: first learning general tool-use mechanics across diverse domains, then specializing in vertical domains
Architecture
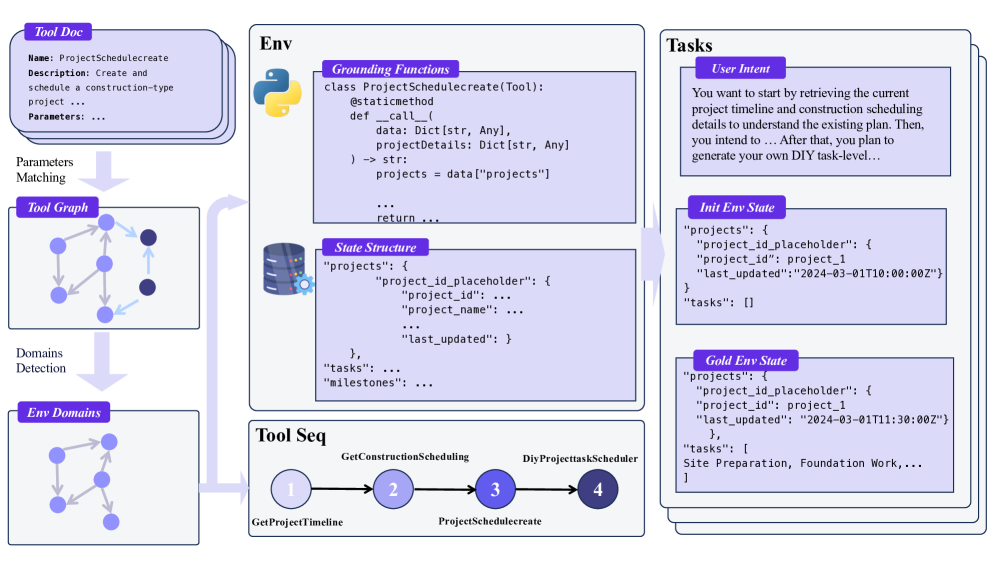
The complete AgentScaler pipeline: from raw API collection to environment construction and agent training.
Evaluation Highlights
- AgentScaler-30B-A3B sets a new state-of-the-art on ACEBench and tau-bench, matching performance of 1T-parameter open-source models
- AgentScaler-4B achieves performance parity with 30B-parameter baselines, demonstrating the efficiency of the proposed environment scaling
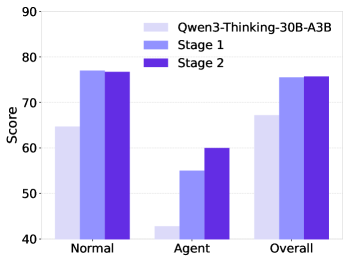
- Two-stage training (General -> Vertical) substantially improves performance over single-stage baselines across all subsets of ACEBench
Breakthrough Assessment
8/10
Addresses the critical bottleneck of agent training data (environment scarcity) with a scalable, verifiable automated pipeline. High performance with smaller models suggests a significant efficiency gain.