📝 Paper Summary
Memory recall
Dense memory QA
ReQAP decomposes complex personal questions into recursive operator trees that combine SQL-like logic with neural extraction, enabling private, on-device answering over heterogeneous structured and unstructured data.
Core Problem
Personal data is heterogeneous (tables, text, logs) and massive (>100K tokens), making standard RAG fail on context limits and aggregations, while Text-to-SQL fails on unstructured text.
Why it matters:
- Privacy requirements demand local processing on user devices, ruling out massive cloud-based LLMs for full context processing
- Users need analytical answers (e.g., 'how often did I eat Italian after football?') which require joining structured logs (workouts) with unstructured text (social media) and precise aggregation
- Current approaches force a tradeoff: verbalization (RAG) handles text but fails at aggregation; translation (Text-to-SQL) handles aggregation but fails on unstructured text
Concrete Example:
For the question 'How often did I eat Italian food after playing football?', a standard SQL generator fails because 'Italian food' might only appear as 'pizza' in a text email body, while 'playing football' might be a calendar entry. ReQAP generates a tree that retrieves candidate events, extracts 'cuisine' from email text using a small LM, and then joins/counts the results.
Key Novelty
Recursive Question Understanding and Decomposition (ReQAP)
- Recursive Decomposition: Instead of generating a full query at once, the model recursively breaks a complex question into an operator and a simpler sub-question, refining the tree step-by-step
- Hybrid Operators: Introduces `RETRIEVE` (high-recall retrieval with cascade pruning) and `EXTRACT` (using small LMs to dynamically populate virtual columns from text) to bridge structured and unstructured data
- Distillation for On-Device Use: Uses In-Context Learning (ICL) on large models to generate training data, then distills this into small (1B-7B) local models that can execute the logic privatively
Architecture
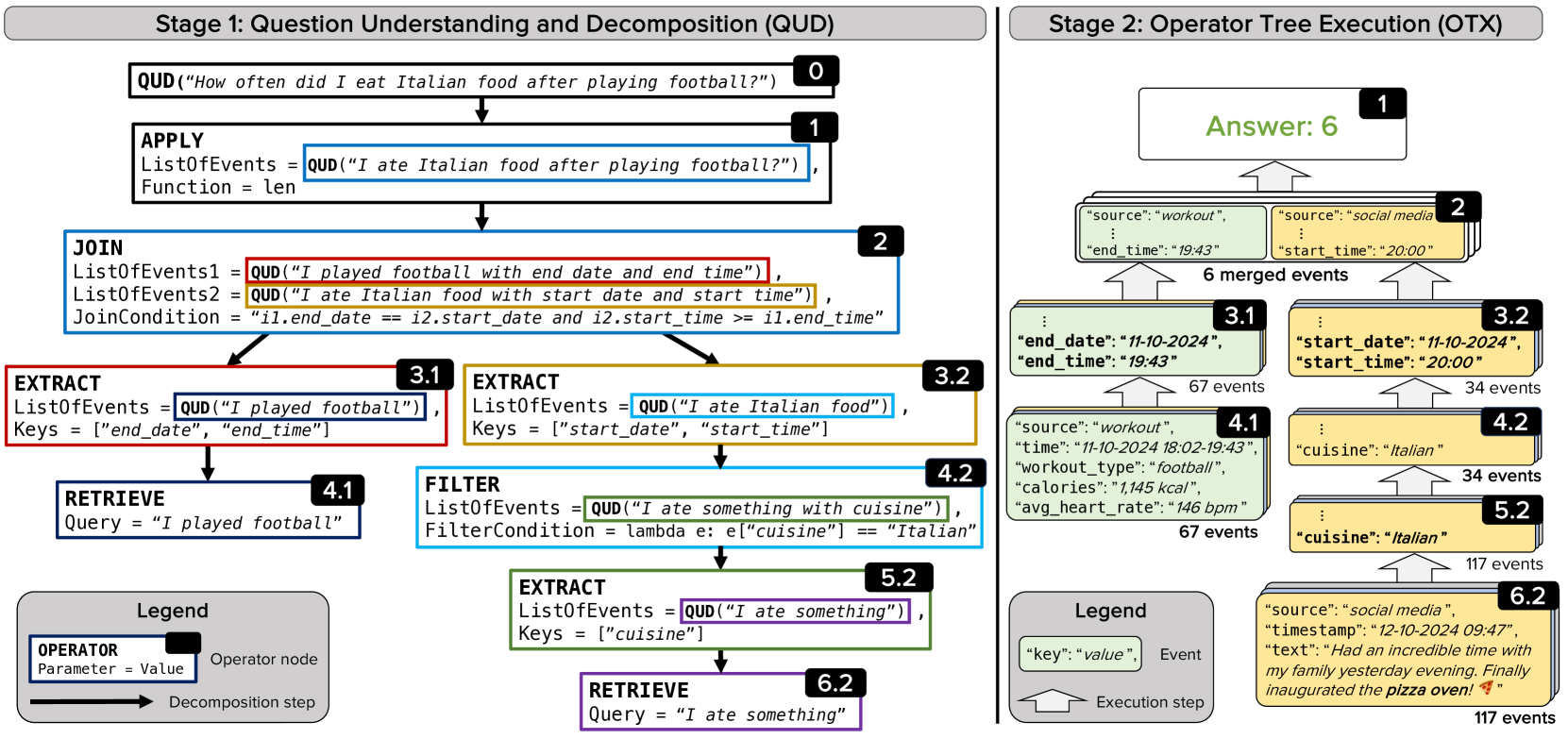
The two-stage process of ReQAP: (1) Question Understanding & Decomposition (QUD) generating the tree, and (2) Operator Tree Execution (OTX) processing the data.
Evaluation Highlights
- PerQA benchmark: Constructed a new dataset with 3,500 complex questions and >40,000 events per persona to test analytical reasoning
- ReQAP outperforms standard Text-to-SQL baselines significantly on complex aggregation tasks involving unstructured text (specific numbers not in snippet, but qualitative dominance emphasized)
- Efficiency: The pruning pipeline in `RETRIEVE` enables scanning massive personal archives by eliminating irrelevant sources (e.g., music streams) early
Breakthrough Assessment
8/10
Strong contribution to privacy-preserving personal QA. The recursive decomposition and hybrid operator tree elegantly solve the structured/unstructured gap that plagues standard RAG and Text-to-SQL.