📝 Paper Summary
Agentic reinforcement learning
Math reasoning
Code generation for reasoning
rStar2-Agent trains a 14B model to achieve frontier-level math reasoning by using a novel reinforcement learning strategy that filters noisy code execution feedback and prioritizes high-quality, correct reasoning trajectories.
Core Problem
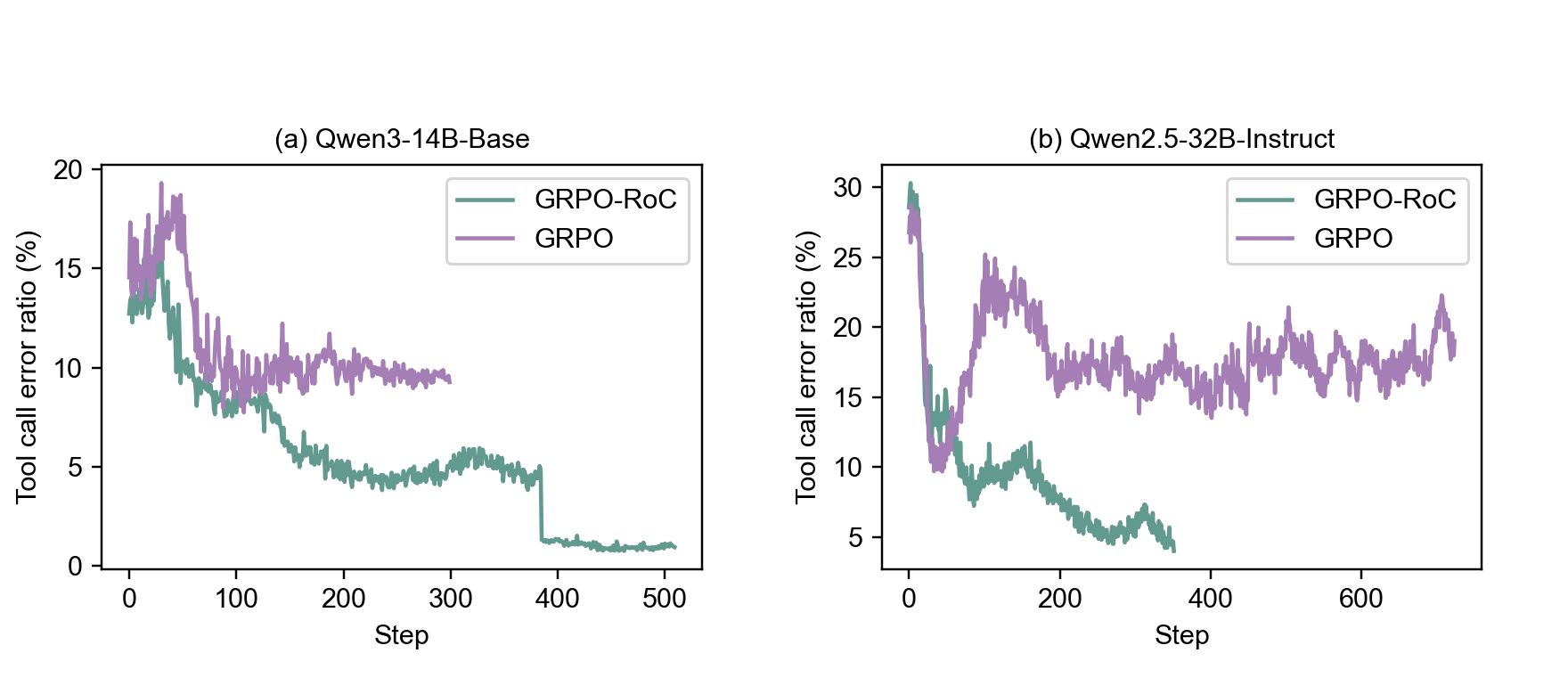
Standard RL for reasoning fails in coding environments because outcome-only rewards validate trajectories even when intermediate code steps are broken or noisy, teaching models that errors are acceptable.
Why it matters:
- Current reasoning models rely on 'thinking longer' (Long CoT) but struggle with tasks requiring external verification or creative shifts
- Outcome-only rewards in noisy environments lead to reward hacking, where models produce lengthy, low-quality trajectories with many tool errors
- Scaling agentic RL is computationally expensive due to the high cost of rollouts and concurrent tool execution environments
Concrete Example:
A model might write incorrect Python code to solve a math problem, receive an error message, try again, and eventually guess the right answer. Standard RL rewards this entire messy trajectory as 'correct' (reward=1), reinforcing the behavior of writing buggy code and wasting tokens on error correction.
