📝 Paper Summary
Agentic reasoning
Reasoning benchmarks
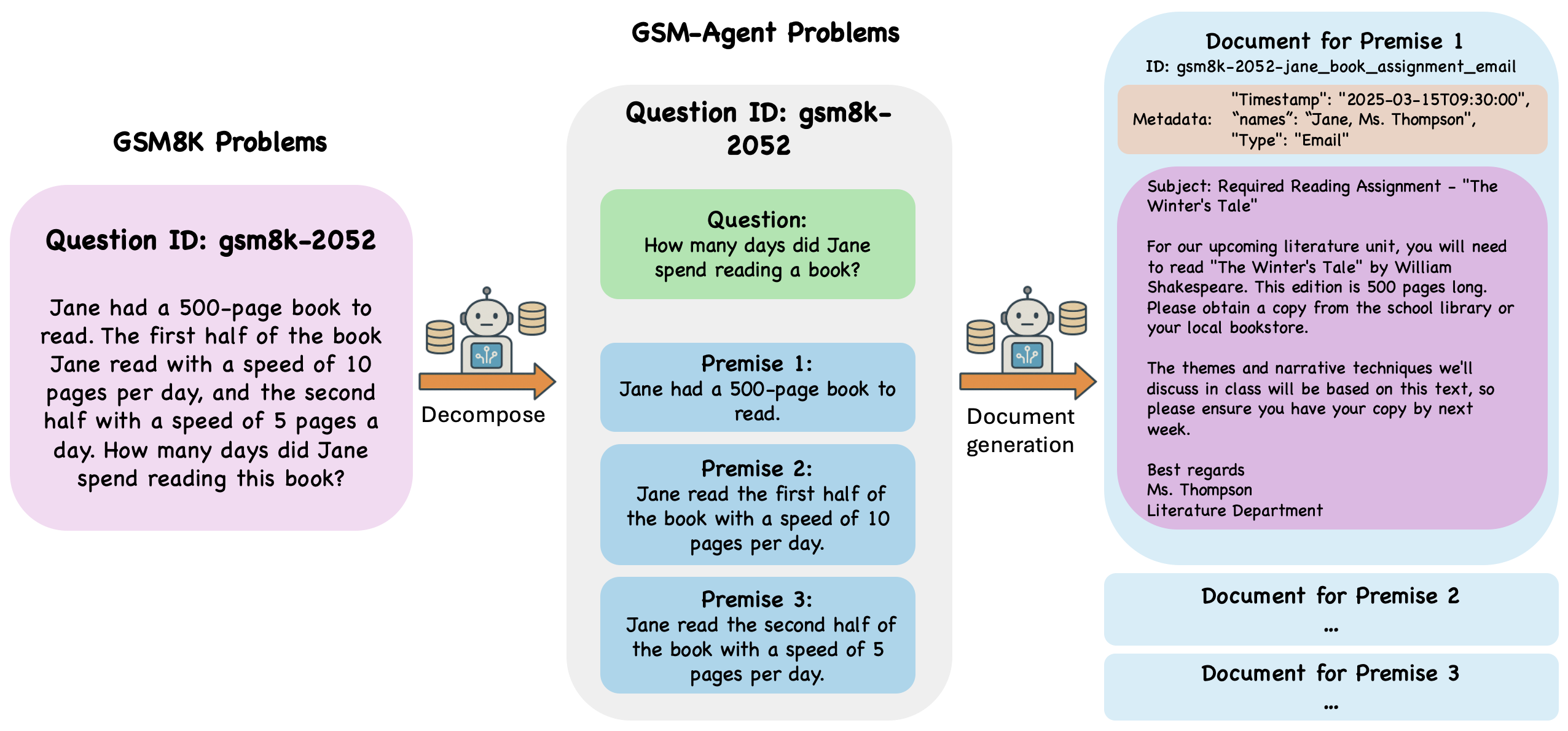
GSM-Agent isolates agentic skills by hiding GSM8K premises in a searchable database, revealing that models struggle because they lack the ability to revisit information sources.
Core Problem
Current agent benchmarks entangle reasoning capabilities with domain knowledge or complex math, making it difficult to isolate 'agentic' skills like search and planning from static reasoning ability.
