📝 Paper Summary
Agentic Search
Autonomous Web Agents
Mind2Web 2 is a benchmark for long-horizon agentic search that uses a novel tree-structured Agent-as-a-Judge framework to automatically evaluate complex, time-varying answers.
Core Problem
Existing benchmarks for web agents either focus on short-horizon tasks (single website) or rely on static, predefined answers, making them unsuitable for evaluating 'Deep Research' agents that produce complex, time-varying reports spanning many websites.
Why it matters:
- Current evaluation methods cannot handle tasks where the correct answer changes over time (e.g., product prices, availability), hindering progress in realistic agent deployment
- Reliable automated evaluation is critical for trust; users need to know if an agent's long report is grounded in sources or hallucinated, without manually re-doing the search
- Short-horizon benchmarks fail to test an agent's ability to maintain focus and context over hours of browsing and hundreds of actions
Concrete Example:
A task asks for five IKEA furniture items under $600 total. The answer changes daily based on stock/price. A traditional benchmark with a static answer key would fail valid new items. A human evaluator is too slow. Mind2Web 2 automates this by verifying live data against the agent's specific constraints.
Key Novelty
Agent-as-a-Judge with Tree-Structured Rubrics
- Decomposes complex evaluation into a hierarchical tree of criteria (rubric), where leaf nodes are binary checks (e.g., 'Is price < $200?') and internal nodes aggregate scores
- Leverages generation-verification asymmetry: while finding the answer is hard, verifying specific criteria (correctness and attribution) is easier for a specialized judge agent
- Uses a 'gate-then-average' logic where critical nodes (essential constraints) can zero-out branches, while non-critical nodes allow for partial credit
Architecture
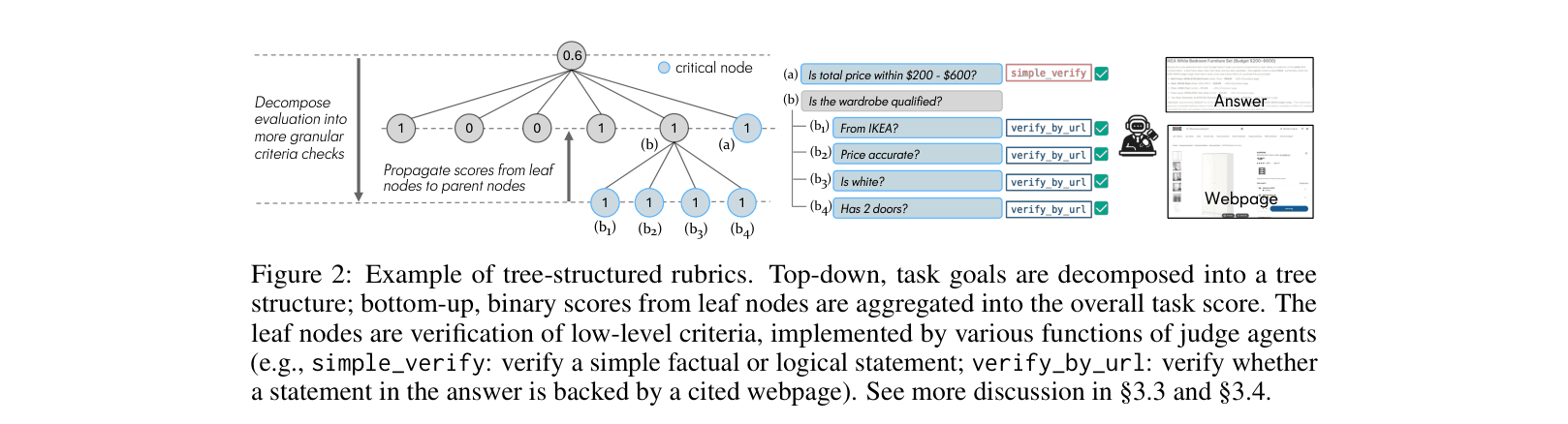
The structure of the Rubric Tree used for evaluation
Evaluation Highlights
- OpenAI Deep Research achieves 0.54 partial completion score, reaching ~70% of human performance (0.79) while taking less than half the time (8.40 min vs 18.40 min)
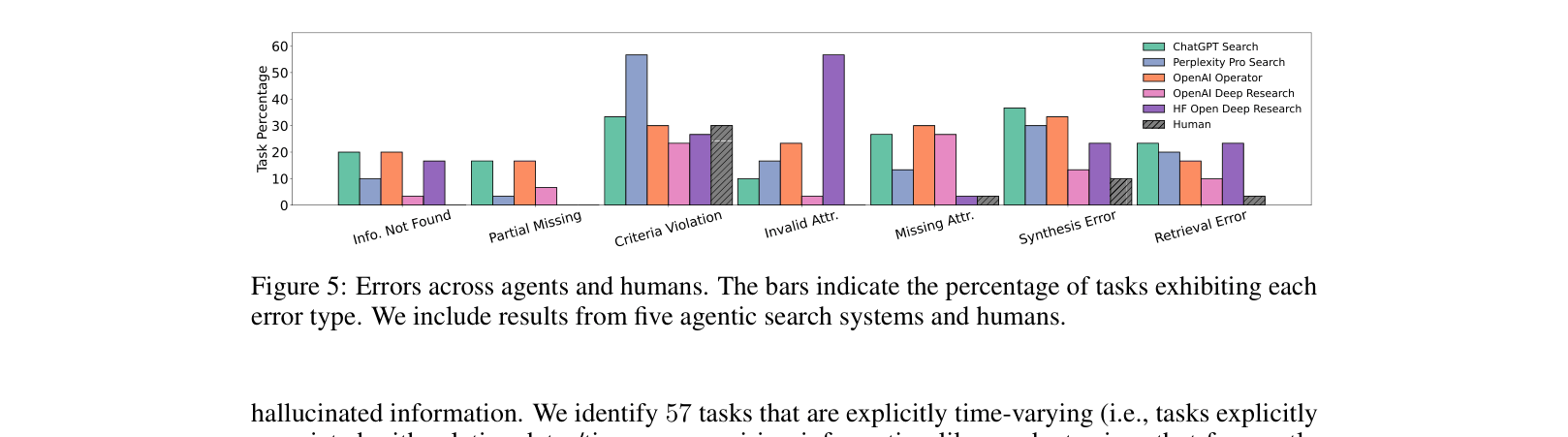
- Current agents struggle with explicitly time-varying tasks; most systems perform worse on this subset, while humans and OpenAI Operator (which browse live) sustain performance
- Automated Judge Agent achieves 99.03% verification correctness compared to human evaluation, enabling reliable scalable benchmarking without human-in-the-loop
Breakthrough Assessment
9/10
Addresses the critical bottleneck of evaluating open-ended, time-varying agent tasks. The tree-structured judge is a significant methodological advance over standard LLM-as-a-Judge.