📝 Paper Summary
Multi-agent
Benchmark datasets
Agentic AI
CREW-Wildfire is a scalable, procedurally generated benchmark for evaluating LLM-based multi-agent systems on complex, physically grounded wildfire response tasks requiring coordination under uncertainty.
Core Problem
Existing multi-agent benchmarks are either too small-scale, symbolic/turn-based (like Hanabi), or lack the architectural support for large-scale LLM-based agent coordination in embodied, dynamic environments.
Why it matters:
- Real-world tasks like disaster response require coordinating hundreds of heterogeneous agents (drones, bulldozers, firefighters) under partial observability
- Current MARL benchmarks rely on rigid communication or centralized training that doesn't scale to flexible, language-based Agentic AI
- It is unclear if current LLM agents can handle the dual challenge of strategic long-horizon planning and precise low-level execution
Concrete Example:
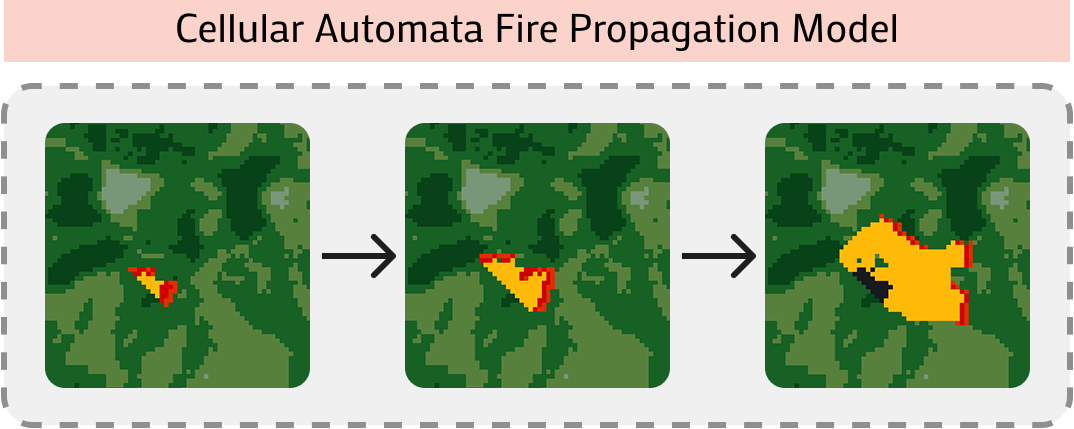
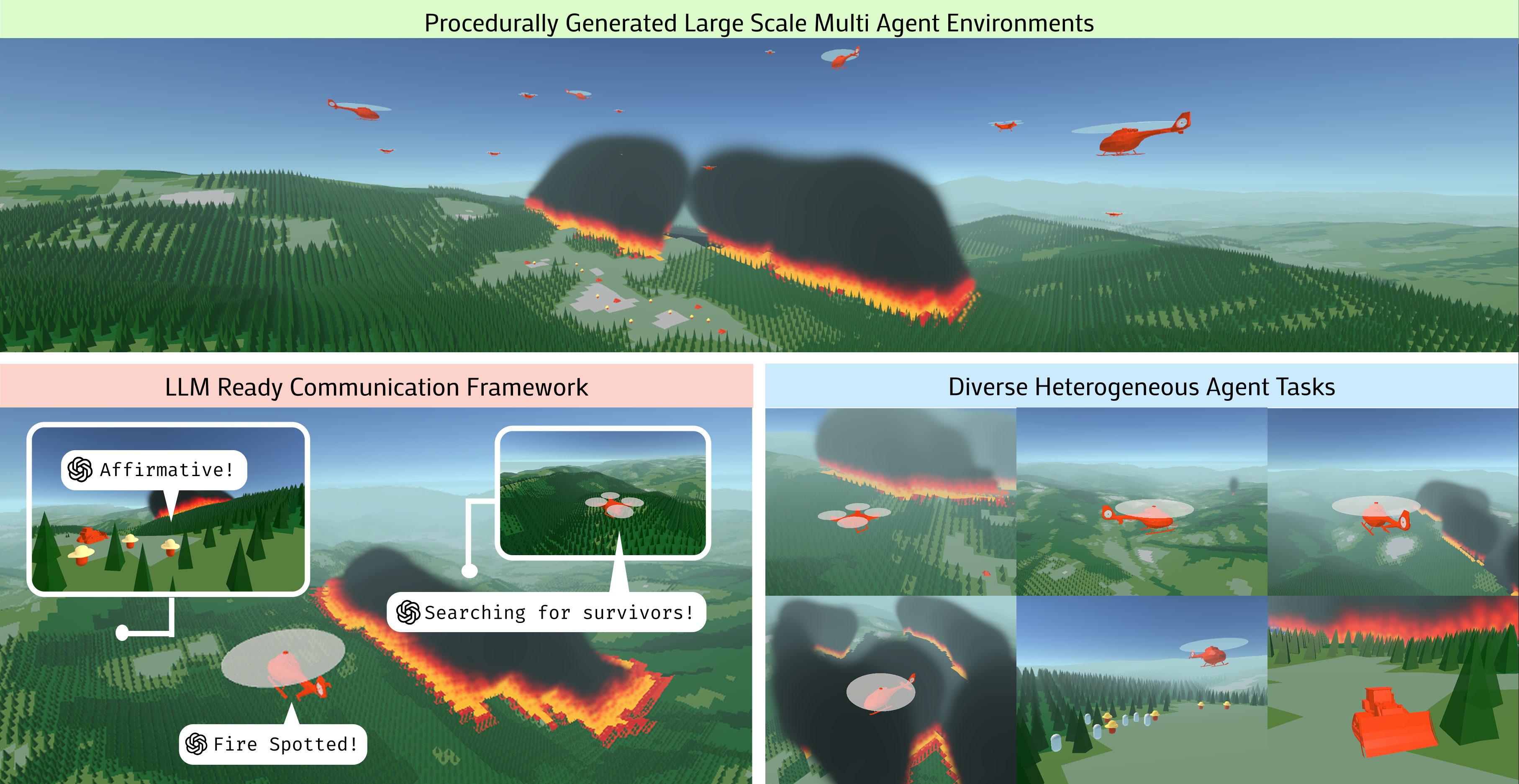
In a wildfire scenario, a drone might spot a fire spread that ground crews cannot see. In current systems, the drone often fails to effectively communicate this spatial information to guide a bulldozer to cut a firebreak in time, leading to mission failure due to lack of coordination.
Key Novelty
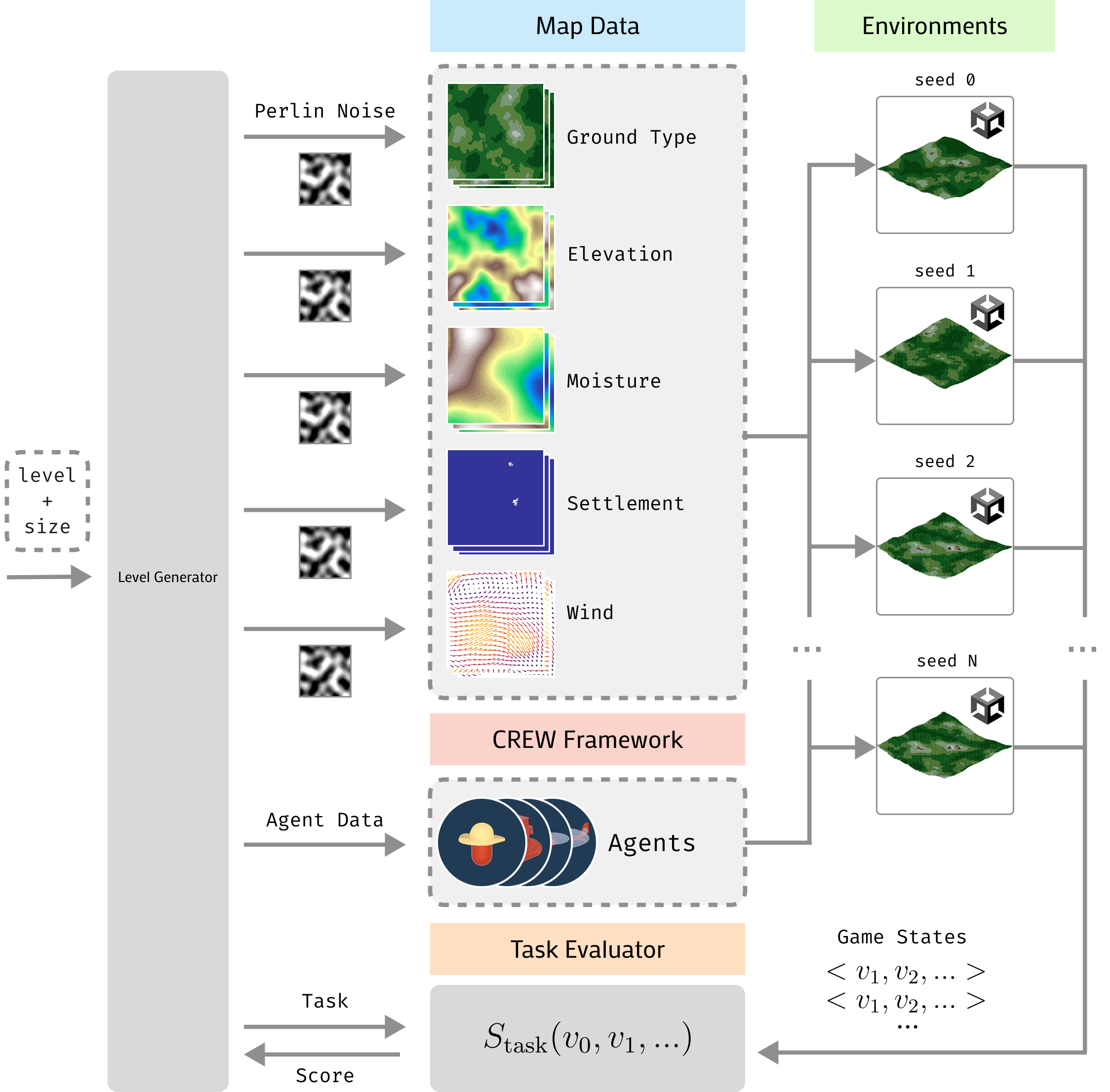
Procedurally Generated Multi-Agent Wildfire Benchmark (CREW-Wildfire)
- Simulates realistic wildfire dynamics (wind, slope, moisture) with heterogeneous agents (Firefighters, Bulldozers, Drones, Helicopters) that have distinct, complementary capabilities
- Integrates Perception and Execution modules to bridge high-level LLM reasoning with low-level simulation control, allowing agents to 'see' via text summaries and 'act' via code
- Supports massive scale (2000+ agents, 1M+ grid cells) to test scalability limits of agentic frameworks
Architecture
The CREW-Wildfire system architecture bridging the Unity simulation with Agentic LLMs.
Evaluation Highlights
- Benchmarked multiple state-of-the-art LLM frameworks (e.g., hierarchical, consensus-based) revealing significant failures in spatial reasoning and real-time coordination
- Demonstrated scalability up to 2000 agents and 1 million map cells on a single consumer desktop (16GB GPU/RAM)
- Established that while emergent collaboration appears in simple tasks, current agents struggle with objective prioritization and plan adaptation under uncertainty
Breakthrough Assessment
8/10
Fills a critical gap for physically grounded, scalable multi-agent LLM benchmarks. The integration of low-level simulation with high-level agentic interfaces is robust and timely.