📝 Paper Summary
Self-evolving Agentic reasoning
Automated Machine Learning (AutoML)
ML-Agent trains a language model to autonomously perform machine learning engineering by using step-wise reinforcement learning on expert trajectories to overcome the high latency of experimental feedback.
Core Problem
Current autonomous ML agents rely on static, manually engineered prompts and fail to improve from experience, while applying standard RL is impractical because ML experiments take too long to run.
Why it matters:
- Manual prompt engineering prevents agents from generalizing across diverse tasks or learning from their own successes and failures.
- Standard online RL requires generating full task trajectories, but running a single ML training loop to get feedback can take hours, making data collection prohibitively slow.
- Existing agents often repeat similar, narrow strategies (limited exploration) rather than discovering novel optimization paths.
Concrete Example:
In a standard setup, an agent might repeatedly try small, ineffective code edits (like changing a learning rate slightly) across many episodes because it cannot explore broadly. Furthermore, to learn that a complex architecture change is good, RL would need to wait hours for the model to train, slowing down policy updates to a crawl.
Key Novelty
Step-wise RL with Exploration-Enriched Fine-tuning
- Decouples RL from full trajectory rollouts by optimizing the agent on single steps starting from pre-collected expert states, drastically speeding up training.
- Uses a 'fast' set of small ML tasks to generate diverse expert strategies (e.g., regularization ideas) via GPT-4o-mini, then fine-tunes the agent on these to ensure broad exploration capabilities before RL begins.
- Unifies diverse ML feedback (compilation errors, runtime crashes, accuracy gains) into a single scalar reward function to guide optimization.
Architecture
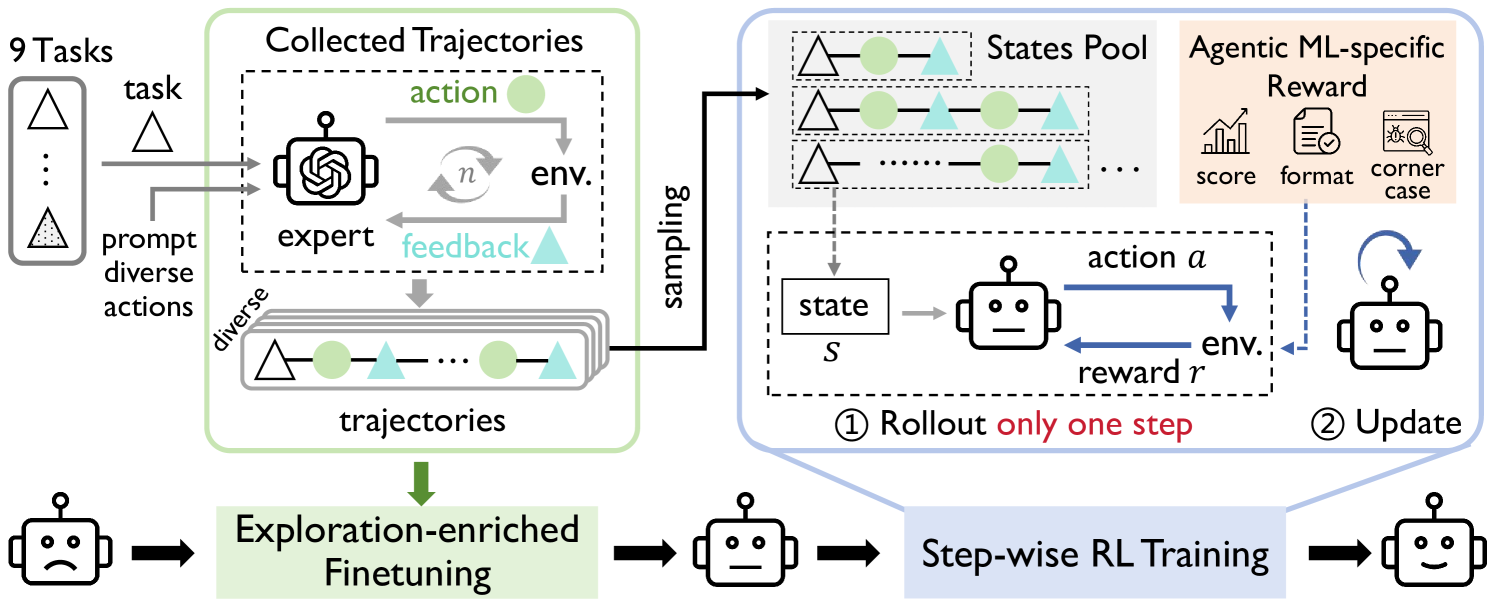
The overall ML-Agent training framework comprising three stages: Exploration-enriched fine-tuning, Step-wise RL, and the Agentic ML-specific reward module.
Evaluation Highlights
- The 7B-parameter ML-Agent outperforms the 671B-parameter DeepSeek-R1 agent on autonomous ML tasks despite being 100x smaller.
- Achieves superior performance on 10 held-out ML tasks not seen during training, demonstrating strong cross-task generalization.
- Continuously improves performance during the RL training phase, verifying the effectiveness of the step-wise learning paradigm.
Breakthrough Assessment
8/10
Proposes a practical solution to the 'long feedback loop' problem in agentic RL for coding/ML tasks. Successfully enabling online RL in this domain is a significant methodological step.