📝 Paper Summary
Agentic system design
Tool selection and discovery
The paper formulates agent composition as an online knapsack problem, using a composer agent to dynamically test and select components that maximize utility within a budget.
Core Problem
Selecting optimal tools or sub-agents from large inventories is difficult because static descriptions rarely match real-world performance, and traditional retrieval ignores cost-utility trade-offs.
Why it matters:
- Developers face a 'paradox of choice' with combinatorial explosions of possible agent/tool configurations
- Static retrieval methods fail when capability descriptions are opaque or when task requirements shift unpredictably
- Selecting components without considering budget constraints leads to inefficient, high-cost systems
Concrete Example:
When composing an information-seeking agent, a static retriever might select a specialized scientific search tool based on metadata. However, dynamic testing might reveal that a cheaper, generalized web search tool handles the specific queries equally well, or conversely, that the specialized tool is strictly necessary for medical queries despite the cost.
Key Novelty
Composer Agent with Online Knapsack Optimization
- Formalizes component selection as a Knapsack problem: maximizing success probability (value) subject to a budget (weight)
- Introduces an 'Online Knapsack Composer' that iteratively tests components in a sandbox environment to estimate their true 'value' (utility) in real-time rather than relying on static embeddings
- Uses the ZCL algorithm to make dynamic accept/reject decisions for components based on their empirically determined value-to-cost ratio
Architecture
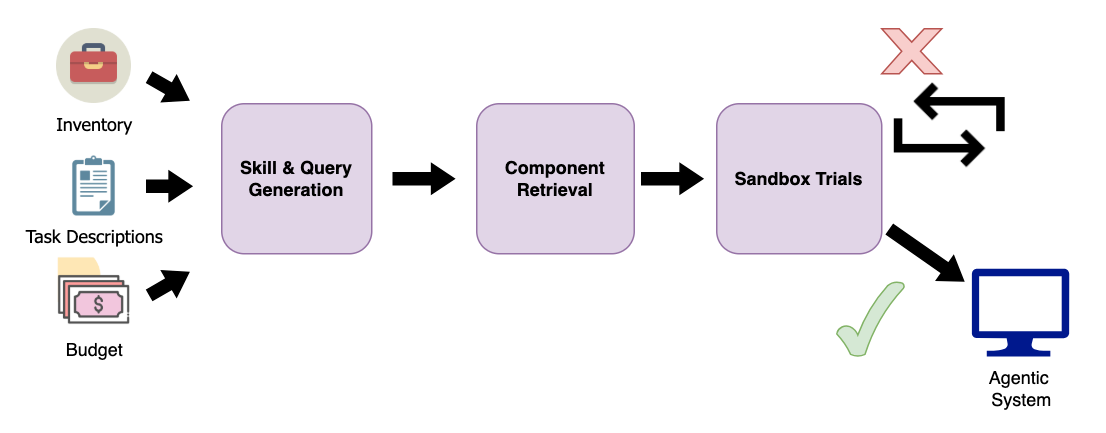
The workflow of the Online Knapsack Composer.
Evaluation Highlights
- Increases multi-agent success rate from 37% to 87% when selecting from an inventory of 100+ agents (compared to baseline performance)
- Achieves up to 31.6% success rate improvement in single-agent setups compared to retrieval baselines
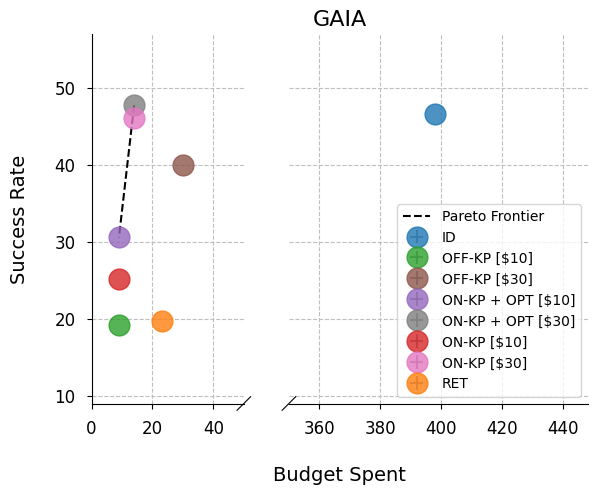
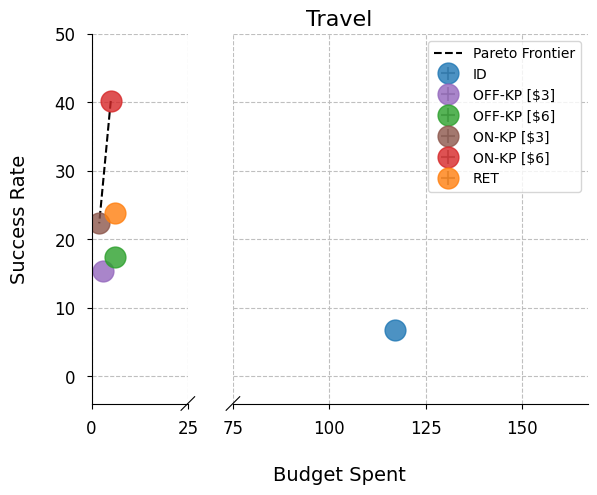
- Demonstrates up to 80% cost-adjusted performance gains over retrieval-based baselines, consistently lying on the Pareto frontier
Breakthrough Assessment
8/10
Novel application of classical operations research (Online Knapsack) to agentic engineering. The shift from static retrieval to dynamic sandboxing for value estimation addresses a fundamental reliability bottleneck in agent composition.