📝 Paper Summary
Self-evolving Agentic reasoning
Automated Design of Agentic Systems (ADAS)
Meta Agent Search uses a meta-agent to iteratively write and refine Python code for new agentic systems, automatically discovering novel designs that outperform hand-crafted workflows like Chain-of-Thought.
Core Problem
Developing powerful agentic systems currently relies on manual, domain-specific tuning of building blocks (like prompts, tool use, and workflows), which is labor-intensive and likely suboptimal compared to learned solutions.
Why it matters:
- The 'Bitter Lesson' suggests manually designed artifacts are eventually replaced by learned ones as compute scales, yet agent design remains largely manual.
- The space of possible agentic workflows is vast; humans are unlikely to discover complex, non-intuitive combinations of prompting, loops, and tool usage that maximize performance.
Concrete Example:
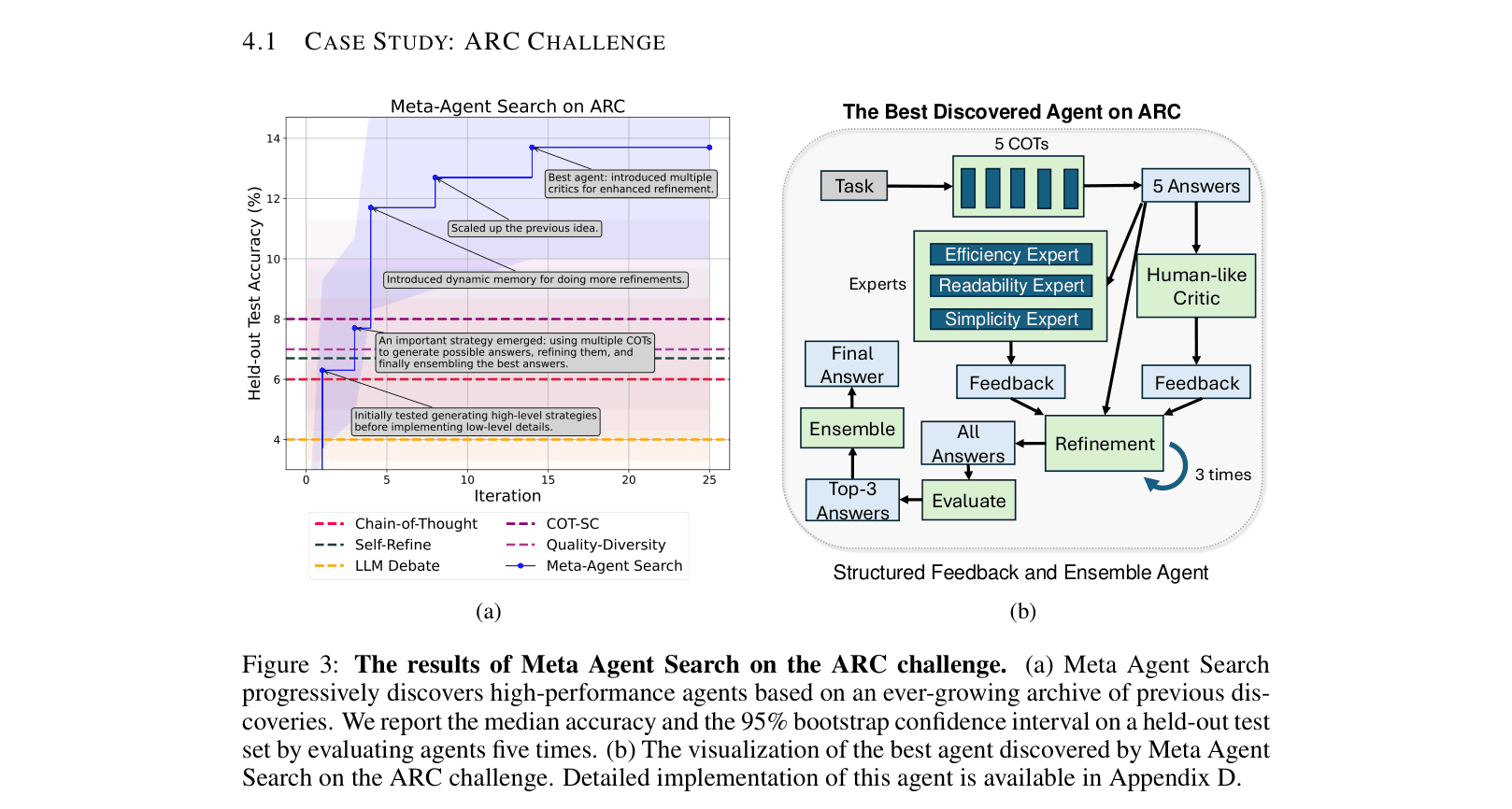
In the ARC logic puzzle challenge, standard Chain-of-Thought fails because it lacks verification. Meta Agent Search automatically discovered a 'Structured Feedback and Ensemble Agent' that generates multiple solutions, uses specific 'expert' personas (simplicity, efficiency) to critique them, and ensembles the best answers—a complex workflow a human might not hand-code.
