📊 Experiments & Results
Evaluation Setup
Generation of a synthetic dataset representing California population demographics (Age and Ethnicity distributions).
Benchmarks:
- California Demographics Case Study (Synthetic Data Generation) [New]
Metrics:
- Visual inspection of distribution plots (Qualitative fidelity)
- Implicit: Computational cost (Number of LLM calls)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| The method is evaluated primarily through qualitative comparison of generated distributions against ground truth Census data. | ||||
| California Demographics | LLM Queries (for N rows) | 30000 | 7 | -29993 |
Experiment Figures
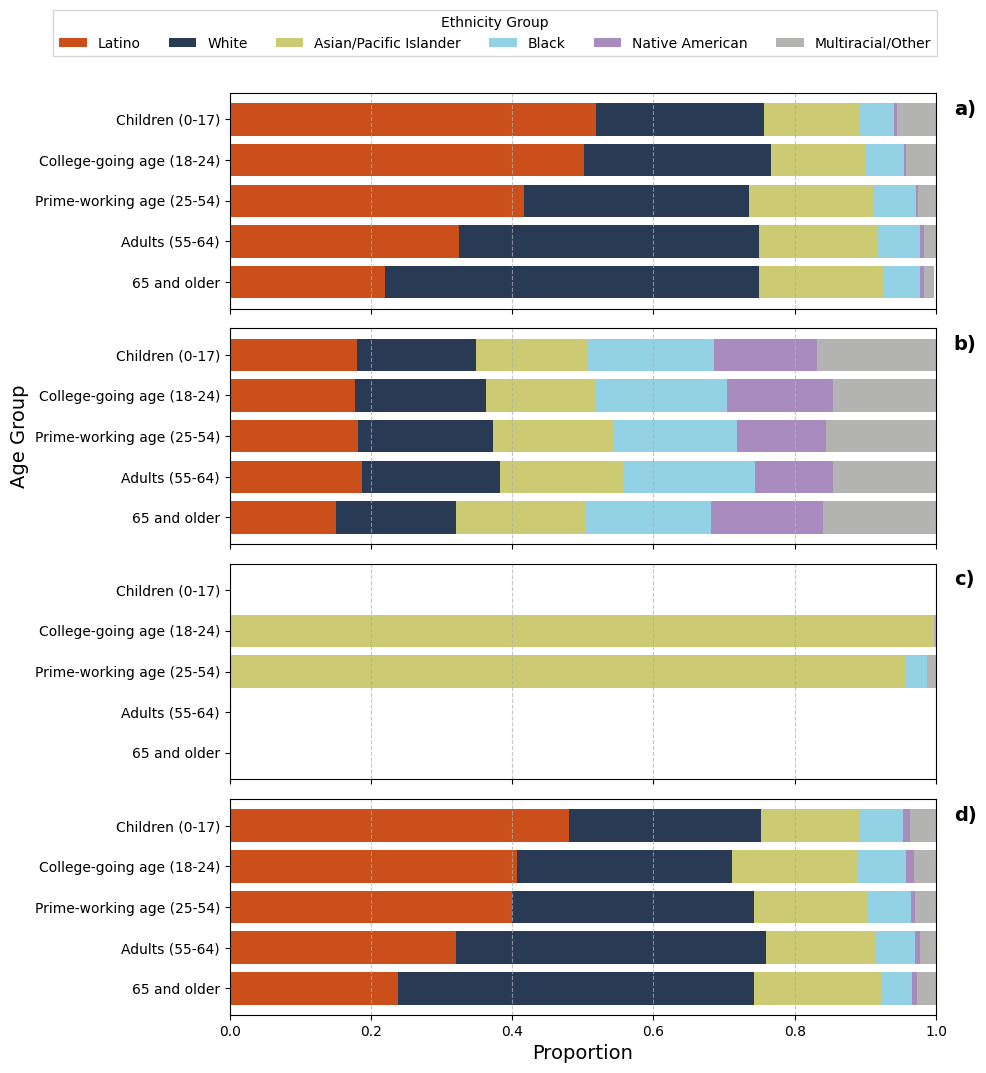
Comparison of Age vs. Ethnicity distributions for Ground Truth, Table-wide prompting, Cell-by-cell prompting, and Probability-driven prompting.
Main Takeaways
- Probability-driven prompting successfully captures complex conditional dependencies (e.g., Ethnicity changes with Age), which cell-by-cell generation failed to capture completely
- The method decouples generation cost from dataset size; generating 1 million rows costs the same in LLM tokens as generating 100 rows, making it highly scalable
- Table-wide prompting suffers from 'over-smoothing', producing variance that is too low compared to real data, while probability-driven prompting allows for controlled variance via sampling