📝 Paper Summary
Agentic Workflow Evaluation
Automated Debugging
TRAIL introduces a fine-grained error taxonomy and a dataset of 148 structured agent traces, revealing that current SOTA LLMs fail to accurately debug and localize errors in complex agentic workflows.
Core Problem
Evaluating agentic systems is currently limited to binary end-to-end metrics or manual review, which cannot scale to handle the complex, non-deterministic, and lengthy structured traces (logs) generated by modern agents.
Why it matters:
- Current evaluation methods ignore the root cause of failure, making debugging difficult for engineers optimizing agentic systems
- Existing trace analysis benchmarks rely on unstructured text, failing to represent standard industry formats like OpenTelemetry
- LLMs struggle to process long, structured execution logs, yet are increasingly relied upon as evaluators
Concrete Example:
An agent might fail a coding task because of a specific 'Rate Limiting' (HTTP 429) error in a tool call at Step 5. Current methods just mark the whole task as 'Failed', whereas TRAIL requires the evaluator to identify the specific step and classify the error as an execution failure.
Key Novelty
Ecologically Valid Trace Benchmarking
- Proposes a comprehensive taxonomy of agentic errors covering Reasoning (hallucinations), Planning (loops), and Execution (API failures), specifically designed for structured logs
- Replaces simple pass/fail evaluation with 'step-level' issue localization, requiring models to pinpoint exactly where and why an agent failed within a long OpenTelemetry trace
Architecture
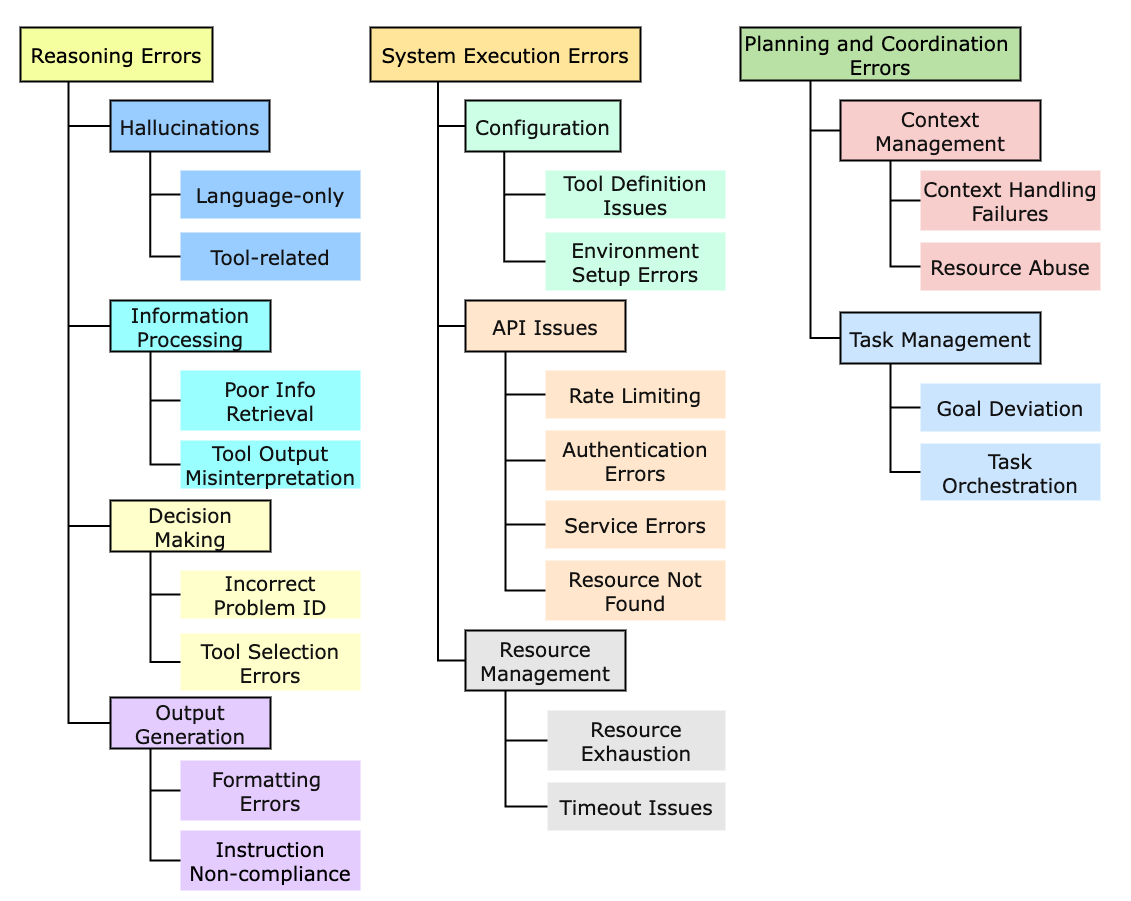
The hierarchical Error Taxonomy used to annotate the traces.
Evaluation Highlights
- Best performing model (gemini-2.5-pro) achieves only 11% joint accuracy (correctly identifying both error location and type) on the TRAIL dataset
- Current SOTA models (including o3 and claude-3.7-sonnet) perform modestly at best, struggling with the long-context structured data required for trace analysis
Breakthrough Assessment
8/10
Establishes a necessary standard for granular agent evaluation. The extremely low performance of SOTA models (11%) indicates it effectively exposes a major gap in current capabilities.