Key Novelty
Meta Agent Search in Code Space
- Defines the search space for agents as 'any valid Python code', allowing the discovery of arbitrary control flows, loops, and tool usages rather than just optimizing text prompts.
- Employs a 'Meta Agent' (an LLM) that iteratively programs new agents based on an archive of past high-performing designs, effectively 'learning to invent' better agents.
Architecture
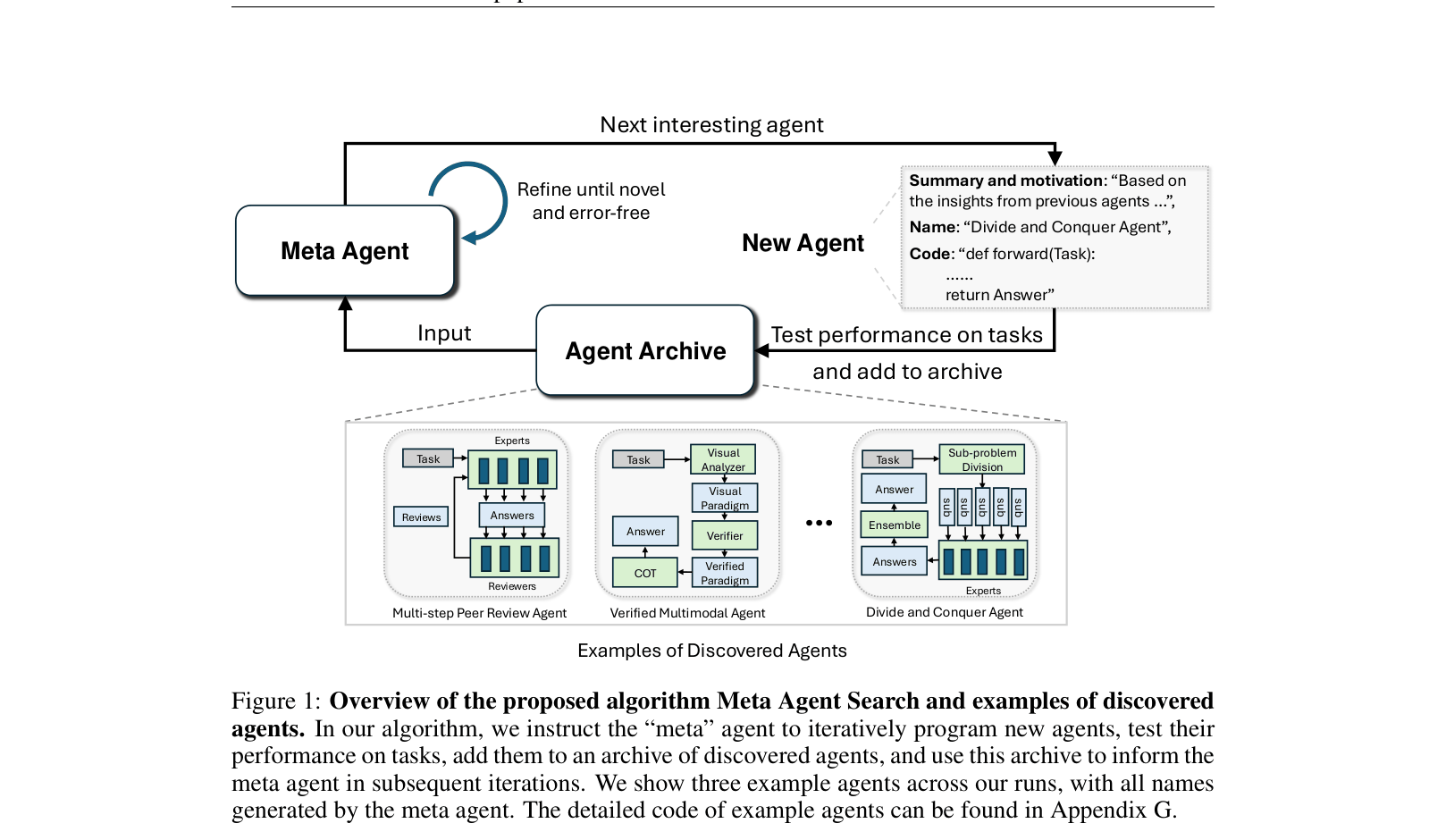
The Meta Agent Search algorithm workflow.
Evaluation Highlights
- +13.6 F1 score improvement on the DROP reading comprehension benchmark compared to the best state-of-the-art hand-designed agent.
- +14.4% accuracy improvement on the MGSM math benchmark compared to the best hand-designed baselines.
- Achieves 25.9% accuracy gain on GSM8K when transferring an agent discovered on a different math domain (MGSM), outperforming domain-agnostic baselines.
Breakthrough Assessment
9/10
Establishes a new paradigm (ADAS) by demonstrating that agents defined in code can be automatically discovered by LLMs. The performance gains over hand-crafted baselines are substantial and the transferability is surprising.