📝 Paper Summary
Model-native Agentic AI
Agentic Planning, Tool Use, and Memory
Reinforcement Learning for Agents
Agentic AI is shifting from brittle, externally engineered pipelines to model-native systems where planning, tool use, and memory are internalized behaviors learned through end-to-end reinforcement learning.
Core Problem
Pipeline-based agents rely on rigid, handcrafted workflows and external modules (e.g., separate planners, retrievers) that make systems brittle, hard to scale, and unable to adapt to dynamic environments.
Why it matters:
- External pipelines treat the LLM as a passive tool rather than a proactive decision-maker, limiting autonomy
- Pre-scripted execution logic fails when agents face unforeseen circumstances or changing interface states (non-stationarity)
- Step-by-step supervision for complex agentic tasks is prohibitively expensive to annotate compared to outcome-driven learning
Concrete Example:
In a pipeline-based GUI agent like AppAgent, the workflow is orchestrated by fixed XML view-hierarchy parsing. If the UI layout changes unexpectedly (e.g., a pop-up appears that isn't in the script), the rigid pipeline fails because the model hasn't learned to perceive and adapt to the new state autonomously.
Key Novelty
The Model-Native Agent Paradigm (LLM + RL + Task)
- Reframes the agent as a single unified model that learns capabilities (planning, tool use, memory) as intrinsic parameters rather than using external modules
- Uses outcome-driven Reinforcement Learning (RL) to train models to explore and discover strategies (like 'thinking' or tool invocation) without needing expensive step-by-step human labels
Architecture
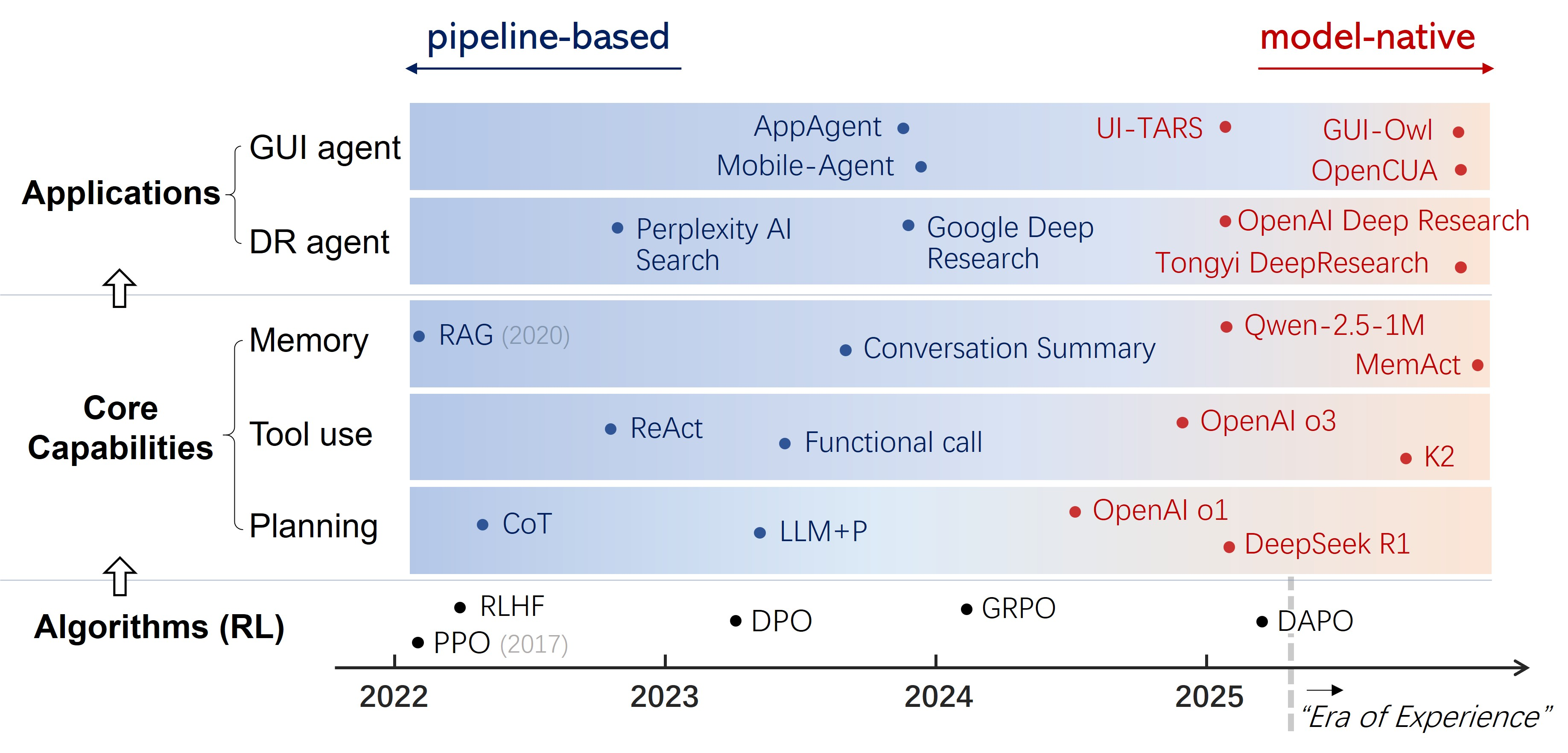
The paradigm shift from Pipeline-based to Model-native Agentic AI, contextualized by the evolution of RL algorithms.
Evaluation Highlights
- DeepSeek-R1 demonstrates that outcome-based RL is sufficient to train reasoning and planning behaviors without step-by-step supervision
- OpenAI's o3 model internalizes tool use into the reasoning process, learning when to invoke tools as part of its policy rather than via external prompts
- Tongyi DeepResearch model executes complex, multi-step research tasks in dynamic web environments by internalizing the research strategy
Breakthrough Assessment
9/10
Captures a fundamental shift in the field. The transition from 'engineering flows' to 'training flows' via RL represents the next major phase of agentic AI scaling.