📝 Paper Summary
Multi-turn w. user interactions
RL-based
BAO trains proactive agents to balance task success and user effort by enforcing specific reasoning behaviors during supervised warm-starts and regularizing them during multi-objective reinforcement learning.
Core Problem
Proactive agents face a trade-off between task performance and user engagement: frequently querying the user improves accuracy but annoys the user, while minimizing interactions hurts performance due to lack of information.
Why it matters:
- Excessive questions from AI agents erode user confidence and satisfaction in real-world applications
- Passive agents fail to adapt to ambiguous user intentions, leading to poor task completion
- Standard RL rewards often exploit user feedback loops, leading to redundant interactions rather than efficient information gathering
Concrete Example:
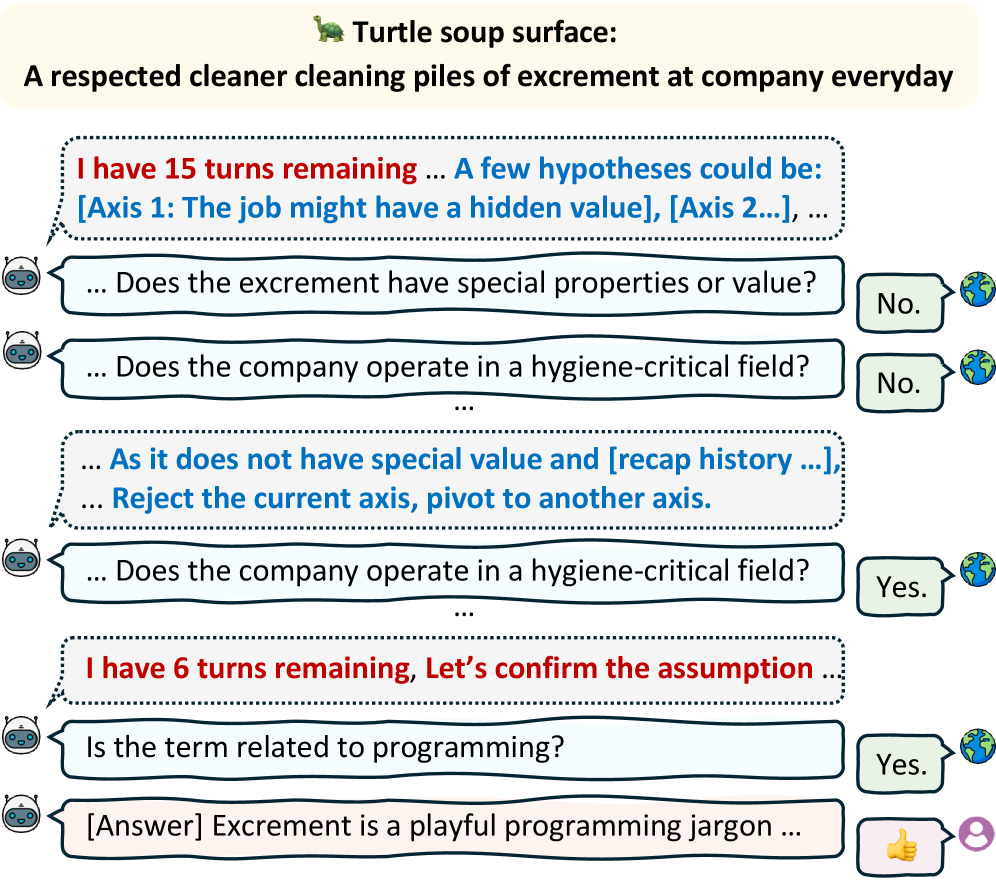
In a task like Turtle-Gym (finding a hidden twist), a standard agent might repeatedly ask the user 'What should I do?' to get feedback. BAO instead initializes a set of assumptions, verifies them efficiently with tools, and only queries the user when necessary to resolve specific uncertainties.
Key Novelty
Behavioral Agentic Optimization (BAO)
- Formulates proactive agent training as a Multi-Objective Optimization (MOO) problem to find the Pareto frontier between task reward and user interaction cost
- Explicitly injects 'retrospective reasoning' (memory/hypothesis refinement) and 'prospective planning' (budget scheduling) behaviors during SFT using a teacher model
- Applies turn-level reward shaping in RL to penalize 'thinking loops' (inefficient reasoning) and redundant user queries that yield no new information
Architecture
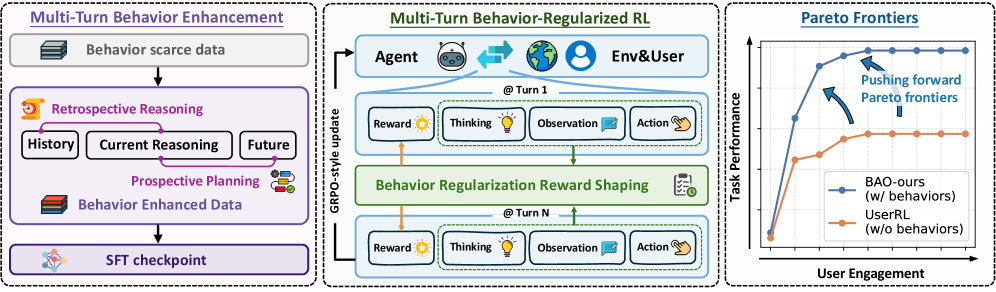
Overview of the BAO framework. It illustrates the trade-off between user engagement and task performance, and defines the two key behavior types: Retrospective Reasoning (Memory Management, Hypothesis Refinement) and Prospective Planning (Dynamic Scheduling, Strategical Querying).
Evaluation Highlights
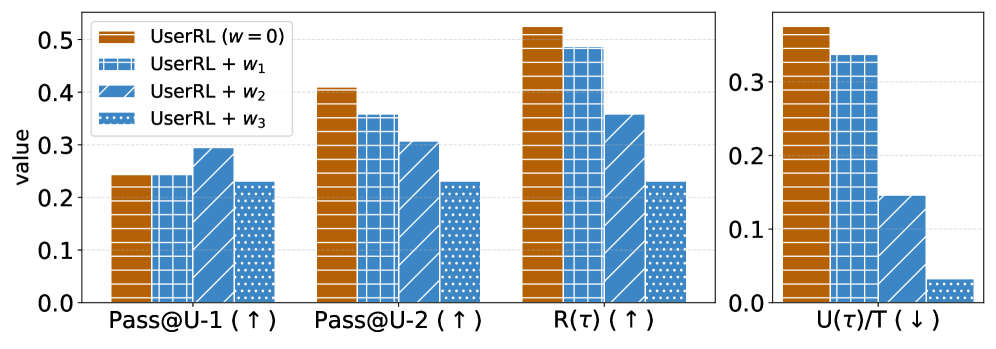
- Substantially outperforms proactive agentic RL baselines on UserRL benchmark tasks while minimizing user effort
- Achieves comparable or superior performance to commercial LLM agents (like GPT-4o) in complex multi-turn scenarios
- Successfully pushes the Pareto frontier, achieving higher task rewards for the same level of user interaction compared to baselines
Breakthrough Assessment
8/10
Strong methodological contribution by formalizing the user-effort vs. performance trade-off as MOO and addressing it with specific behavioral regularizations. Results show clear Pareto improvements over strong baselines.