📝 Paper Summary
Agentic RAG pipeline
AutoRefine trains LLMs via reinforcement learning to autonomously search, explicitly refine noisy documents into key facts, and reason over that refined knowledge to answer complex questions.
Core Problem
Existing retrieval-augmented reasoning methods often reason directly over raw, noisy documents, getting distracted by irrelevant details, and lack direct supervision for improving the retrieval process itself.
Why it matters:
- Distractions in early reasoning steps can derail the entire chain in multi-hop scenarios (e.g., confusing two people with similar names).
- Outcome-only rewards (final answer correctness) provide insufficient signal for the model to learn *how* to search effectively or filter information.
- LLMs struggle with out-of-scope questions requiring precise, up-to-date factual details without explicit refinement.
Concrete Example:
When asking 'Who is the subject of the painting The Umbrellas?', a standard model might retrieve a long document about the painting's style and get distracted. AutoRefine explicitly extracts 'The Umbrellas... depicts... Pierre-Auguste Renoir's' in a refinement step, ignoring the noise to answer correctly.
Key Novelty
Search-and-Refine-during-Think Paradigm
- Introduces an explicit '<refine>' step between search and reasoning, forcing the model to distill key facts from noisy documents before using them.
- Uses Group Relative Policy Optimization (GRPO) with a dual reward system: one for the final answer and a specific 'retrieval reward' that validates the quality of the refined text.
- Allows the model to autonomously determine when to search, refine, and answer, rather than following a fixed chain.
Architecture
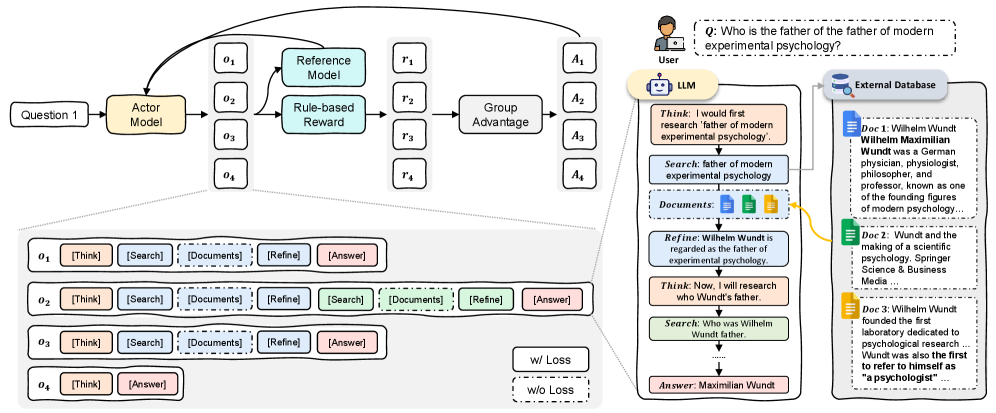
The AutoRefine framework training and inference process.
Evaluation Highlights
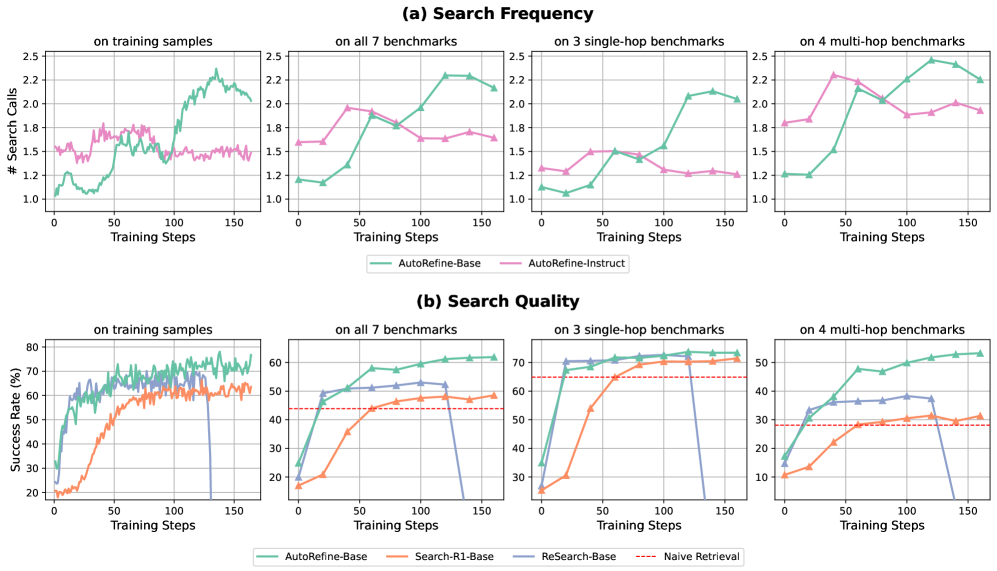
- +6.9% higher average accuracy over leading baselines (Search-R1, Search-o1) across seven QA benchmarks.
- +8.3% accuracy improvement on the 2WikiMultihopQA benchmark compared to the strongest baseline.
- Search quality (retrieving documents containing the answer) surpasses baselines by 10-15% on multi-hop tasks.
Breakthrough Assessment
8/10
Significant performance gains on complex multi-hop tasks by successfully integrating an explicit refinement step into the RL reasoning loop. Effectively addresses the noise problem in RAG.