📝 Paper Summary
Agentic AI
Multi-Agent Systems
Synthetic Data Generation
Reasoning LLMs
This survey organizes Agentic LLMs into a reasoning-acting-interacting taxonomy and posits that agent interactions generate new empirical data to overcome the training data plateau.
Core Problem
Standard LLMs are hitting performance plateaus due to the exhaustion of high-quality static training data, while also suffering from hallucination and limited multi-step reasoning capabilities.
Why it matters:
- Training data scarcity: Scaling laws are failing as models run out of new human-generated text to learn from (the 'data wall')
- Static models lack grounding: Traditional LLMs cannot verify facts against the real world or update their knowledge after the training cutoff
- Complex task failure: Without agentic loops (reasoning/acting), models fail at tasks requiring planning, tool use, or long-term coherence
Concrete Example:
In math word problems (e.g., 'Annie has a pie cut into twelve pieces...'), a standard LLM often guesses an incorrect number immediately. An Agentic LLM uses Chain-of-Thought reasoning to break the problem into steps or calls a calculator tool to perform the arithmetic, deriving the correct answer through an autonomous process.
Key Novelty
The Reasoning–Acting–Interacting Taxonomy & Data Flywheel
- Proposes a three-layered categorization: Reasoning (internal cognitive optimization), Acting (external tool use and robotics), and Interacting (multi-agent social simulation)
- Identifies a 'virtuous circle' where agents interacting with the world generate novel trajectories (experience data) that can be filtered and used to train the next generation of models, solving the data scarcity crisis
Architecture
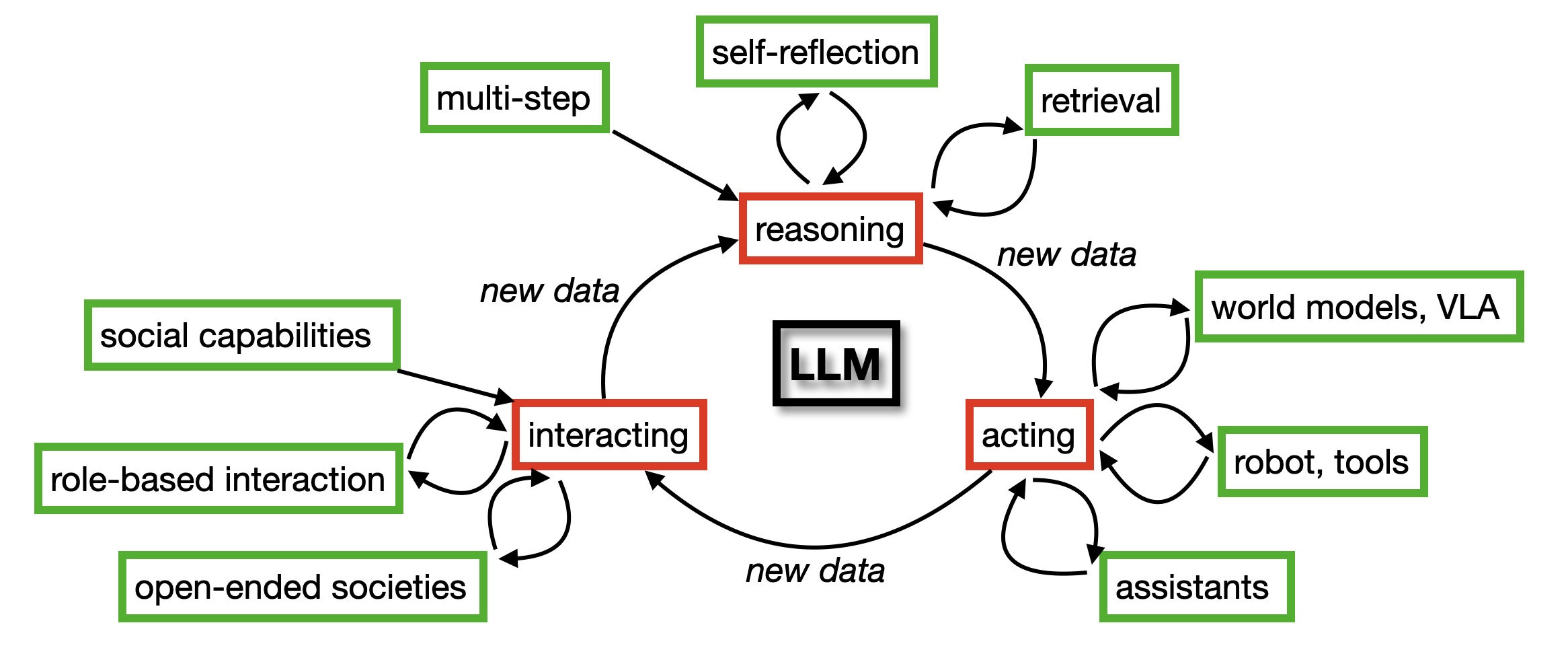
The 'Virtuous Circle' of Agentic LLMs, illustrating how agent interaction feeds back into model training
Breakthrough Assessment
7/10
A comprehensive survey that timely synthesizes the shift from static LLMs to active agents, offering a clear taxonomy and a compelling argument for agents as data generators.