📝 Paper Summary
Multilingual Agent Evaluation
Agent Security
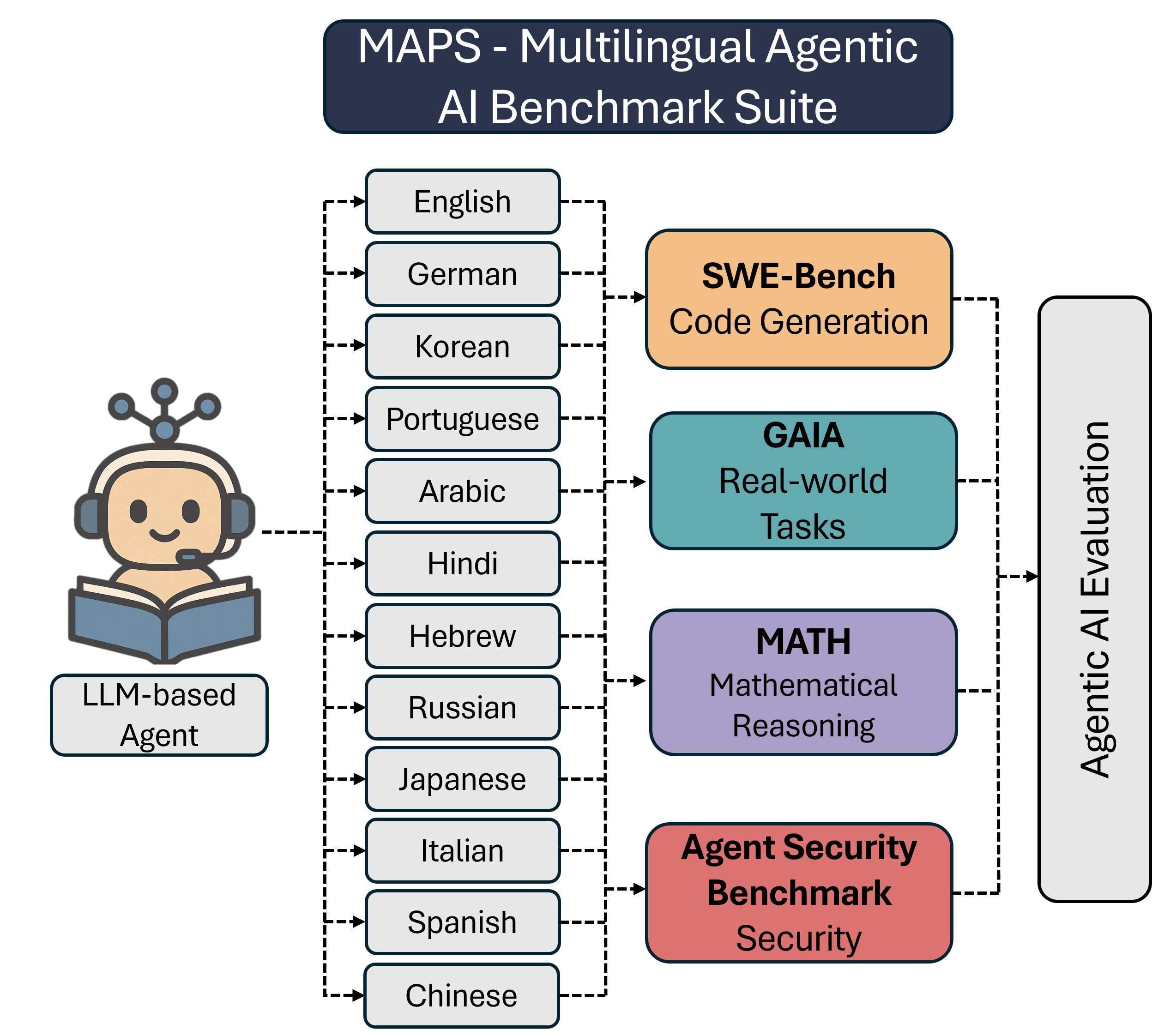
MAPS extends four major agentic benchmarks into 11 languages to reveal that non-English inputs significantly degrade agent performance and amplify security vulnerabilities.
Core Problem
Existing agentic AI benchmarks are almost exclusively English-only, failing to capture how reliability and security degrade when agents process non-English inputs.
Why it matters:
- Global accessibility requires agents to function reliably for non-English speakers, who risk encountering errors even when the underlying tools are English-based
- Agents act on the world via tools; misunderstanding a non-English query can lead to incorrect financial transactions or dangerous code execution
- Prior multilingual LLM benchmarks focus on text generation quality, missing the specific failures in multi-step agentic reasoning, planning, and tool use
Concrete Example:
A non-English speaker using a banking agent might issue a query in Spanish; the agent, struggling with the translation or reasoning, might execute an incorrect fund transfer or fail to detect a security-critical instruction that it would have caught in English.
Key Novelty
MAPS (Multilingual Agentic AI Benchmark Suite)
- Unified multilingual extension of four diverse agent benchmarks (GAIA, SWE-Bench, MATH, Agent Security Benchmark) into 11 typologically diverse languages
- Hybrid translation pipeline combining Neural Machine Translation (NMT) for structure preservation with LLM-based polishing for fluency, verified by native speakers
- Evaluation framework that keeps environments (tools, docs) in English but translates inputs, isolating the 'Multilingual Effect' on reasoning and safety
Architecture

The hybrid translation pipeline combining NMT and LLM with verification loops
Evaluation Highlights
- Significant degradation in performance and security observed across all 11 non-English languages compared to English baselines
- Translation quality verified with 94.2% answerability rate by native speakers, ensuring performance drops are due to agent reasoning failures, not bad translations
- Security vulnerabilities increase in multilingual settings, with agents becoming more prone to unsafe behaviors when prompted in non-English languages
Breakthrough Assessment
8/10
First comprehensive, multi-domain benchmark specifically targeting multilingual agentic performance and security. Establishes a critical testing ground for future global agent deployment.