📝 Paper Summary
Video Question Answering (VideoQA)
Symbolic Grounding
Neuro-symbolic AI
SG-VLM enhances frozen Vision Language Models by generating and selecting symbolic scene graphs as intermediate reasoning steps to improve causal and temporal grounding in video QA.
Core Problem
Vision Language Models (VLMs) often rely on shallow correlations for VideoQA, leading to hallucinations and poor performance on tasks requiring multi-step temporal or causal reasoning.
Why it matters:
- Current VLMs lack structural transparency and struggle to explicitly model object-centric interactions essential for complex questions.
- Existing neuro-symbolic methods often require training separate heavy models or external tracking pipelines, making them computationally expensive and inflexible.
- Long videos contain noise that distracts end-to-end models; intermediate grounding is needed to decompose reasoning.
Concrete Example:
For a question 'Why does the brown cat watch the other cat?', a standard VLM might halluncinate based on background pixels. SG-VLM generates a graph containing (orange cat, watching, tabby cat) and (tabby cat, eating, food), enabling the answer 'waiting for its turn' by explicitly grounding the causal link.
Key Novelty
Modular Symbolic Scene Graph Grounding via Prompting
- Uses frozen VLMs to generate scene graphs (objects + relations) via prompting, rather than training specialized graph generation networks.
- Introduces a query-aware selection mechanism that filters scene graphs to only those relevant to the question, reducing noise from irrelevant frames.
- Systematically evaluates four integration strategies (Full, Selection, Temporal Extension, Summary) to determine how symbolic data best aids VLMs.
Architecture
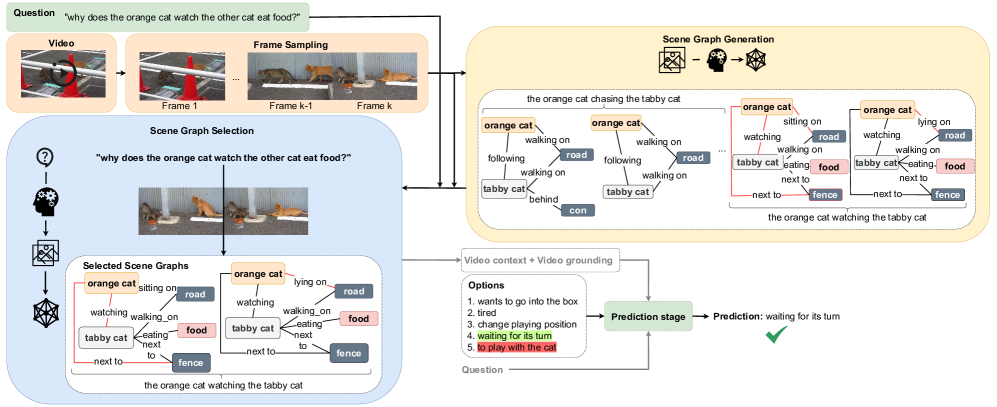
The 3-stage pipeline: (1) Scene Graph Generation via prompting, (2) Query-Aware Selection, (3) Grounded Answer Generation.
Evaluation Highlights
- Surpasses ViperGPT baseline by +23.6% on NExT-QA (Temporal/Causal) using InternVL-14B backbone.
- Achieves 76.9% accuracy on iVQA with InternVL-14B, significantly outperforming InstructBLIP (53.8%).
- Outperforms strong end-to-end baselines like SeViLA and Flamingo on causal reasoning benchmarks, though gains over very large VLMs (Qwen-32B) are sometimes limited.
Breakthrough Assessment
7/10
Solid systematic study of symbolic grounding for modern VLMs. Shows strong improvements on specific reasoning types (causal/temporal) but acknowledges limitations where end-to-end VLMs are already strong.