Key Novelty
Group Relative Policy Optimization with Resample-on-Correct (GRPO-RoC)
- Oversamples rollout trajectories and applies asymmetric filtering: keeps all failure modes to learn what to avoid, but aggressively filters successful trajectories to keep only those with clean code and minimal errors
- Introduces a specialized infrastructure that balances rollout requests based on GPU KV cache capacity, enabling massive-scale training (45K concurrent tool calls) on limited hardware
Architecture
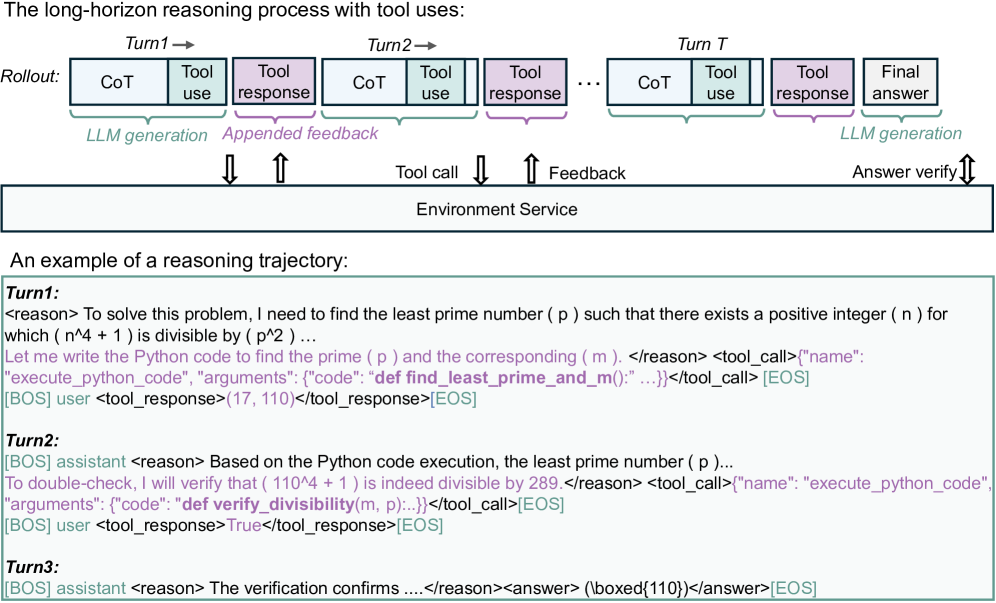
The multi-turn agentic rollout process where the model interacts with a Python environment
Evaluation Highlights
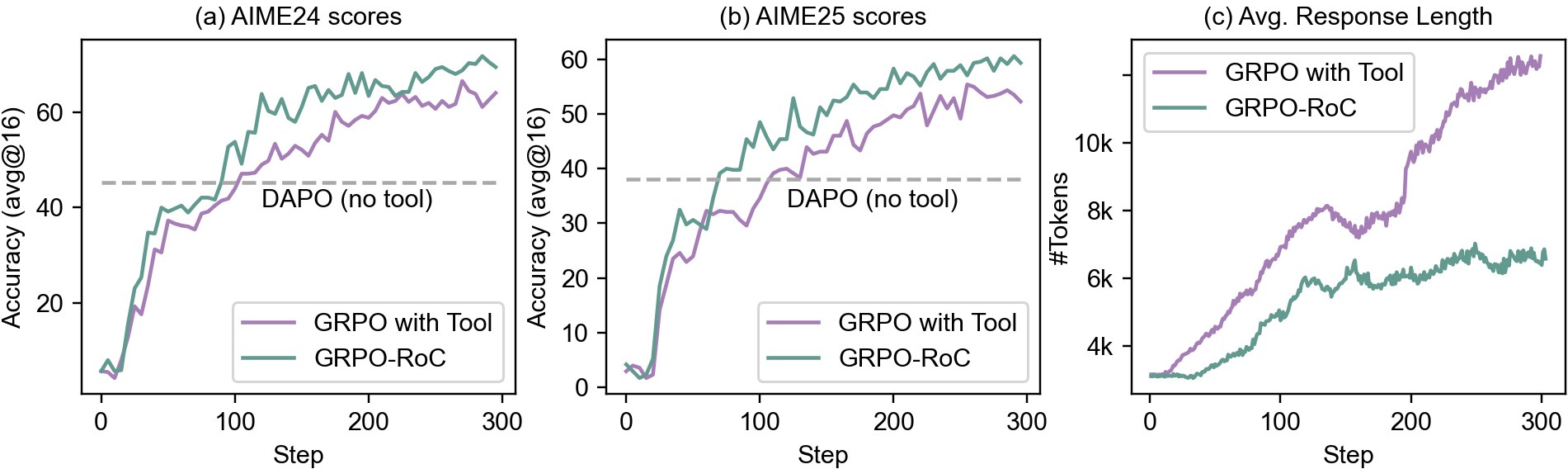
- Achieves 80.6% pass@1 on AIME 2024, outperforming OpenAI o3-mini (medium) and DeepSeek-R1 (671B)
- Surpasses DeepSeek-R1 on AIME 2025 with 69.8% accuracy while using a significantly smaller 14B model
- Reached state-of-the-art performance in only 510 RL steps over one week using 64 MI300X GPUs
Breakthrough Assessment
9/10
Demonstrates that small (14B) models can beat massive frontier models (671B) on hard math benchmarks through specialized agentic RL, effectively solving the noisy-reward problem in tool-use training.