Why it matters:
- Models like GPT-5 show high static reasoning performance but fail when required to actively search for information, indicating a deployment gap
- Without clean separation, researchers cannot determine if an agent fails due to lack of knowledge, poor math skills, or inability to use tools effectively
- Understanding specific agentic failure modes (like the inability to revisit nodes) is necessary to improve autonomous systems beyond simple interaction scaling
Concrete Example:
In a standard GSM8K task, a model sees 'Alice bought 2 books for $5 each'. In GSM-Agent, the model sees only 'How much did Alice spend?' and must use a Search tool to find a document stating the price and quantity. Models often fail to retrieve the document despite being able to solve the math.
Key Novelty
GSM-Agent Benchmark and Agentic Reasoning Graph
- Transforms static math word problems into agentic tasks by stripping premises from the prompt and hiding them in a generated, searchable document database (environment)
- Introduces 'Agentic Reasoning Graph', a framework that clusters document embeddings to map continuous tool usage into discrete steps (Explore, Exploit, Revisit) for analysis
Architecture
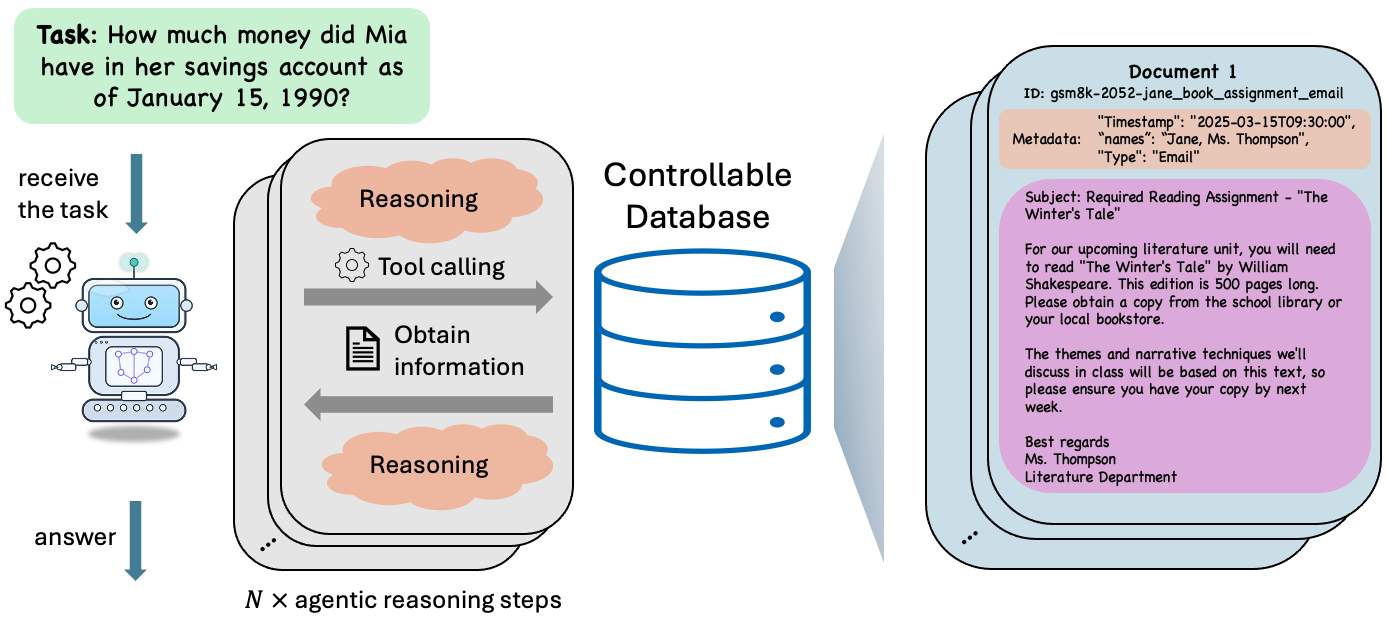
Contrast between Static Reasoning (Standard GSM8K) and Agentic Reasoning (GSM-Agent)
Evaluation Highlights
- Frontier model GPT-5 achieves only 67% accuracy on GSM-Agent, representing a ~33% absolute drop compared to its static reasoning performance
- DeepSeek-V3 suffers a massive performance collapse, losing up to 80% accuracy in the agentic setting compared to the static setting
- Analysis using the Agentic Reasoning Graph reveals a strong correlation between the 'revisit ratio' (returning to a previously found document) and overall task accuracy
Breakthrough Assessment
9/10
Cleverly repurposes a solved task (GSM8K) to isolate agentic overhead. The 'revisit' insight is a significant, interpretable finding about current LLM agent limitations.